| Poster | Thread |
 Hammer Hammer
 |  |
Re: Amiga SIMD unit
Posted on 24-Aug-2020 4:01:42
| | [ #41 ] |
|
|
 |
Elite Member
 |
Joined: 9-Mar-2003
Posts: 5286
From: Australia | | |
|
| @matthey
For 68090, I prefer to see out-of-order dual pipeline 68882 FPUs just as AMD ZEN 2 has dual 256bit FADD AVX and dual 256-bit FMAC AVX 2.
Adding MMX to 68K is nearly pointless when existing Amiga 68K software doesn't use MMX.
For modern X86 CPU, the SIMD instruction set doesn't show actual hardware implementation when CPUs like Intel Haswell has dual 256-bit AVX 2 units. Last edited by Hammer on 24-Aug-2020 at 04:04 AM.
_________________
Ryzen 9 7900X, DDR5-6000 64 GB RAM, GeForce RTX 4080 16 GB
Amiga 1200 (Rev 1D1, KS 3.2, PiStorm32lite/RPi 4B 4GB/Emu68)
Amiga 500 (Rev 6A, KS 3.2, PiStorm/RPi 3a/Emu68) |
|
| Status: Offline |
|
|
Hammer
| |
Re: Amiga SIMD unit
Posted on 24-Aug-2020 4:17:40
| | [ #42 ] |
|
|
|
Elite Member
|
Joined: 9-Mar-2003
Posts: 5286
From: Australia | | |
|
| @Fl@sh
Quote:
Fl@sh wrote:
@matthey
IMHO optimal simd is a 256bit wide one with at least 16 dedicated registers and support until to float128 datatype, based on latest IBM power ISA implementation.
On embedded socks simply will be removed all optimisations due register renaming and other tricks to make all low power and reduced complexity.
Its important to have the same instruction sets for all the same cpu line, limiting only performances among the lowest and highest cpu cores,
A great mistake of all chipmakers is to have different isa for the same architecture.
Current power implementation is the best possible high performance isa, ready for future..
x86, looking at next 10/15 years, is dead just as mc68k was 15 years ago.
Future is ARM, RISC V and IBM Power, simply because theyre best performers for low power and/or high compute tasks.
X86 is closed and totally controlled by intel and AMD, it lacks of security and Most probably have USA government backdoors .
..Just like huawei did for its hisilicon cpu line and 5g infrastructures.
My2cents
|
There many false prophets who predicted X86's demise.
You condemned X86 when Power CPUs are used by the US government which amounts to hypocrisy.
https://www.zdnet.com/article/arm-cpus-impacted-by-rare-side-channel-attack/
ARM CPUs impacted by side-channel attacks. LOL. Smartphones such as 1st generation Pixel phones will not receive OS updates from Google. hypocrisy!
I have thrown more Vulkan enabled ARM-based smartphones in the bin when compared to Vulkan enabled X86 PCs. Hint: Google withdraws OS support. LOL. hypocrisy!
Google has its own monopolistic practices e.g. https://www.androidcentral.com/google-stopped-oneplus-pre-installing-fortnite-its-phones hypocrisy!
Hypocrites.
Last edited by Hammer on 24-Aug-2020 at 04:51 AM.
Last edited by Hammer on 24-Aug-2020 at 04:19 AM.
_________________
Ryzen 9 7900X, DDR5-6000 64 GB RAM, GeForce RTX 4080 16 GB
Amiga 1200 (Rev 1D1, KS 3.2, PiStorm32lite/RPi 4B 4GB/Emu68)
Amiga 500 (Rev 6A, KS 3.2, PiStorm/RPi 3a/Emu68) |
|
| Status: Offline |
|
|
Hammer
| |
Re: Amiga SIMD unit
Posted on 24-Aug-2020 4:31:12
| | [ #43 ] |
|
|
|
Elite Member
|
Joined: 9-Mar-2003
Posts: 5286
From: Australia | | |
|
| @matthey
Quote:
matthey wrote:
Many APUs do *not* support a Heterogeneous System Architecture (HSA) so have to copy data to and from GPU memory. Only the Playstation 4 AMD SoC, AMD "Kaveri" A-series APU and ARM's Mali-G71 GPU support HSA that I'm aware of. It's a game changer as far as using the GPU to do parallel processing. See the article I linked above about the PS4 to see how important it was to that project (HSA advantages are about half the long article). HSA hardware is likely the future but requires standard hardware in an integrated SoC like a console and like the Amiga could be to take full advantage.
Many modern GPU processors have become more flexible and general purpose. Unified shader model GPUs use a universal shader processor for all shading (vertex, pixel, geometry, etc.). They support integer datatypes pretty well including integer vector support in some cases. Even some older GPUs can be programmed in C like languages and support an OS. For example, the Raspberry Pi VideoCore IV has a vbcc backend and the ThreadX RTOS is used to manage the board (not just the GPU). Most integer datatypes use saturation math which can keep them from being conformant with older language standards and compatible with many OSs.
|
Xbox One's APU is also HSA capable and enabled. Furthermore, XBO's CPU-GPU fusion links (~30 GB/s) is slightly faster than PS4's (~20 GB/s).
PS5 APU replaces PS4 Pro APU.
XSX APU replaces XBO X APU.
Mesh shaders have replaced discrete geometry related shaders e.g. hull, domain, vertex, and 'etc'.
Note that, near direct PS4 ported games such as Horizon Dawn on PC has shown PCI-E 16X version 3.0 advantages over lesser PCI-E configurations.
The baseline interconnects and storage technologies for gaming PC during Xbox Series X and PS5 era is PCI-E version 4.0.
Last edited by Hammer on 24-Aug-2020 at 04:39 AM.
_________________
Ryzen 9 7900X, DDR5-6000 64 GB RAM, GeForce RTX 4080 16 GB
Amiga 1200 (Rev 1D1, KS 3.2, PiStorm32lite/RPi 4B 4GB/Emu68)
Amiga 500 (Rev 6A, KS 3.2, PiStorm/RPi 3a/Emu68) |
|
| Status: Offline |
|
|
Hammer
| |
Re: Amiga SIMD unit
Posted on 24-Aug-2020 4:44:38
| | [ #44 ] |
|
|
|
Elite Member
|
Joined: 9-Mar-2003
Posts: 5286
From: Australia | | |
|
| @matthey
Quote:
matthey wrote:
Quote:
Lou wrote:
Eh? You proved why it should be on a GPU and accessible via an API.
All gpus today are GPgpus. Moving such functions to a separate chip and hitting it via an api allows you to keep more backwards compatibility over time since "our" cpu would just be a faster 68k without introducing un-necessary complexities and incompatibilities.
|
Let's take a closer look at how GPU shaders on a gfx card are typically used for parallel processing of data on the CPU side.
