Your support is needed and is appreciated as Amigaworld.net is primarily dependent upon the support of its users.

|
|
|
 22 crawler(s) on-line. 22 crawler(s) on-line.
 95 guest(s) on-line. 95 guest(s) on-line.
 0 member(s) on-line. 0 member(s) on-line.
You are an anonymous user.
Register Now! |
|
|
|
| Poster | Thread |  MEGA_RJ_MICAL MEGA_RJ_MICAL
|  |
Re: RGL, Amiga Corp & Atari partner Plaion to produce NeoGeo AES+ using ASICs
Posted on 19-May-2026 1:33:23
| | [ #41 ] |
| |
 |
Super Member
 |
Joined: 13-Dec-2019
Posts: 1471
From: AMIGAWORLD.NET WAS ORIGINALLY FOUNDED BY DAVID DOYLE | | |
|
| | | Status: Offline |
| | matthey
| |
Re: RGL, Amiga Corp & Atari partner Plaion to produce NeoGeo AES+ using ASICs
Posted on 25-May-2026 23:56:02
| | [ #42 ] |
| |
 |
Elite Member
 |
Joined: 14-Mar-2007
Posts: 2925
From: Kansas | | |
|
| Joe Circello, chief architect of 68060, answers question about 68000 CPU in NeoGeo AES+
https://youtu.be/1takr2k7Yfo?t=4465
Question: Given that the team at Plaion has managed to recreate an ASIC version of the 68000 for the new NeoGeo AES+ console, do you think it is possible or will eventually be possible to do the same thing for the '060 for perhaps a future Amiga Ultimate computer?
Answer: "There is a huge world of difference between a 68000 and 68060, right. I mean they're orders of magnitude more complex, the machines."
But...
1. " the 68060 does not have any microcode per se in it" where 68000 microcode uses 34136 bits with some estimates at ~20k of ~68k transistors (ARM1 was ~25k transistors using 1512 bits of microcode)
2. x86 is "clearly clearly more complicated" than 68k and "started from a position of difficulty and has only gotten worse over all the years"
3. "original 68000 was fairly well known as being a very clean ISA implementation"
4. 68060 "processor itself and the pipeline, all of that stuff, was done fully synthesizable" allowing the 68060 to be synthesized in a modern FPGA
5. fully synthesizable 68060 design more easily allows a "validated and verified" design, moving to newer chip fab processes and improves chip yields (68060 did not suffer from chip yield problems of earlier 68k CPUs)
6. "There is always the option of starting from a clean sheet of paper and going off and developing a new microarchitecture. Even if you are trying to copy an existing one, you have to go through the process. That is an infinitely more complex road than being able to take, if you had a snapshot of the existing design, like the RTL database, being able to take that and resynthesize that in a 5nm process or something like that."
7. the 68060 used to emulate a 68040 Mac at better performance than any Mac "which warms my heart" but now stand alone ARM and x86 hardware are orders of magnitude better performance than any 68k Amiga while we keep reinventing and throwing away known good 68k wheels
Text in quotes above are from Joe Circello.
The NeoGeo AES+ ASICs may allow an optional minor 68000 overclock of 50% (12MHz to 18MHz) providing an ~50% performance improvement while a modernized 68060 Amiga, like the old in-order Intel Atom, should provide an ~10,000% to ~20,000% CPU performance improvement. This would be using an older more affordable process like the Atom originally used of ~40nm instead of the 5nm process Joe mentioned. Would the two NeoGeo AES+ ASICs or a single ASIC 68060+ Amiga SoC offer more value? Should Motorola engineers have settled for another 6800 model CPU and should Jay Miner have settled for another 6502 gaming machine because it would have been easier? Do 68k and Amiga fans like the hardware and technology, understand it and know it is still good other than being on outdated silicon or shall we throw away the old 68k Amiga technology and history choosing to use emulation on ARM and pretending it is real 68k Amiga hardware because it is easier?
Last edited by matthey on 25-May-2026 at 11:58 PM.
|
| | Status: Offline |
| | kolla
| |
Re: RGL, Amiga Corp & Atari partner Plaion to produce NeoGeo AES+ using ASICs
Posted on 26-May-2026 17:43:33
| | [ #43 ] |
| |
 |
Elite Member
|
Joined: 20-Aug-2003
Posts: 3593
From: Trondheim, Norway | | |
|
| @matthey
Why âorâ when we can do both? Emulation of CPU is fine by me, not like the real 68k CPUs were doing much in parallel (except FPU) anyways, and if you donât care about MMU you can have very fast JIT emulation for cheap. However, some of us want fast _and_ fully featured 68k with MMU, not necessarily to run AmigaOS, and for that we long for a new ASIC 68040/060-ish CPU.
Oh and the AC68080 MMU is now 6 months overdue because reasons. Last edited by kolla on 26-May-2026 at 05:45 PM.
_________________
B5D6A1D019D5D45BCC56F4782AC220D8B3E2A6CC |
| | Status: Offline |
| | OneTimer1
| |
Re: RGL, Amiga Corp & Atari partner Plaion to produce NeoGeo AES+ using ASICs
Posted on 26-May-2026 20:48:38
| | [ #44 ] |
| |
 |
Super Member
|
Joined: 3-Aug-2015
Posts: 1528
From: Germany | | |
|
| @kolla
Quote:
kolla wrote:
However, some of us want fast _and_ fully featured 68k with MMU, not necessarily to run AmigaOS, and for that we long for a new ASIC 68040/060-ish CPU.
|
True, if you want full compatibility you need FPU+MMU and at least a 68040 compatible ABI.
If you only want to sell a gaming device for the masses, you can go with 68000 (A500) or 68020 (A1200) and no one will ask you for performance increase. The 'masses' of potential customers are ex-Amiga users, they will happily buy something that runs like a basic Amiga.