1) An intermediate language program is compiled (usually with LLVM) into a program for the GPU shaders.
2) The program and data are copied to gfx memory.
3) The CPU and/or GPU must distribute the program to shaders and start executing.
4) The GPU may be able to signal the CPU when done or the CPU has to poll the GPU until done.
5) Resulting data is copied back to CPU memory.
This process is very inefficient, has huge latency and wastes memory. With HSA as AMD proposes we would reduce this to the following steps.
1) An intermediate language program is compiled (usually with LLVM) into a program for the GPU shaders.
2) The CPU copies the program into a queue and the shaders begin executing.
3) The GPU signals the CPU when done or the CPU has to poll the GPU until done.
Much simpler. Step 1 could be eliminated if we always used the same GPU hardware but then we would be limited how much we could change the shader ISA and maintain compatibility.
|
On PS4/PS5 and XBO/XSX game consoles, GPU game code is directly consumed by the GPU without LLVM stage.
On PC gaming, AMD enables direct GPU access
https://www.youtube.com/watch?v=P7RSszCPt68
Games such as Horizon Dawn on PC, pre-complies shader code for the user's GPU before starting the game at the 1st runtime or after GPU driver update. Some games or monthly driver "game ready" updates include pre-complies shader code for the targeted games.
Last edited by Hammer on 24-Aug-2020 at 04:50 AM.
Last edited by Hammer on 24-Aug-2020 at 04:45 AM.
_________________
Ryzen 9 7900X, DDR5-6000 64 GB RAM, GeForce RTX 4080 16 GB
Amiga 1200 (Rev 1D1, KS 3.2, PiStorm32lite/RPi 4B 4GB/Emu68)
Amiga 500 (Rev 6A, KS 3.2, PiStorm/RPi 3a/Emu68) |
|
| Status: Offline |
|
|
Hammer
| |
Re: Amiga SIMD unit
Posted on 24-Aug-2020 5:17:33
| | [ #45 ] |
|
|
|
Elite Member
|
Joined: 9-Mar-2003
Posts: 5286
From: Australia | | |
|
| @Hypex
Quote:
Hypex wrote:
Quote:
| SSE2 is where the x86 SIMD unit started to outperform AltiVec. This is when the number of SSE registers was doubled from 8 to 16. |
Which is still half of 32 in AltiVec. 
|
SSE2 with 16 registers was included with X86-64 update.
Intel AVX-512 has 32 registers e.g. Intel Skylake/CascadeLake/CoffeeLake/Icelake CPUs.
Intel AVX-512 can operate in AVX-128 EVEX or AVX-256 EVEX modes with 32 registers. 512 bit wide SIMD is not a requirement to use 32 registers.
_________________
Ryzen 9 7900X, DDR5-6000 64 GB RAM, GeForce RTX 4080 16 GB
Amiga 1200 (Rev 1D1, KS 3.2, PiStorm32lite/RPi 4B 4GB/Emu68)
Amiga 500 (Rev 6A, KS 3.2, PiStorm/RPi 3a/Emu68) |
|
| Status: Offline |
|
|
matthey
| |
Re: Amiga SIMD unit
Posted on 24-Aug-2020 5:31:20
| | [ #46 ] |
|
|
|
Elite Member
|
Joined: 14-Mar-2007
Posts: 2009
From: Kansas | | |
|
| Quote:
megol wrote:
RMW instructions helps in the case where memory have to be used as variable storage - however that is always a suboptimal situation since at least the 90's. It's slower and wastes a lot of power.
The problem isn't effective address calculation but the other things I listed, things that (generally) can't be avoided especially in a high performance design. Normally requiring two instructions or more for a complex address isn't a problem as in the most common case the heavy work can be done outside the inner loop.
|
The suboptimal RMW instructions of x86_64 with only 16 GP registers must be hurting performance.
The 68060 can execute a RMW instruction like addq.l #1,(a0) in 1 cycle in either integer pipe (best case). By using a "complex" RMW instruction instead of separate "simple" load/read+op/modify+store/write instructions the 68060 gains the following advantages.
1) fewer instructions to decode
2) better utilization of the instruction cache
3) better utilization of the registers (fewer used)
4) more work is done in a shorter amount of time than separate instructions
Even if the RMW instruction is broken apart when decoding, advantages 1-3 above still apply.
Quote:
OoO in combination with wider execution is very powerful to effectively hide L1 and in many cases L2 latency. Looking in the literature of yesterday it's obvious that L1 latency needed to be as low as possible not to tank general performance, however the architectures of today are moving away from that instead having comparatively large L1 caches with longer latency. The difference is deeper OoO and more capable branch prediction.
|
Most OoO RISC designs introduce load-use stalls which delay the use of the load data though other instructions may be able to fill the delay (delay increases with DCache access time). An L1 miss is something like 10-15 cycles which is difficult to hide for all but the most aggressively speculating OoO (that is a lot of non-dependent instructions). Furthermore, deep speculation can end up guessing wrong and loading the wrong data which can't easily be aborted and flushes good data out of the L1 DCache. Core designers do want to increase the cache sizes as caching is so important for performance but they sometimes do realize that pushing the pipeline length with increased branch misprediction penalties, load-use penalties and too large of L1 is counterproductive like with the POWER9 where the pipeline was shortened by 5 cycles and the L1 DCache halved.
Quote:
RMW instructions have some uses but they shouldn't be seen as an alternative to larger register files. They are less power efficient, not as generally useful, and require more transistors to implement efficiently.
|
Do you really think a RMW instruction uses more energy than a separate load+op+store? I'd like to see any documentation you have of that because I doubt it. All active transistors use energy during the 3 cycle load+op+store where RMW they are active for just 1 cycle (this is a simple addressing mode where RISC can take several cycles longer for a more complex EA calc and can stall for several cycles with a load-use penalty even with OoO). The L1 cache is used less with RMW for the same amount of work so can enter a low energy state for longer. More registers are great for calculation intensive algorithms where RISC has a small advantage but RISC has a big disadvantage anytime memory is used (RISC memory fetch is eating mem bandwidth and the larger ICaches use energy too). Look at various disassembled compiler code and see how many instructions there are between a memory access. OoO helps with the RISC performance loss but MIPS/Watt is usually decreased (uses more energy per instruction).
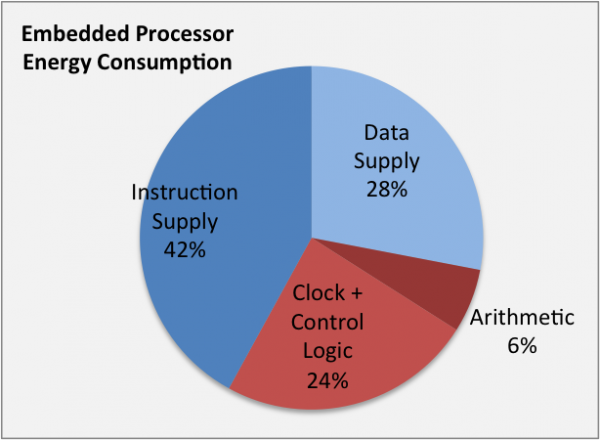
Are you worried about data supply while RISC instruction supply may be using your more energy?
|
|
| Status: Offline |
|
|
matthey
| |
Re: Amiga SIMD unit
Posted on 24-Aug-2020 7:16:42
| | [ #47 ] |
|
|
|
Elite Member
|
Joined: 14-Mar-2007
Posts: 2009
From: Kansas | | |
|
| Quote:
Hammer wrote:
For 68090, I prefer to see out-of-order dual pipeline 68882 FPUs just as AMD ZEN 2 has dual 256bit FADD AVX and dual 256-bit FMAC AVX 2.
Adding MMX to 68K is nearly pointless when existing Amiga 68K software doesn't use MMX.
|
Most 68k software doesn't use the FPU either. It may be possible for a vector unit like in the Libre project to execute 68k FPU instructions and give OoO. It looks like it would be possible to attach the vector unit like the FPU (early stages in int pipe) but it likely requires more technical hardware knowledge than I possess to determine. I'm still trying to understand dynamic vectorization and determine its worth for possible addition in an ISA.
Quote:
For modern X86 CPU, the SIMD instruction set doesn't show actual hardware implementation when CPUs like Intel Haswell has dual 256-bit AVX 2 units.
|
Supporting older narrower SIMD operations is likely just masking. The bigger problem is the instruction proliferation which is out of control for rarely used instructions.
Quote:
Hammer wrote:
Xbox One's APU is also HSA capable and enabled. Furthermore, XBO's CPU-GPU fusion links (~30 GB/s) is slightly faster than PS4's (~20 GB/s).
|
I'm not surprised the Xbox is HSA too. It looks like the AMD fusion compute links are between the GPU and CPU caches to maintain coherency. I wonder how much the difference makes to performance. Using SIMD/vector CPU cores as the shaders would mean these links would be unnecessary for the shaders at least.
Quote:
PS5 APU replaces PS4 Pro APU.
XSX APU replaces XBO X APU.
|
I wouldn't want to compete with these guys. It would be better to go smaller, more energy efficient, cheaper and increase volumes by selling into the embedded market too. Something along the lines of a Raspberry Pi with better gfx/parallel processing but more resource efficient.
Quote:
Mesh shaders have replaced discrete geometry related shaders e.g. hull, domain, vertex, and 'etc'.
|
Does that mean the CPU cores in the HSA consoles are doing the transformation again? Shaders do texturing and lighting?
Quote:
On PS4/PS5 and XBO/XSX game consoles, GPU game code is directly consumed by the GPU without LLVM stage.
|
This is the advantage of standard hardware. The shader code can be precompiled because all the end users have the same GPU. Will console users be able to use the same precompiled shader programs as for the previous generation (are the shader ISAs backward compatible)?
Quote:
Games such as Horizon Dawn on PC, pre-complies shader code for the user's GPU before starting the game at the 1st runtime or after GPU driver update. Some games or monthly driver "game ready" updates include pre-complies shader code for the targeted games.
|
I would think it would be easier to query the gfx card and download the proper precompiled shader programs. Decompression is usually faster than compiling and would allow for more optimized compiled programs.
|
|
| Status: Offline |
|
|
kolla
| |
Re: Amiga SIMD unit
Posted on 24-Aug-2020 9:47:47
| | [ #48 ] |
|
|
 |
Elite Member
|
Joined: 21-Aug-2003
Posts: 2896
From: Trondheim, Norway | | |
|
| @matthey
Quote:
Most 68k software doesn't use the FPU either.
|
Most 68k software also isn't optimized for 68020+, so why don't we just scrap all those pointless 020+ CPUs...
For what it's worth - a LOT of the software that _I_ use, benefit from FPU, but I cannot have an FPU that confuses software with silly rounding errors due to lack of precision.Last edited by kolla on 24-Aug-2020 at 09:49 AM.
_________________
B5D6A1D019D5D45BCC56F4782AC220D8B3E2A6CC |
|
| Status: Offline |
|
|
Hammer
|  |
Re: Amiga SIMD unit
Posted on 24-Aug-2020 14:43:34
| | [ #49 ] |
|
|
|
Elite Member
|
Joined: 9-Mar-2003
Posts: 5286
From: Australia | | |
|
| @matthey
Quote:
Most 68k software doesn't use the FPU either. It may be possible for a vector unit like in the Libre project to execute 68k FPU instructions and give OoO. It looks like it would be possible to attach the vector unit like the FPU (early stages in int pipe) but it likely requires more technical hardware knowledge than I possess to determine. I'm still trying to understand dynamic vectorization and determine its worth for possible addition in an ISA.
|
Unlike AMMX, Amiga 68K has existing software that uses 68881/68882/68060 FPU.
MMX is nearly pointless when AmigaPPC has Altivec/VMX-32 support. New Amiga apps could support MMX but integer datatype has limits. MMX was abandoned for SSE1 which supports both integer and 32bit floating-point formats.
Have you considered Altivec/VMX-32 with 68K CPU combo? I prefer multi-pipeline 68881/68882/68060 FPU.
Quote:
Supporting older narrower SIMD operations is likely just masking. The bigger problem is the instruction proliferation which is out of control for rarely used instructions.
|
Game consoles from Microsoft and Sony have influenced X86 SIMD usage in PC gaming. Both PS5 and XSX have Zen 2 CPU which is quad 256bit pipelined AVX 2 enabled.
Quote:
I'm not surprised the Xbox is HSA too. It looks like the AMD fusion compute links are between the GPU and CPU caches to maintain coherency. I wonder how much the difference makes to performance. Using SIMD/vector CPU cores as the shaders would mean these links would be unnecessary for the shaders at least.
|
Both incoming PS5 and XSX (Xbox Series X) APUs also has powerful audio DSP solution besides the CPUs, raytracing enabled GPUs and real-time compression/decompression I/O co-processors.
AMD's gaming APUs have taken Amiga's custom chip concepts to the max.
Xbox Series X APU's GPU has RTX 2080 level results when playing games such as Gears 5 built-in benchmark which is about 25% higher the PC's RX 5700 XT which relates to 25% memory increase from RX 5700 XT's 448 GB/s to XSX's 560 GB/s.
Fusion HSA conserves memory bandwidth usage when XSX doesn't have desktop PC CPU's discrete memory pool which enables XSX to be cheaper than gaming PC with comparable RTX 2080 GPU.