Only a fraction of a fraction is asking for a faster Amiga, I got the impression that no one is asking for a Apollo A6000. |
| | Status: Offline |
| | matthey
| |
Re: RGL, Amiga Corp & Atari partner Plaion to produce NeoGeo AES+ using ASICs
Posted on 26-May-2026 22:21:53
| | [ #45 ] |
| |
|
Elite Member
|
Joined: 14-Mar-2007
Posts: 2925
From: Kansas | | |
|
| @kolla
The superscalar 68060 is "doing much in parallel" with many units operating in parallel, not just the FPU.
68060 units which can issue/execute/retire/fold instructions in parallel
2x integer units (equivalent of load/store unit in each integer unit)
1x branch unit
1x FPU
45%-55% of instructions issued as pairs/triplets (existing 680X0 code)
50%-65% of instructions issued as pairs/triplets (targeted 68060 code)
This is a high instruction multi-issue rate, especially for existing unsheduled 68k code. Most instruction execution is with single cycle throughput like RISC cores but unlike RISC cores, more powerful CISC instructions with memory accesses can execute in a single cycle. Emulation can not come close to the performance efficiency (performance/MHz or performance/cycle) of the 68060, even using a much more expensive OoO CPU core which uses more power and generates more heat. If we assume AArch64 requires 5 instructions for each 68k instruction, one 68k instruction using less than 3 bytes of code on average expands to 20 bytes of code. The RPi 3 in-order Cortex-A53 and RPi 4 OoO Cortex-A72 have a 16B/cycle instruction fetch yet can not keep up with the power saving 4B/cycle instruction fetch of the 68060 for 68k code. Instruction supply is the largest power consumption for smaller CPU cores which is a major reason why code density is so important.
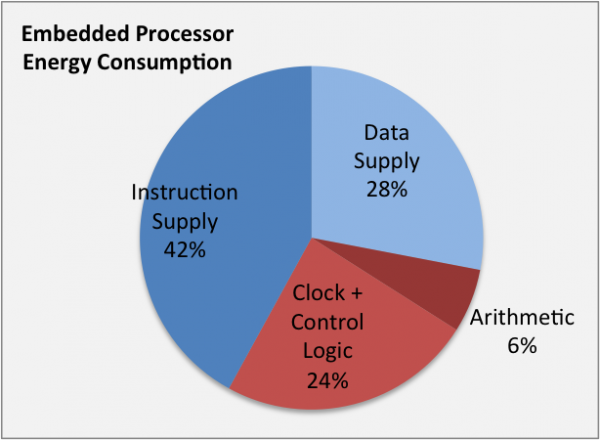
https://www.cast-inc.com/blog/consider-code-density-when-choosing-embedded-processors
The Cortex-A53 can issue 2 instructions/cycle and the Cortex-A72 3 instructions/cycle but this also does not keep up with the up to 3 instruction/cycle issue of the 68060 for 68k code. The Cortex-A72 OoO also uses more power and wastes energy reducing or eliminating the load-to-use stalls the 68060 does not have. This abomination of efficiency is when executing the already translated code in JIT buffers where translating the 68k code to AArch64 code is more wasteful, creates jitter, the JIT buffers waste several times more memory that a 68k system uses and the much increased memory accesses waste energy. Come pay up to try our abomination of 68k efficiency on ARM hardware and if you like it, you will have to learn to live with 1990s performance levels. How is this going to attract ex-Amiga fans let alone new users?
The solid state transistor and general purpose computer/CPU are THE most important tech inventions/advancement of the last 100 years. Most other top tech advancements of the last 100 years would not be possible without them. There are approximately 3 to 4 MPUs and tens of MCUs in the world for every living person. The 2 most important attributes of a computer that make it useful are performance and price. Efficiencies are also important which reflect these such as price efficiency (performance/$), power efficiency (performance/W) and performance efficiency (performance/MHz). If you want the 68k to be antiquated and EOL, then ignore this reality. The good news is that I believe the 68k could be competitive on silicon. The bad news is that many 68k fans do not see the advantage of this. I not only want 68k hardware to replace my dying 68k Amigas but also to be able to do more computer work on 68k hardware which is easier to use than any other computers I have experienced.
Features are important for computer usefulness too. Any 68k hardware needs more modern I/O while retaining retro compatibility. A MMU per CPU core is an important feature for modern systems. Not only is it important for retro 68k use but it is important for other more modern features like memory protection, process isolation, security and SMP. I believe it is possible to retain compatibility and vastly improve performance. A modernized 68060 design would operate much the same way as the 68060 design and it is a fully static design that can have the frequency reduced from max to zero. Add a fully static 68000 core to the SoC and a few more clock sources than usual to increase 68k compatibility further. Adding back some missing 68060 features should improve 68k compatibility as well since transistors on silicon are much cheaper than in the 1990s.
Last edited by matthey on 26-May-2026 at 10:47 PM.
|
| | Status: Offline |
| | OneTimer1
| |
Re: RGL, Amiga Corp & Atari partner Plaion to produce NeoGeo AES+ using ASICs
Posted on 27-May-2026 14:08:00
| | [ #46 ] |
| |
|
Super Member
|
Joined: 3-Aug-2015
Posts: 1528
From: Germany | | |
|
| @matthey
Quote:
out of production, NXP is giving a sh!t about its legacy hardware, they are supporting ARM now and every embedded customer is asking for ARM instead of 68xLast edited by OneTimer1 on 27-May-2026 at 07:25 PM.