Quote:
I wouldn't want to compete with these guys. It would be better to go smaller, more energy efficient, cheaper and increase volumes by selling into the embedded market too. Something along the lines of a Raspberry Pi with better gfx/parallel processing but more resource efficient.
|
Well, the Amiga market has been nearly ground zero'ed and needs to be rebuilt from the ground up.
I'm looking at Vampire 2 for my near-mint condition Amiga 1200. :p
Quote:
Does that mean the CPU cores in the HSA consoles are doing the transformation again? Shaders do texturing and lighting?
|
No, discrete hull/domain/geometry/vertex shaders are virtual discrete shader types that runs on CU/SM units. Mesh shaders remove artificial software boundaries from discrete hull/domain/geometry/vertex shaders types.
For mesh shaders, some game programmers commented "welcome PS2" and NVIDIA GeForce lead the entire industry in the wrong path.
Quote:
This is the advantage of standard hardware. The shader code can be precompiled because all the end users have the same GPU. Will console users be able to use the same precompiled shader programs as for the previous generation (are the shader ISAs backward compatible)?
|
PS5's GCN 2.0 backward compatibility with RDNA 2 is a requirement. PS5's 36 CU RDNA 2 config relates to backward compatibility with PS4 Pro's 36 CU and PS4's 18 CU (half of 36 CU).
XBO has an extra DirectX12 microcode engine hardware to feed the GPU i.e. effectively DirectX12 baked into microcode engine hardware. Hit-the-metal GCN access is available for both game consoles.
Quote:
I would think it would be easier to query the gfx card and download the proper precompiled shader programs. Decompression is usually faster than compiling and would allow for more optimized compiled programs.
|
That method can't be trusted when PC GPU drivers are updated e.g. the game can crash when existing compiled shader programs run on updated GPU drivers e.g. Horizon Dawn PC builds one of many bugs, hence the quick fix was to trigger re-compile shader programs step after the driver update.
Your proposed method was used for Xbox One's baseline shader programs vs Xbox One X's updated shader programs. Can be applied for Xbox Series X's RDNA 2 updated shader programs.
Horizon Dawn PC re-compile shader program step heavy uses 14 CPU threads from 24 threads from my Ryzen 9 3900X CPU.
_________________
Ryzen 9 7900X, DDR5-6000 64 GB RAM, GeForce RTX 4080 16 GB
Amiga 1200 (Rev 1D1, KS 3.2, PiStorm32lite/RPi 4B 4GB/Emu68)
Amiga 500 (Rev 6A, KS 3.2, PiStorm/RPi 3a/Emu68) |
|
| Status: Offline |
|
|
matthey
| |
Re: Amiga SIMD unit
Posted on 24-Aug-2020 21:29:10
| | [ #50 ] |
|
|
|
Elite Member
|
Joined: 14-Mar-2007
Posts: 2009
From: Kansas | | |
|
| Quote:
kolla wrote:
Most 68k software also isn't optimized for 68020+, so why don't we just scrap all those pointless 020+ CPUs...
|
I find a quite a bit of Amiga software that requires the 68020+. The Amiga had a de facto 68020+AGA standard. It can even be difficult to find 68000 compiled versions of programs and avoid 68020+ code on a 68000. I recall at least one Amiga user who has complained ad nauseam about it.
After the 68000 ISA which was ahead of its time and forward thinking, the 68020 ISA was disappointing. However, there are some very important and commonly used additions, like 32/64 bit multiply and division, index register scaling for addressing modes and longer displacement implicitly PC relative branches.
Quote:
For what it's worth - a LOT of the software that _I_ use, benefit from FPU, but I cannot have an FPU that confuses software with silly rounding errors due to lack of precision. |
The Apollo Core and UAE 64 bit FPUs suffer from the same problem. They are incompatible with the 68k FPU because of reduced precision. Newer software often assumes 64 bit precision and works fine but some software uses the extra precision to not only improve accuracy but also reduce the number of instructions. Some compiler support for the 68k FPU is based on older code which uses the extra precision, like vbcc direct FPU support, so new software can have errors too. With vbcc and SAS/C, these problems can be avoided by compiling using the Amiga math libraries which is much slower and lower precision but has the advantage that it works on Amigas without an FPU too. A fair amount of Amiga programs use the Amiga math libraries which abstracts the 68k FPU hardware away and allows for an incompatible 68k FPU replacement.
I like the old school 68k FPU and appreciate the advantages it offers which are often overlooked today. It is much nicer than the old x86 FPU. There are challenges for modernizing and there are advantages to replacing with an SIMD unit like x86. Perhaps it would be a better fit for a vector processing unit (VPU) than SIMD unit but I'm still studying. In any case, I don't set standards nor is there any standards committee to decide. There are only de facto standards like an incompatible 68k FPU.
Last edited by matthey on 24-Aug-2020 at 09:33 PM.
|
|
| Status: Offline |
|
|
matthey
| |
Re: Amiga SIMD unit
Posted on 25-Aug-2020 0:41:50
| | [ #51 ] |
|
|
|
Elite Member
|
Joined: 14-Mar-2007
Posts: 2009
From: Kansas | | |
|
| Quote:
Hammer wrote:
Unlike AMMX, Amiga 68K has existing software that uses 68881/68882/68060 FPU.
|
Yes. There are some big and iconic applications which used 68k FPU instructions directly in the code like Lightwave. Amiga users would no doubt like to see programs like this fly. Many of these older programs were compiled for the 6888x using instructions which were later removed and trapped in the 68040 which makes boosting performance more difficult. Gunnar likes the simplified 68040 like FPU in FPGA because of the limited resources (his implementation removes some more instructions but adds some back like FINTRZ which was added back in the 68060 FPU too). Some of instructions are important today (the Libre project talks about needing instructions/functions which the 6888x supported) and could be added back but the high precision may slow them down too much. I had the impression from Mitch Alsup that he often favors keeping instructions in hardware because they aren't that difficult to implement and don't take that much area (he is very opinionated but logical and practical). I was surprised as this was contrary to Motorola and Gunnar's stance but then they have/had more limited resources. Of course the 88k FPU he helped design was extended precision too but I don't know how much control of decision making he had. He really should be interviewed and all this information recorded before it is lost.
Quote:
MMX is nearly pointless when AmigaPPC has Altivec/VMX-32 support. New Amiga apps could support MMX but integer datatype has limits. MMX was abandoned for SSE1 which supports both integer and 32bit floating-point formats.
Have you considered Altivec/VMX-32 with 68K CPU combo? I prefer multi-pipeline 68881/68882/68060 FPU.
|
I thought the SIMD unit would be similar to Altivec but then Gunnar changed it up. He surprised me one day by saying MMX was already partially implemented in the core. I was pushing for a 68k compatible FPU first and preferred the SIMD unit to be provisional (for testing and internal use instead of becoming part of the ISA).