Last edited by OneTimer1 on 27-May-2026 at 02:10 PM.
|
| | Status: Offline |
| | matthey
| |
Re: RGL, Amiga Corp & Atari partner Plaion to produce NeoGeo AES+ using ASICs
Posted on 27-May-2026 21:43:14
| | [ #47 ] |
| |
|
Elite Member
|
Joined: 14-Mar-2007
Posts: 2925
From: Kansas | | |
|
| OneTimer1 Quote:
out of production, NXP is giving a sh!t about its legacy hardware, they are supporting ARM now and every embedded customer is asking for ARM instead of 68x
|
ARM makes life easy for NXP and others. ARM develops and provides the ISAs, configurable CPU and GPU cores, standard IP blocks, etc. The a la carte resources are convenient for NXP and has made them lazy. They pay significant royalties to ARM while they have better technology they stopped developing. ARM has become the standard and nobody gets fired for buying ARM. The original saying was nobody gets fired for buying IBM but did that make the IBM PC/AT better than the 68k Amiga in 1985? Did the 68k Amiga have better CPU and chipset tech, come with a better OS and at a significantly lower price than the IBM PC/AT? Should the Amiga developers have stopped Amiga development because the IBM PC was already the PC standard or chosen x86 CPUs because that looked like a safer option for the future of PCs?
As for MSX switching to ARM hardware which you edited away, it did not help compatibility.
Review MSX0 Stack â Handheld MSX Revival Is A Bitter Disappointment
https://www.timeextension.com/reviews/msx0-stack-n-handheld-msx-revival-is-a-bitter-disappointment Quote:
Compatibility isnât 100%, unfortunately. We've had a few games that would not load at all, while some do run but with graphical glitches that render them either annoying or unplayable. Worryingly, the menu for selecting disks is also glitchy. Give a disk image an over-long filename or fill the SD card with more than a handful of games and the menu is prone to corrupt or simply not display every filename. Itâs no wonder that some early adopters have programmed their own improved disk selection tool. When games work, which is about 70% of the time in our experience, itâs really good fun to play old favourites on this dinky system â but we would have expected a much higher compatibility rate from an official system.
...
Until that time, we would only recommend the MSX0 to hardcore fans. For everyone else, there are better solutions. We'd encourage anyone curious about the classic system to buy a real MSX2 and a few carts, while those who wish to emulate on the go will almost certanly find more reliability in the Analogue Pocketâs forthcoming FPGA core. An FPGA core is also available for the MiSTer platform.
That said, we've found ourselves taking the MSX0 with us everywhere we go this week. Itâs small enough to add to our daily carry, and many games are compact enough for quick bursts of play in spare moments. In many ways, the system reminds us of the Amiga; it has the potential to be expanded, altered and improved by its community in ways perhaps its creators never anticipated, and we hope it will eventually blossom into something special in time.
|
It is funny that Ashley Day, the new MSX handheld review author, would bring up the 68k Amiga to compare with the flexibility provided by the ARM based hardware. The 68k Amiga with 32-bit CPU ISA and modular dynamic libraries is more flexible, expandable and upgradeable than many earlier systems based on 8-bit tech. Emulation did not improve the MSX handheld but a Z80 CPU is not nearly as upgradeable as a 68k CPU. While the Z80 family is more capable of supporting OSs and compilers than the 6502 family, the 68k can fully support and retains surprisingly good support by OSs, compilers and development tools despite the age. The 68060 is already supported by the Amiga, Atari ST, X68000, 68k Mac and Sinclair QL. The most modern Z80 family successor, the Z80000/Z320, is not compatible with the Z80 while the 68060 not only offers good compatibility but good performance executing 68k code from before the 68060 was released.
68060 units which can issue/execute/retire/fold instructions in parallel
2x integer units (equivalent of load/store unit in each integer unit)
1x branch unit
1x FPU
45%-55% of instructions issued as pairs/triplets (existing 680X0 code)
50%-65% of instructions issued as pairs/triplets (targeted 68060 code)
The 6502 and Z80 CPU family gaming computers and consoles are limited by the primitive CPU designs. MIPS based consoles like the PS1, PS2 and N64 can not be easily upgraded to superscalar CPUs because of the RISC instruction fetch bottleneck problem compounded by NOPs in the code, load-to-use stalls requiring different instruction scheduling and branch delay slots causing further problems. Also, deeper pipelines of modern RISC cores usually increase load-to-use penalties which was already a problem for the relatively early MIPS R4000. ARM for the not gaming oriented Acorn Archimedes and the 3DO console is a little better off. The Archimedes RISC OS requires kludges for 26-bit addressing software and the original 32-bit ISA is being dropped from both superscalar Cortex-A cores and MCUs leaving few options for legacy support. The 3DO ARM CPU received the new 32-bit addressing narrowly avoiding this problem. ARM did not use NOPs excessively or use branch delay slots but newer superscalar cores have increased load-to-use penalties, like the Cortex-A53 with a 3 cycle load-to-use penalty, and superscalar execution requires more independent instructions between a load and use of the data loaded, twice as many independent instructions in the case of 2-way superscalar execution like the Cortex-A53. The original ARM 32-bit ISA was weak with only 14 GP registers while the code density was almost as bad as old RISC ISAs with 30+ GP registers like MIPS, SPARC and PPC. The 68k has 16 GP registers with the code density of ARM's Thumb ISAs, which allowed ARM to finally take the embedded market but with weaker performance than the 68k as usually only 8 GP registers are available. Later RISC architectures than the 68k have more modern performance handicaps and legacy RISC code may not run on more modern RISC cores at all. A RISC philosophy rarely stated is the do over at the expense of compatibility philosophy. This is why we are up to RISC-V after 4 do overs, ARM has 4 ISAs with 3 do overs and the A1222 is barely PPC compatible after fat PPC castrations for the embedded market. Modern RISC should stand for Redone Instruction Set Architecture considering that modern RISC ISAs no longer have a minimalist Reduced Instruction Set Architecture. The CISC 68k ISA has fewer instructions than most modern RISC ISAs.
Last edited by matthey on 27-May-2026 at 10:45 PM.
Last edited by matthey on 27-May-2026 at 09:46 PM.
|
| | Status: Offline |
| | kolla
| |
Re: RGL, Amiga Corp & Atari partner Plaion to produce NeoGeo AES+ using ASICs
Posted on 6-Jun-2026 21:48:20
| | [ #48 ] |
| |
|
Elite Member
|
Joined: 20-Aug-2003
Posts: 3593
From: Trondheim, Norway | | |
|
| @matthey
Quote:
68060 units which can issue/execute/retire/fold instructions in parallel
2x integer units (equivalent of load/store unit in each integer unit)
1x branch unit
1x FPU |
Thatâs not the point, which was about code execution in an emulated 68k vs a real 68060, running AmigaOS - AmigaOS code doesnât expect the CPU to do things in parallel (even when it does) so emulation of CPU isnât nearly as "critical" as having chipset components running independently from each other and the CPU._________________
B5D6A1D019D5D45BCC56F4782AC220D8B3E2A6CC |
| | Status: Offline |
| | matthey
| |
Re: RGL, Amiga Corp & Atari partner Plaion to produce NeoGeo AES+ using ASICs
Posted on 8-Jun-2026 0:18:57
| | [ #49 ] |
| |
|
Elite Member
|
Joined: 14-Mar-2007
Posts: 2925
From: Kansas | | |
|
| @kolla
The Hyperion developed 68k AmigaOS has 1979 expectations for a 16-bit 68000 CPU. An expectation for code is that instructions are generally executed as if sequentially ordered in memory like most other CPUs. A 68000 compiler target assumes a scalar 68000 CPU with selection of instructions and optimizations based on 68000 timings. Instruction scheduling reordering of instructions to avoid instruction pipeline and superscalar instruction pipeline dependency stalls is unnecessary without a 68000 pipeline or superscalar capabilities. Instruction pipelining is a form of Instruction Level Parallelism (ILP) and the scalar 68020-68040 sometimes benefit from instruction scheduling.
https://en.wikipedia.org/wiki/Instruction-level_parallelism Quote:
Micro-architectural techniques that are used to exploit ILP include:
o Instruction pipelining, where the execution of multiple instructions can be partially overlapped.
o Superscalar execution, VLIW, and the closely related explicitly parallel instruction computing concepts, in which multiple execution units are used to execute multiple instructions in parallel.
o Out-of-order execution where instructions execute in any order that does not violate data dependencies. Note that this technique is independent of both pipelining and superscalar execution. Current implementations of out-of-order execution dynamically (i.e., while the program is executing and without any help from the compiler) extract ILP from ordinary programs. An alternative is to extract this parallelism at compile time and somehow convey this information to the hardware. Due to the complexity of scaling the out-of-order execution technique, the industry has re-examined instruction sets which explicitly encode multiple independent operations per instruction.
o Register renaming, which refers to a technique used to avoid unnecessary serialization of program operations imposed by the reuse of registers by those operations, used to enable out-of-order execution.
o Speculative execution, which allows the execution of complete instructions or parts of instructions before being certain whether this execution should take place. A commonly used form of speculative execution is control flow speculation, where instructions past a control flow instruction (e.g., a branch) are executed before the target of the control flow instruction is determined. Several other forms of speculative execution have been proposed and are in use, including speculative execution driven by value prediction, memory dependence prediction, and cache latency prediction.
o Branch prediction, which is used to avoid stalling for control dependencies to be resolved. Branch prediction is used with speculative execution.
ILP is exploited by both the compiler and hardware, but the compiler also provides inherent and implicit ILP in programs to hardware by compile-time optimizations. Some optimization techniques for extracting available ILP in programs include instruction scheduling, register allocation/renaming, and memory-access optimization.
|
FPU instructions can execute in parallel with int instructions also benefiting in performance from instruction scheduling for the 68020-68060. This is a simplified but similar OoO execution to high performance OoO CPUs which is mentioned as ILP. Commodore supported at least 2 forms of CPU ILP and compiled the AmigaOS for the 68020 which offers much better performance for the 32-bit pipelined 68020-68060 than compiling for the 16-bit unpipelined 68000. The SAS/C compiler used to compile the AmigaOS was simple and had just introduced instruction scheduling targeting the Motorola 68040 processor and 6888x FPUs with SAS/C 6.0 released in 1993. Commodore went bankrupt the year the 68060 was released explaining why the superscalar ILP of the 68060 was not better supported. Note that the 68060 also uses ILP speculative execution, branch prediction and a form of what Motorola called register renaming allowing the results of early execution in the AGU stage of some instructions to be forwarded to the other int pipeline thus avoiding similar stalls as what is normally thought of as register renaming. Another important ILP of the 68060 not mentioned but that much improves 68k Amiga performance is the store buffer.
M68060 Userâs Manual Quote:
The MC68060 implements a four-entry store buffer that maximizes system performance by decoupling the integer pipeline from the external system bus. When needed, the store buffer allows the pipeline to generate writes every clock cycle until full, even if the system bus runs at a slower speed than the processor.
|
Chip memory should be marked as cache-inhibited imprecise on the 68060 reducing the performance loss of slow chip memory CPU stores. Earlier 68k CPUs had to wait on slow chip memory for stores to complete. Commodore was planning for AA+ to add write posting and fast register access to reduce CPU and chipset related stalls as they planned to use a 68020/68030 class CPU with AA+ and the single chip 68k Amiga.