It is nice to have SIMD instructions in the integer unit even if they are integer only and limited to 64 bit. The narrower SIMD operations and normal integer instructions reduce corner case code and unnecessary register movement is avoided. Although uncommon, the fp SIMD support could go in a wider FPU/fpSIMD unit. This is one way he could add wider SIMD support for the more important fp in the future without widening the integer registers and doing fp operation using the integer registers (Tabor is the only CPU I'm aware of to do this and it didn't last long). Gunnar has different constraints designing and hyper-optimizing for performance in an FPGA than for a hard chip. His short sightedness is more likely to keep the Apollo Core in FPGA and an FPGA only core will not gain respect or support.
Quote:
Game consoles from Microsoft and Sony have influenced X86 SIMD usage in PC gaming. Both PS5 and XSX have Zen 2 CPU which is quad 256bit pipelined AVX 2 enabled.
|
Makes sense. High end consoles need to be innovative and optimized to perform nearly as good as high end PCs with cheaper and lower power hardware.
Quote:
Both incoming PS5 and XSX (Xbox Series X) APUs also has powerful audio DSP solution besides the CPUs, raytracing enabled GPUs and real-time compression/decompression I/O co-processors.
AMD's gaming APUs have taken Amiga's custom chip concepts to the max.
|
The plethora of specialized hardware processors are likely to reduce power rather than boost performance. SMP cores could have been used for more workloads but the fat cores are limited to high performance workloads to save energy. ARM came up with big.LITTLE/DynamicIQ for this but it makes priority management more difficult. AMD cores can have their clock frequency lowered (DVFS) but those x86_64 cores are still big power hungry beasts.
Quote:
Xbox Series X APU's GPU has RTX 2080 level results when playing games such as Gears 5 built-in benchmark which is about 25% higher the PC's RX 5700 XT which relates to 25% memory increase from RX 5700 XT's 448 GB/s to XSX's 560 GB/s.
Fusion HSA conserves memory bandwidth usage when XSX doesn't have desktop PC CPU's discrete memory pool which enables XSX to be cheaper than gaming PC with comparable RTX 2080 GPU.
|
HSA CPU+GPU/APU SoCs are the future. I'm surprised they haven't taken over faster.
Quote:
Well, the Amiga market has been nearly ground zero'ed and needs to be rebuilt from the ground up.
I'm looking at Vampire 2 for my near-mint condition Amiga 1200. :p
|
Yes. Modern technology is too complex to start at the top. It's better to start smaller and simpler and keep improving. The Vampire started right just limits the "up" in an affordable FPGA.
|
|
| Status: Offline |
|
|
Hammer
| |
Re: Amiga SIMD unit
Posted on 25-Aug-2020 4:16:40
| | [ #52 ] |
|
|
|
Elite Member
|
Joined: 9-Mar-2003
Posts: 5286
From: Australia | | |
|
| @matthey
Quote:
The plethora of specialized hardware processors are likely to reduce power rather than boost performance. SMP cores could have been used for more workloads but the fat cores are limited to high performance workloads to save energy. ARM came up with big.LITTLE/DynamicIQ for this but it makes priority management more difficult. AMD cores can have their clock frequency lowered (DVFS) but those x86_64 cores are still big power hungry beasts.
|
Specialized hardware co-processor's design is against CPU die size e.g. SSD realtime compression/decompression hardware is equivalent to one to two ZEN 2 CPUs while consumes very small chip area space.
The main reason for my Ryzen 9 3900X selection is to replace the missing two co-processor hardware from Xbox Series X or PS5 i.e. Ryzen 9 3900X's 12 Zen 2 CPU cores against game console's 8 Zen 2 CPU cores enables up to four extra Zen 2 CPU cores (not factoring clock speed differences) being allocated for the missing hardware functions e.g.
1. SSD realtime compression/decompression hardware.
2. Audio DSP hardware with ~140 GFLOPS based on AMD's CU tech. Both DSP solution in Xbox Series X and PS5 exceeds the entire CPU power from PS4 Pro or Xbox One X.
Quote:
HSA CPU+GPU/APU SoCs are the future. I'm surprised they haven't taken over faster.
|
FYI, Intel APU's IGP(integrated GPU) dominates PC's total GPU market share.
NVIDIA's attempt to buy ARM Ltd is important for NVIDIA's future when Intel entering integrated and discrete GPU hardware with DirectX12 Ultimate capability.
Intel's 1st low-end Xe discrete GPU rivals the original Xbox One's GPU. Intel Xe HPG is a large discrete GPU with DirectX12 Ultimate (similar to Vulkan 1.2 level with hardware raytracing) capability.
Last edited by Hammer on 25-Aug-2020 at 04:40 AM.
Last edited by Hammer on 25-Aug-2020 at 04:39 AM.
Last edited by Hammer on 25-Aug-2020 at 04:22 AM.
_________________
Ryzen 9 7900X, DDR5-6000 64 GB RAM, GeForce RTX 4080 16 GB
Amiga 1200 (Rev 1D1, KS 3.2, PiStorm32lite/RPi 4B 4GB/Emu68)
Amiga 500 (Rev 6A, KS 3.2, PiStorm/RPi 3a/Emu68) |
|
| Status: Offline |
|
|
matthey
| |
Re: Amiga SIMD unit
Posted on 25-Aug-2020 23:39:30
| | [ #53 ] |
|
|
|
Elite Member
|
Joined: 14-Mar-2007
Posts: 2009
From: Kansas | | |
|
| Quote:
Hammer wrote:
Specialized hardware co-processor's design is against CPU die size e.g. SSD realtime compression/decompression hardware is equivalent to one to two ZEN 2 CPUs while consumes very small chip area space.
The main reason for my Ryzen 9 3900X selection is to replace the missing two co-processor hardware from Xbox Series X or PS5 i.e. Ryzen 9 3900X's 12 Zen 2 CPU cores against game console's 8 Zen 2 CPU cores enables up to four extra Zen 2 CPU cores (not factoring clock speed differences) being allocated for the missing hardware functions e.g.
1. SSD realtime compression/decompression hardware.
2. Audio DSP hardware with ~140 GFLOPS based on AMD's CU tech. Both DSP solution in Xbox Series X and PS5 exceeds the entire CPU power from PS4 Pro or Xbox One X.
|
Specialized hardware uses fewer active transistors for the same workload and thus uses less power. The general purpose CPU cores likely have the capability and performance to do the same specialized workloads but too many of the transistors for other purposes and for boosting performance can't be switched off. DSPs, VLIW processors, SIMD units and vector units often advertise huge theoretical (peak) performance numbers but actual performance is usually a fraction of this even with very careful programming. ALUs are cheap but keeping them busy is expensive.
Quote:
FYI, Intel APU's IGP(integrated GPU) dominates PC's total GPU market share.