Specifications for Upgraded AA (AA+) based system Quote:
Write Posting (optional)
To minimize stalls caused by chip access, ARIEL supports write posting (aka write buffering). What this means is that for a chip register or memory write ARIEL latches the processor address and data and immediately asserts A_DONE_N, allowing the processor to proceed while the write is completed at some later time. Obviously if a read or second write request is issued before the first one has been executed, the second request must be deferred until completion.
There is some concern about potential adverse software impact, but this is probably minimal since the write will be completed just as soon as if the processor was stalled on it, and any subsequent read (or write) will cause resynchronization by stalling on an uncompleted write. However, it is important that writes to INTENA bypass this feature since this would leave open the possibility that interrupts would be recognized after they were disabled by the CPU. Write posting requires no significant on-chip resources, but entails some elaborate of the processor interface logic.
|
After Commodore upper management got their head out of their ass after realizing their "no new chips" mandate would produce an outdated 68k Amiga instead of the next C64, they tried to catch up quickly with the rushed AA/AGA and better done AA+ but it was too late. At least the engineers understood the importance of CPU ILP which works in parallel with chipset and multi-processor/multi-core parallelism. CPU ILP allows the single core/thread performance needed by games and allows software in general to be more interactive. While the chipset was the cheaper way to provide performance back then, CPU performance upgrades were more general purpose and often provided larger performance improvements. AI says that from a 386 to an in-order Intel Atom is roughly a 1,000 to 15,000 times performance improvement which should be similar to a 68020/68030 improved into a modernized 68060+. A 68060 would likely have remained too expensive for Commodore to use in a single chip 68k SoC until the late 1990s despite the reasonable $308 USD price at introduction. Today, a 68060&AA+ SoC could be produced for less than $1 USD as it uses fewer transistors than less than $1 RPI MCUs. The choice is between ignoring modern tech with a no new chips philosophy and a retro EOL virtual Amiga or modernizing it so it is useful and relevant again. Commodore supported ILP for improved CPU performance but was slow to advance tech which greatly contributed to their demise. Hyperion development of the AmigaOS is a step back in tech at a much later date still using the SAS/C compiler but now targeting a 68000 with practically no ILP. Commodore had fallen far enough behind in tech to be called a dinosaur but the software AmigaOS support and hardware virtual 68k Amiga emulation is much further behind today.
The only use of the current 68k Amiga is for retro EOL support. A virtual 68k Amiga is not competitive for any other use.
https://www.buffee.ca/Why-PJIT-Why/ Quote:
In Emu68, a single 16-bit 68000 opcode can take several 32-bit ARM instructions to execute; if every opcode took just three, then that's a 600% increase in code size, not including the extra bit of code to enter and exit each block and the possibility of the same block of code needing to be translated several times from slightly different entry points.
|
JIT 600% code growth creates an instruction fetch bottleneck worse than the fat RISC bottleneck and blows out caches. It is not competitive for performance.
https://www.buffee.ca/Why-PJIT-Why/ Quote:
Jitter is caused when the JIT code needs to be created the first time before it can be executed. It is so expensive that most modern JITs will avoid it on the first pass of code. On Emu68, the jitter shows about a 20~25% performance difference between the self-reported SysInfo scores and the "wall clock" benchmark that includes the time to create the block.
|
JIT jitter is unacceptable for embedded systems where consistent performance and response times for interrupts are valued. The in-order Cortex-A53 at 2.3 DMIPS/MHz replaced the OoO Cortex-A9 at 2.5 DMIPS/MHz with similar performance and reduced stalls. Part of the reason the Cortex-A53 became the most popular CPU core ever is that it had reduced jitter compared to the Cortex-A9.
https://wiki.amiga.org/index.php/A600GS Quote:
A600GS
o 2GB system memory with 512MB allocated to AmiBench as Fast Memory
o 64GB total storage
The A600GS+ has enhanced specifications:
o 4GB system memory with 1GB allocated to AmiBench as Fast Memory
o 128GB total storage
|
Wasting 75% of system memory is nowhere close to competitive for small footprint systems.
https://amigaworld.net/modules/newbb/viewtopic.php?mode=viewtopic&topic_id=35809&forum=33&start=1540&viewmode=flat&order=0#872510 Quote:
Native ARM code with instruction scheduling can partially remove the huge ARM Cortex-A53 bottleneck due to load-to-use stalls. Simple and quick emulation conversion of 68k to AArch64 code usually does not include instruction scheduling though. Worst case instruction scheduling can be expected as the 68k CPUs do not have load-to-use stalls so the code is not scheduled to avoid them (load results are usually accessed by the next instruction stalling the Cortex-A53). A load-to-use penalty of 3 cycles is a performance killer and bad for an 8-stage CPU especially when 68k CPUs didn't have any load-to-use penalty. Then there is the RISC load/store instruction bottleneck that requires more instructions, memory traffic and registers than CISC.
A typical general purpose CPU workload of instructions will average to approximately the following.
load 26% (~25% which is 5 out of 20 instructions)
store 10% (2 out of 20 instructions)
ALU 49% (~50% which is 10 out of 20 instructions)
branch 15% (3 out of 20 instructions)
20 instruction typical workload for ARM Cortex-A53 emulating 68k code
load x5 with load-to-use stalls (5*4= 20 cycles)
store x2 (2*0.5 to 2*1= 1-2 cycles with store buffer)
ALU x10 (10*0.5 to 10*1= 5-10 cycles)
branch x3 (most are conditional predicted branches so ~0 cycles)
---
total: 26-32 cycles
The Cortex-A53 load instruction execution throughput is 1 cycle but the latency is 3 cycles and the load result can't be used for 3 cycles. Much of the Cortex-A53 performance improvement over the predecessor Cortex-A7 is due to improved superscalar execution but this requires very good and sometimes impossible instruction scheduling due to the increased load-to-use penalty. The Cortex-A53 has two simple integer execution pipelines so it can execute two ALU instructions in a cycle but so could the 68060 which also has most of the design features without the bottlenecks.
20 instruction typical workload for 68060
load+ALU x5 (5*0.5 to 5*1= 2.5-5 cycles)
store x2 (2*0.5 to 2*1= 1-2 cycles with store buffer)
ALU x5 (5*0.5 to 5*1= 2.5-5 cycles)
branch x3 (most are conditional predicted branches so ~0 cycles)
---
total: 6-12 cycles
|
The Cortex-A53 wastes roughly half of CPU core cycles to load-to-use stalls with JIT unscheduled code. With code and data cached, the 68060 outperforms the Cortex-A53 at the same clock speed even when the Cortex-A53 uses perfectly scheduled code which is very difficult. If you do not believe that is possible, compare the P5 Pentium using ancient fab process and the same size caches as the 68060 vs Cortex-A53 in the 7-Zip benchmark below and then consider that the 68060 had 40% better integer performance than the Pentium in the ByteMark benchmark. If the 68060 had 40% better int performance for the 7-Zip benchmarks, it would have an avg score of 0.88, outperforming the most popular in-order cores for embedded use, the OoO PPC G5 and the OoO Cortex-A9. The SiFive series 7 (U74) cores use a similar but modernized CISC/68060 like design with a weaker RISC-V ISA. I believe a modernized 68060+ core can compete with limited OoO cores several times the size while some here believe a Cortex-A53 virtual 68k Amiga that can not reach scalar CPU core performance and with a far worse jitter and memory footprint is adequate.
single core | 7-Zip compression/MHz | 7-Zip decompression/MHz | 7-Zip avg
IBM_Cell_PPE 0.23 0.33 0.28 (PS3)
AtomN2800 0.47 0.62 0.55
PentiumP5 0.64 0.62 0.63
Cortex-A53 0.56 0.92 0.74 (RPi 3, A500 Mini, A600GS)
SiFive_U74 0.70 0.92 0.81 (RISC-V HiFive Unmatched, VisionFive 2 core claimed 20% better per MHz)
Cortex-A55 0.63 1.03 0.83
68060 ? ? 0.88 (68060 estimate of +40% int performance/MHz vs Pentium)
SiFive_U74 ? ? 0.97 (VisionFive 2 core estimate of +20% performance/MHz vs Unmatched)
IBM_PPC_G5 0.49 0.82 0.66 (OoO)
Cortex-A9 0.56 0.84 0.70 (OoO)
IBM_POWER9 1.08 0.83 0.96 (OoO)
Cortex-A57 1.08 1.02 1.05 (OoO, Nintendo Switch)
Cortex-A76 1.00 1.18 1.09 (OoO, RPi 5)
https://www.7-cpu.com/ (source of 7-Zip benchmark results)
https://blog.bitsofnetworks.org/riscv-performance-power-usage/ (claim VisionFive 2 series 7 CPU cores have +20% performance/MHz vs Unmatched based on decompression benchmarks)
https://amigaworld.net/modules/newbb/viewtopic.php?topic_id=44391&forum=25#847418 (Bytemark results showing 68060 +40% int performance/MHz vs P5 Pentium)
Note: The performance efficiency (performance/MHz) of the in-order PPC Cell, in-order Atom and OoO PPC G5 were reduced by deep pipelines to allow higher clock speeds. While the Intel Atom and Cortex-A9 lack performance efficiency for good single core/thread performance, they were #1 and #2 respectively for least energy used in https://www.extremetech.com/extreme/188396-the-final-isa-showdown-is-arm-x86-or-mips-intrinsically-more-power-efficient benchmarks. Super pipelining is no longer necessary to achieve reasonably high clock speeds so more practical approximately 8-stage pipelines like the 68060 have become more common, especially for in-order embedded cores where latencies and jitter become more important to minimize.
Last edited by matthey on 08-Jun-2026 at 05:11 AM.
Last edited by matthey on 08-Jun-2026 at 04:29 AM.
Last edited by matthey on 08-Jun-2026 at 04:22 AM.
Last edited by matthey on 08-Jun-2026 at 12:40 AM.
|
| | Status: Offline |
| | matthey
| |
Re: RGL, Amiga Corp & Atari partner Plaion to produce NeoGeo AES+ using ASICs
Posted on 8-Jun-2026 21:46:13
| | [ #50 ] |
| |
|
Elite Member
|
Joined: 14-Mar-2007
Posts: 2925
From: Kansas | | |
|
| Metro Siege Kickstarter raising more funds from NeoGeo market than Amiga or PC market. Perhaps there is an advantage to having new and supported hardware rather than old dying and virtual hardware?