NVIDIA's attempt to buy ARM Ltd is important for NVIDIA's future when Intel entering integrated and discrete GPU hardware with DirectX12 Ultimate capability.
Intel's 1st low-end Xe discrete GPU rivals the original Xbox One's GPU. Intel Xe HPG is a large discrete GPU with DirectX12 Ultimate (similar to Vulkan 1.2 level with hardware raytracing) capability.
|
Good to know. AMD's CPU cores and APUs used to be looked down on as the cheap option for motherboards. Intel integrated GPUs used to be worthless. Intel getting competitive in the GPU market puts the heat on Nvidia. It is interesting that Nvidia is preferring ARM for their APUs rather than partnering with Intel to use x86_64. They must think that ARM will be able to compete in the server, desktop and/or laptop/pad markets where their powerful GPUs are more useful than for embedded. The embedded market where ARM is dominant is lower margin but consistent and good for getting volumes up to reduce costs. Lower cost, power and performance consoles like Nintendo Switch are choosing Nvidia APUs with ARM CPU cores.
|
|
| Status: Offline |
|
|
Hammer
| |
Re: Amiga SIMD unit
Posted on 26-Aug-2020 4:56:24
| | [ #54 ] |
|
|
|
Elite Member
|
Joined: 9-Mar-2003
Posts: 5286
From: Australia | | |
|
| @matthey
Quote:
matthey wrote:
Quote:
Hammer wrote:
Specialized hardware co-processor's design is against CPU die size e.g. SSD realtime compression/decompression hardware is equivalent to one to two ZEN 2 CPUs while consumes very small chip area space.
The main reason for my Ryzen 9 3900X selection is to replace the missing two co-processor hardware from Xbox Series X or PS5 i.e. Ryzen 9 3900X's 12 Zen 2 CPU cores against game console's 8 Zen 2 CPU cores enables up to four extra Zen 2 CPU cores (not factoring clock speed differences) being allocated for the missing hardware functions e.g.
1. SSD realtime compression/decompression hardware.
2. Audio DSP hardware with ~140 GFLOPS based on AMD's CU tech. Both DSP solution in Xbox Series X and PS5 exceeds the entire CPU power from PS4 Pro or Xbox One X.
|
Specialized hardware uses fewer active transistors for the same workload and thus uses less power. The general purpose CPU cores likely have the capability and performance to do the same specialized workloads but too many of the transistors for other purposes and for boosting performance can't be switched off. DSPs, VLIW processors, SIMD units and vector units often advertise huge theoretical (peak) performance numbers but actual performance is usually a fraction of this even with very careful programming. ALUs are cheap but keeping them busy is expensive.
Quote:
FYI, Intel APU's IGP(integrated GPU) dominates PC's total GPU market share.
NVIDIA's attempt to buy ARM Ltd is important for NVIDIA's future when Intel entering integrated and discrete GPU hardware with DirectX12 Ultimate capability.
Intel's 1st low-end Xe discrete GPU rivals the original Xbox One's GPU. Intel Xe HPG is a large discrete GPU with DirectX12 Ultimate (similar to Vulkan 1.2 level with hardware raytracing) capability.
|
Good to know. AMD's CPU cores and APUs used to be looked down on as the cheap option for motherboards. Intel integrated GPUs used to be worthless. Intel getting competitive in the GPU market puts the heat on Nvidia. It is interesting that Nvidia is preferring ARM for their APUs rather than partnering with Intel to use x86_64. They must think that ARM will be able to compete in the server, desktop and/or laptop/pad markets where their powerful GPUs are more useful than for embedded. The embedded market where ARM is dominant is lower margin but consistent and good for getting volumes up to reduce costs. Lower cost, power and performance consoles like Nintendo Switch are choosing Nvidia APUs with ARM CPU cores.
|
A major reason for Nintendo selecting NVIDIA is graphics software engineering support.
AMD has K12 ARMv8 CPU offer. Qualcomm has both in-house and licensed ARM CPU designs along with its market-leading handheld SoCs.
Intel built its own GPU teams from the ex-Radeon VLIW and GCN PC group.
Intel HD 620 IGP can rival Nintendo Switch's GeForce 920MX level GPU. Intel has it's monthly "game ready" driver downloads like AMD and NVIDIA.
About 2/3 RTG(Radeon Technology Group) engineering resource is allocated for the two main game console customers i.e. MS and Sony.
The major limiter for PS5's DSP usage is memory bandwidth usage which is shared with CPU and GPU. Sony warns heavy DSP usage since it can consume up to 20% of the total 448 GB/s memory bandwidth.
Both Qualcomm GPU and Intel GPU teams have a high composition from ex-Radeon VLIW5, VLIW4, and PC GCN personnel. Last edited by Hammer on 26-Aug-2020 at 05:07 AM.
Last edited by Hammer on 26-Aug-2020 at 05:05 AM.
Last edited by Hammer on 26-Aug-2020 at 04:59 AM.
_________________
Ryzen 9 7900X, DDR5-6000 64 GB RAM, GeForce RTX 4080 16 GB
Amiga 1200 (Rev 1D1, KS 3.2, PiStorm32lite/RPi 4B 4GB/Emu68)
Amiga 500 (Rev 6A, KS 3.2, PiStorm/RPi 3a/Emu68) |
|
| Status: Offline |
|
|
Hammer
| |
Re: Amiga SIMD unit
Posted on 29-Aug-2020 9:40:36
| | [ #55 ] |
|
|
|
Elite Member
|
Joined: 9-Mar-2003
Posts: 5286
From: Australia | | |
|
| @matthey
Do you have information on Quake 68K's performance with Vampire 1200 V2 with GOLD2.12 Build 7389 firmware update?
Last edited by Hammer on 29-Aug-2020 at 09:41 AM.
_________________
Ryzen 9 7900X, DDR5-6000 64 GB RAM, GeForce RTX 4080 16 GB
Amiga 1200 (Rev 1D1, KS 3.2, PiStorm32lite/RPi 4B 4GB/Emu68)
Amiga 500 (Rev 6A, KS 3.2, PiStorm/RPi 3a/Emu68) |
|
| Status: Offline |
|
|
Hammer
| |
Re: Amiga SIMD unit
Posted on 29-Aug-2020 16:21:46
| | [ #56 ] |
|
|
|
Elite Member
|
Joined: 9-Mar-2003
Posts: 5286
From: Australia | | |
|
| |
| Status: Offline |
|
|
matthey
| |
Re: Amiga SIMD unit
Posted on 30-Aug-2020 4:18:39
| | [ #57 ] |
|
|
|
Elite Member
|
Joined: 14-Mar-2007
Posts: 2009
From: Kansas | | |
|
| Quote:
Hammer wrote:
Do you have information on Quake 68K's performance with Vampire 1200 V2 with GOLD2.12 Build 7389 firmware update?
|
No. I haven't been on the Apollo Team for a long time (from 3/2012 when it was just Gunnar, Jens, Chris, Rune and me until about 3/2014). Majsta wasn't even part of the team until I persuaded Gunnar to help him.