Neo Geo
Neo Geo AES Edition â¬323 x19 = â¬6137
Neo Geo AES Ultimate Edition â¬365 x14 = â¬5110
Early Neo Geo AES Edition â¬318 x5 = â¬1590
Early Neo Geo AES Ultimate Edition â¬360 x5 = â¬1800
---
NeoGeo AES subtotal â¬14817
Neo Geo MVS Edition â¬285 x0 = 0
Neo Geo MVS Ultimate Edition â¬318 x0 = 0
Early Neo Geo MVS Edition â¬280 x5 = â¬1400
Early Neo Geo MVS Ultimate Edition â¬313 x5 = â¬1565
---
NeoGeo MVS subtotal â¬2965
===
NeoGeo total â¬17782
Amiga
Amiga DVD Case CD Edition â¬39 x14 = â¬546
Amiga Boxed CD and USB Key Edition â¬55 x20 = â¬1100
Amiga Boxed Floppy Disk Edition â¬73 x7 = â¬511
Amiga Boxed Collector's Edition â¬86 x4 = â¬344
Amiga Boxed Ultimate Edition â¬108 x15 = â¬1620
Early Amiga DVD Case CD Edition â¬34 x5 = â¬170
Early Amiga Boxed CD and USB Key Ed. â¬50 x5 = â¬250
Early Amiga Boxed Collector's Ed. â¬80 x5 = â¬400
Early Amiga Boxed Ultimate Edition â¬103 x5 = â¬515
===
Amiga total â¬5456
Universal
Metro Siege Digital Edition â¬13 x109 = â¬1417
Metro Siege Digital Collector's Edition â¬43 x2 = â¬86
Metro Siege Digital Ultimate Edition â¬82 x0 = 0
Early Digital Ultimate Edition â¬77 x4 = â¬308
Early Digital Collector's Edition â¬39 x5 = â¬195
===
Universal total â¬2006
https://www.kickstarter.com/projects/metrosiege/metro-siege
https://amigaworld.net/modules/newbb/viewtopic.php?topic_id=45869&forum=9
The Neo Geo cartridges have a much higher price and the Neo Geo wait until release is longer yet new hardware has clearly rejuvenated the Neo Geo AES market. The 68k Amiga market is treated as a 2nd class citizen again with only a 68000 ECS 1 MiB spec, no guarantee of even a 68020 AGA 2 MiB spec version and obvious inferiority to the Neo Geo version. Commodore treated the 68k Amiga as non-upgradeable planning to replace it instead and A-EonKit treated the 68k Amiga as a 2nd class citizen to PPC AmigaNOne. SNK and Plaion treated the Neo Geo as the king of consoles and it is back as a result, despite the 68k Amiga being much more upgradeable, expandable and flexible. Cheap virtual 68k Amigas receive a RPi 1 level of scalar CPU performance but without the low power, small footprint or cheap price. The Neo Geo, C64 Ultimate and Acorn Archimedes on the RPi get ultimate upgrades while the 68k Amiga gets the Commodore treatment all over again.
Last edited by matthey on 08-Jun-2026 at 09:47 PM.
|
| | Status: Offline |
| | kolla
| |
Re: RGL, Amiga Corp & Atari partner Plaion to produce NeoGeo AES+ using ASICs
Posted on 8-Jun-2026 22:14:51
| | [ #51 ] |
| |
|
Elite Member
|
Joined: 20-Aug-2003
Posts: 3593
From: Trondheim, Norway | | |
|
| @matthey
You ruin your own chaln of reasoning by using A600GS as an argument, Amiberry isnât a 68k emulator, itâs an Amiga emulator. So apparently your agree that AmigaOS doesnât rely on parallel execution of code of the sorts you keep bringing up, and that this isnât critical at all compared to chipset etc, you just use wall-of-text approach to disguise it. _________________
B5D6A1D019D5D45BCC56F4782AC220D8B3E2A6CC |
| | Status: Offline |
| | matthey
| |
Re: RGL, Amiga Corp & Atari partner Plaion to produce NeoGeo AES+ using ASICs
Posted on 9-Jun-2026 4:57:47
| | [ #52 ] |
| |
|
Elite Member
|
Joined: 14-Mar-2007
Posts: 2925
From: Kansas | | |
|
| @kolla
Amiga emulation without 68k emulation is AmigaNOne emulation, best known for dividing and sabotaging the Amiga market after horrible value AmigaNOne hardware failed in the Amiga market. As far as parallelism, emulation uses a CPU core which provides sequential execution as I stated previously. The CPU providing the emulation is working on emulating the 68k CPU or chipset with brute force by switching between emulating them. There is minimal if any parallelism between the CPU and chipset, no Amiga DMA, no asymmetric multiprocessing architecture, no message driven with wait based preemptive multitasking, no efficient 68k CPU design, 68k CPU ILP is replaced by brute force OoO execution, 68k super code density is replaced by several times larger code than already fetch bottlenecked fat RISC ISAs and no elegance 68k Amiga design remains. A virtual 68k Amiga is as much of an AmigaNOne as PPC AmigaNOne hardware and even less elegant as more brute force sequential processing and CPU polling is used. PPC AmigaNOne hardware uses DMA, parallel GPUs, message driven wait based preemptive multitasking and CPUs operating in parallel with more ILP. The Amiga is a 68k CPU, Amiga chipset and the AmigaOS or it is not compatible and the Amiga masses flee though. It is no different than the Commodore guys trying to bait and switch a PC with Linux Commodore OS for the C64 market except that the Commodore guys payed for their used IP and A-EonKit never relented at trying to jam a market failure down customer throats. Perhaps SNK and Plaion learned from the A-EonKit and Commodore mistakes and got it right the first time with the Neo Geo AES+.
|
| | Status: Offline |
| | minator
| |
Re: RGL, Amiga Corp & Atari partner Plaion to produce NeoGeo AES+ using ASICs
Posted on 9-Jun-2026 14:15:22
| | [ #53 ] |
| |
 |
Super Member
|
Joined: 23-Mar-2004
Posts: 1049
From: Cambridge | | |
|
| Wrote a reply here but apparently posting is broken... Last edited by minator on 09-Jun-2026 at 02:17 PM.
Last edited by minator on 09-Jun-2026 at 02:17 PM.
Last edited by minator on 09-Jun-2026 at 02:16 PM.
Last edited by minator on 09-Jun-2026 at 02:15 PM.
_________________
Whyzzat? |
| | Status: Offline |
| | minator
| |
Re: RGL, Amiga Corp & Atari partner Plaion to produce NeoGeo AES+ using ASICs
Posted on 9-Jun-2026 19:50:41
| | [ #54 ] |
| |
|
Super Member
|
Joined: 23-Mar-2004
Posts: 1049
From: Cambridge | | |
|
| Will try again...