I don't even know what versions of Quake work on the Vampire. There are videos on Youtube like the following link with the V4SA which is the fastest hardware and AmiQuake which is one of the fastest Quake versions (although the AGA version is doing an unnecessary C2P when there is AmiQuake RTG).
https://www.youtube.com/watch?v=bCRvQeR-WdA
The performance looks better than a high clocked 68060 but the resolution is low (320x256x8?). It's ugly but I'm spoiled by my 68060@75MHz CSMK3 with Voodoo 4 where I play in 512x384x16 (~25 fps with Warp3D) which looks good. The Apollo Core is unlikely to get much faster in FPGA and the lack of 3D hardware means it will likely be stuck in the '90s forever. Amiga retro is not a bad place to be stuck but better for 2D, especially in an affordable FPGA.
Quote:
Under $200 U.S. is a good price for the handheld considering the nice screen, custom case and mostly FPGA logic which is more expensive than an ASIC in quantity. Lower end hardware doesn't need as expensive of an FPGA for simulation though. Analog has FPGA hardware for consoles like the Super Nintendo and Sega Genesis too. The Mega SG comes with a previously unreleased Sega Genesis platform game (Turrican style) developed by Digital Illusions to be published by Psygnosis which was 99% complete called Ultracore (Hardcore) and planned for the Amiga too.
https://www.analogue.co/mega-sg
Maybe the Amiga would get a release if there was any hardware for it but the Amiga companies would rather produce desktop computers with old embedded hardware for exorbitant prices and sue each other. Could it be any more embarrassing for the Amiga?
Quote:
Handheld mobile device with Altera Cyclone V FPGA and Vampire V4 also has Altera Cyclone V FPGA. Any plans for mobile Amiga Vampire V4?
|
We talked about a handheld and laptop briefly but there is more expense and more to support. The Amiga would need some adaption for a handheld as some games use the keyboard and mouse. MikeJ made a prototype FPGA Arcade handheld but I can't find the pic.
Quote:
The fastest Amigas have been UAE emulation for quite awhile although Intel hardware can be avoided with AMD hardware. I don't have a problem with Intel like I do with Microsoft who have abused their market position more. Intel got lucky with the IBM PC CPU choice even though Motorola had a much better product in the 68000 but Motorola made big mistakes too. Intel had better management and perseverance where Motorola lacked direction and gave up easily. Intel buying Altera was a good investment with cost savings if they could use their foundries for FPGA production. Ok, I took a little swipe at them. 
|
|
| Status: Offline |
|
|
Hammer
| |
Re: Amiga SIMD unit
Posted on 31-Aug-2020 5:32:39
| | [ #58 ] |
|
|
|
Elite Member
|
Joined: 9-Mar-2003
Posts: 5286
From: Australia | | |
|
| @matthey
Quote:
The fastest Amigas have been UAE emulation for quite awhile although Intel hardware can be avoided with AMD hardware. I don't have a problem with Intel like I do with Microsoft who have abused their market position more. Intel got lucky with the IBM PC CPU choice even though Motorola had a much better product in the 68000 but Motorola made big mistakes too. Intel had better management and perseverance where Motorola lacked direction and gave up easily. Intel buying Altera was a good investment with cost savings if they could use their foundries for FPGA production. Ok, I took a little swipe at them
|
Intel is using 10 nm for its FPGA e.g. Intel Agilex.
Hardware in my "Fastest 68K Amiga hardware" comments refers to hardware, not software emulation construct.
I agree with your comments on Motorola's inferior management when compared to Intel's.
Quote:
Under $200 U.S. is a good price for the handheld considering the nice screen, custom case and mostly FPGA logic which is more expensive than an ASIC in quantity. Lower end hardware doesn't need as expensive of an FPGA for simulation though. Analog has FPGA hardware for consoles like the Super Nintendo and Sega Genesis too. The Mega SG comes with a previously unreleased Sega Genesis platform game (Turrican style) developed by Digital Illusions to be published by Psygnosis which was 99% complete called Ultracore (Hardcore) and planned for the Amiga too.
https://www.analogue.co/mega-sg
Maybe the Amiga would get a release if there was any hardware for it but the Amiga companies would rather produce desktop computers with old embedded hardware for exorbitant prices and sue each other. Could it be any more embarrassing for the Amiga?
|
Sony's buying Psygnosis has impacted both Amiga and Sega platforms when Sony redirected Psygnosis programming teams towards Sony's original Playstation. The importance of game exclusivity for a software platform still impacts modern systems such as Xbox One/Xbox Series X vs PS4/PS5
_________________
Ryzen 9 7900X, DDR5-6000 64 GB RAM, GeForce RTX 4080 16 GB
Amiga 1200 (Rev 1D1, KS 3.2, PiStorm32lite/RPi 4B 4GB/Emu68)
Amiga 500 (Rev 6A, KS 3.2, PiStorm/RPi 3a/Emu68) |
|
| Status: Offline |
|
|
megol
| |
Re: Amiga SIMD unit
Posted on 31-Aug-2020 14:32:12
| | [ #59 ] |
|
|
 |
Regular Member
 |
Joined: 17-Mar-2008
Posts: 355
From: Unknown | | |
|
| @matthey
matthey wrote:
Quote:
The suboptimal RMW instructions of x86_64 with only 16 GP registers must be hurting performance.
|
That's independent on ISA and x86 wasn't mentioned at all.
It's suboptimal as memory accesses even when hitting L1 are slow (latency not throughput) and it wastes a lot of power.
Quote:
The 68060 can execute a RMW instruction like addq.l #1,(a0) in 1 cycle in either integer pipe (best case). By using a "complex" RMW instruction instead of separate "simple" load/read+op/modify+store/write instructions the 68060 gains the following advantages.
|
No I was talking about hardware not an idealized best case scenario. The latency isn't 1 cycle, the throughput can be.
Quote:
1) fewer instructions to decode
2) better utilization of the instruction cache
3) better utilization of the registers (fewer used)
4) more work is done in a shorter amount of time than separate instructions
|
For something that isn't generally useful. Accumulator style operations on memory operands aren't efficient.
Quote:
Even if the RMW instruction is broken apart when decoding, advantages 1-3 above still apply.
|
But you are still touching memory wasting power and adding latency.
Quote:
OoO in combination with wider execution is very powerful to effectively hide L1 and in many cases L2 latency. Looking in the literature of yesterday it's obvious that L1 latency needed to be as low as possible not to tank general performance, however the architectures of today are moving away from that instead having comparatively large L1 caches with longer latency. The difference is deeper OoO and more capable branch prediction.
|
Quote:
Most OoO RISC designs introduce load-use stalls which delay the use of the load data though other instructions may be able to fill the delay (delay increases with DCache access time). An L1 miss is something like 10-15 cycles which is difficult to hide for all but the most aggressively speculating OoO (that is a lot of non-dependent instructions). Furthermore, deep speculation can end up guessing wrong and loading the wrong data which can't easily be aborted and flushes good data out of the L1 DCache. Core designers do want to increase the cache sizes as caching is so important for performance but they sometimes do realize that pushing the pipeline length with increased branch misprediction penalties, load-use penalties and too large of L1 is counterproductive like with the POWER9 where the pipeline was shortened by 5 cycles and the L1 DCache halved.
|
Yes but I was talking about the intrinsic latency due to pipelining, SRAM access and wire delays (routing). The one that is about 3-4 cycles on a cache hit in a modern architecture due to physics not implementation nor ISA. That will likely increase in the future however OoO can only cover for so much latency inside that critical microarchitectural loop.
Deep OoO can cover even some L2 hits but of course if they start accumulating it's stall time.
Quote:
Do you really think a RMW instruction uses more energy than a separate load+op+store? I'd like to see any documentation you have of that because I doubt it. All active transistors use energy during the 3 cycle load+op+store where RMW they are active for just 1 cycle (this is a simple addressing mode where RISC can take several cycles longer for a more complex EA calc and can stall for several cycles with a load-use penalty even with OoO). The L1 cache is used less with RMW for the same amount of work so can enter a low energy state for longer. More registers are great for calculation intensive algorithms where RISC has a small advantage but RISC has a big disadvantage anytime memory is used (RISC memory fetch is eating mem bandwidth and the larger ICaches use energy too). Look at various disassembled compiler code and see how many instructions there are between a memory access. OoO helps with the RISC performance loss but MIPS/Watt is usually decreased (uses more energy per instruction).
|
You should be comparing to register accesses. RMW isn't magical and generally useful only as a replacement for missing registers. Then it becomes slower and more power consuming.
Sure it's possible to use it when memory have to be touched anyway and then not having to go through an additional EA stage will save some power but not much - the real expense is in cache accesses themselves.
A RISC capable of decoding 3 instructions per clock will have the same throughput and latency as your CISC for this uncommon operation and will execute more common code patterns faster than the CISC with one decoder. And the RISC is likely using fewer transistors to do it, variable length decoding is very transistor intensive. This is assuming the same number of L1 R/W ports.
Quote:
Are you worried about data supply while RISC instruction supply may be using your more energy?
|
No. Not talking about power optimized slow embedded controllers. Look instead at a modern processor optimized for performance and compare a complex decoder with a simple one.
The AMD Ryzen is a good example where decoding takes several clock cycles and is very parallel with a late selection/fusion of partial decodes. And before you repeat the cheap trick above no 68k decoding is complex too and would need a similar design.
Sure with a mid-90's style pipeline in a slow low power processor things look different but why discuss that in 2020? |
|
| Status: Offline |
|
|
matthey
| |
Re: Amiga SIMD unit
Posted on 1-Sep-2020 1:08:09
| | [ #60 ] |
|
|
|
Elite Member
|
Joined: 14-Mar-2007
Posts: 2009
From: Kansas | | |
|
| Quote:
Hammer wrote:
Intel is using 10 nm for its FPGA e.g. Intel Agilex.
|
Xilinx Versal FPGAs have been using a 7nm process for about a year (TSMC claims ~20% speed improvement or ~40% power reduction from their 10nm to 7nm process and Altera claims up to 40% higher performance or 40% lower power for the 10nm Agilex over the 14nm Stratix 10). Intel's lack of 7nm process is likely hurting Altera high end FPGA sales. These are high margin data center focused FPGA accelerators doing parallel DSP like workloads with AI datatype support to compete with GPUs. FPGAs use high tech processes to make up for routing inefficiencies.
Quote:
Hardware in my "Fastest 68K Amiga hardware" comments refers to hardware, not software emulation construct.
|
I think of FPGA programmable hardware as being between a hard chip and software emulation but the simulation is much closer to the actual logic of a hard chip.
A high clocked rev 6 68060 with fast memory is still a potent contender with the Apollo core. It has more features (MMUs and more compatible 68k FPU) and may outperform in some performance benchmarks even against the V4SA FPGA CPU core. For 3D, a high clocked 68060 with Voodoo 3/4 outperforms Vampires after the textures are in the GPU memory despite the slow bus speed. We looked at PCI and PCIe slots for the Vampire but Gunnar rejected the idea. PCIe and SATA requires SerDes which are available in the Cyclone V but cost more. PCI requires more pins but would have been cheaper. At the time, it was difficult enough to get Majsta to upgrade to the Cyclone V (he was buying older cheap E-bay Cyclone FPGAs until he was stung by counterfeits) and raise prices to help with production and more safely cover costs from unexpected problems (there were more than a few production problems at the beginning).
Quote:
Sony's buying Psygnosis has impacted both Amiga and Sega platforms when Sony redirected Psygnosis programming teams towards Sony's original Playstation. The importance of game exclusivity for a software platform still impacts modern systems such as Xbox One/Xbox Series X vs PS4/PS5
|
Psygnosis retains some autonomy from Sony and has released games for other platforms after they were purchased. They were often only a publisher of games in the Amiga days as they were to be with Ultracore. They were known for their Amiga support and using Amiga tools but so was Digital Illusions (DICE) who created Ultracore. Digital Illusions was started by a Swedish Amiga demo group and created Pinball Dreams/Fantasies/Illusions and Benefactor for the Amiga before being bought by EA. The video from the official site mentions the Sega Mega Drive, Sega Genesis, PS4, PSVita but no mention of the Amiga.
https://www.youtube.com/watch?time_continue=22&v=MZdrgBtRW8g&feature=emb_logo
At least they weren't too embarrassed to mention the Amiga first on the web site.
Quote:
Our first quest leads us to a long lost treasure of Swedish gaming history: During the early 1990s, the Swedish video game developer Digital Illusions (also known as DICE) started working on their new game. Developed for Commodore Amiga, Sega Mega Drive / Genesis and Sega Mega-CD, the game was about 99% finished. It already got early previews in many gaming magazines, promoting their excitement at the fun and guns of Hardcore (Sega Power, 1994).
|
The Amiga is barely a blip on the radar with so little and such expensive hardware that it is a joke. We don't get releases like Ultracore or even Indie titles like the Legend of Grimrock series which was first programmed by a Finnish Amiga demo coder. Most Amiga people consider the Amiga dead. Sadly, a few remaining zealots are intent on making it disappear forever.
Last edited by matthey on 01-Sep-2020 at 01:14 AM.
|
|
| Status: Offline |
|
|