CISC may make code smaller but has an opposite effect on silicon. In fact it has an enormous cost on silicon area and complexity.
The 060 was $308
The MIPS R4200 had similar performance and lower power (about 2W) at around $50.
2 years later the StrongARM gave 2x the performance, required under 0.5 Watts and cost $29.
The 060 was very RISCy for a CISC chip and a worthy end to the 68K line, but RISC outperformed it at the high end and undercut it at the low end.
Last edited by minator on 09-Jun-2026 at 07:51 PM.
_________________
Whyzzat? |
| | Status: Offline |
| | matthey
| |
Re: RGL, Amiga Corp & Atari partner Plaion to produce NeoGeo AES+ using ASICs
Posted on 10-Jun-2026 20:34:55
| | [ #55 ] |
| |
|
Elite Member
|
Joined: 14-Mar-2007
Posts: 2925
From: Kansas | | |
|
| minator Quote:
CISC may make code smaller but has an opposite effect on silicon. In fact it has an enormous cost on silicon area and complexity.
|
Caches/SRAM use more transistors than CPU core instruction pipelines already for MIPS CPUs back in the 1990s.
NEC Unveils New MIPS Chip for Nintendo (Microprocessor Report May 8, 1995)
https://www.cecs.uci.edu/~papers/mpr/MPR/ARTICLES/090601.pdf Quote:
The die photo in Figure 2 shows that the R4300 core logic consumes a relatively small part of the die compared with the caches and the TLB. This is an increasingly common situation as processor cores get smaller and instruction bandwidth becomes critical to achieving competitive performance. The R4300 is fabricated on the same line as the R4100 and the 200-MHz version of the R4400, using a state-of-the-art 0.35-micron process with three metal and two poly layers. With the volume represented by the Nintendo design win, NEC was prudent in deciding to manufacture the R4300 in the smallest possible process to get the lowest per-piece price, and to amortize the high initial cost of the process over the life of the part
|
Even relatively small MCUs today that cost less than $1 USD like the RP2040 and RP2350 use far more transistors for SRAM alone than a whole 68060 CPU including caches. High performance CPUs/SoCs today have multi-level caches with more MiB of caches than the Amiga had main memory. A whole 68060 Amiga system could be turned into a MCU using SRAM for main memory instead of caches. Some RISC-V SiFive SoCs, using in-order series 7 CPU cores similar to the 68060 design, allow to turn the caches into SRAM memory effectively turning the SoC into a MCU. The 2 MiB L2 cache of the SoC on the sub $100 USD VisionFive 2 SBC uses ~100,663,296 transistors which is interesting considering the 68020+AGA+2MiB standard was the last 68k Amiga standard. The transistor count would be with the most common 6T SRAM which uses 6 transistors per bit of SRAM and excludes tags. Some fab processes allow to use 4T SRAM and DRAM using fewer transistors is sometimes used for higher level caches but also 8T SRAM is sometimes used to reduce power.
minator Quote:
The 060 was $308
The MIPS R4200 had similar performance and lower power (about 2W) at around $50.
2 years later the StrongARM gave 2x the performance, required under 0.5 Watts and cost $29.
|
Most early MIPS CPUs like the R4200 were not superscalar and neither was StrongARM. High clocked scalar RISC CPUs were a strategy that failed due to a higher power increase with more heat than expected and the RISC instruction fetch bottleneck. StrongARM was professionally developed by DEC and had power management innovations but StrongARM was weak performance per MHz, reducing the voltage reduces max clock speeds and DEC eventually failed with Alpha due to the same RISC problems. MIPS cores were more academic experiments in comparison, introducing other major handicaps like load delay slots with no hardware pipeline interlocks (MIPS stands for Microprocessor without Interlocked Pipelined Stages), branch delay slots and other problems due to extreme simplification of both the ISA and CPU designs.
https://retrocomputing.stackexchange.com/questions/17598/did-any-cpu-ever-expose-load-delays Quote:
@PeterCordes It is really just a set of comperators (or multiple with longer pipelines, but the MIPS I one wasn't such). The special handling of Mult/Div is result of a schizophrenic situation. On one hand, the the goal was to create a true single cycle instruction CPU, but also wanting to include Mult/Div as basic instructions, even though they do not fit that scheme. RISC, and most notably MIPS in its early stages, had more common with a cult preaching its sermon than engineering. The dogma is absolute, they rather shoot themself in the foot than acknowledging that real life is different.
â Raffzahn Commented Jan 10, 2021 at 17:17
Yeah, RISC philosophical purity taken to extremes. At least MIPS has the excuse that it literally started as an academic project to test the validity of the "RISC = good" hypothesis. Some later machines made engineering decisions while drinking more or less of the kool-aid. (e.g. ARM takes the good ideas but maintains high code density.)
â Peter Cordes Commented Jan 10, 2021 at 17:42
|
MIPS CPUs were a la carte like ARM so there was minimal standardization and reduced performance and compatibility between designs. Transitioning to deeper pipelines and superscalar cores was problematic. A new ASIC for the MIPS consoles would likely require a different MIPS CPU core for each console while a 68060 is already supported by the Amiga/CD32, Atari ST, X68000, 68k Mac and Sinclair QL with awesome superscalar performance of ~50% multi-issue rate with "existing 680X0 code". Now lets do some comparisons.
CPU | type | pipeline | L1 caches | transistors
R2000 scalar 5-stage none 110,000
R3000 scalar 5-stage none 115,000
R3051 scalar 5-stage 4kiB-i 1,000,000 (PS1)
R4000 scalar 8-stage 8kiB-i/8kiB-d 1,200,000
R4200 scalar 5-stage 16kiB-i/8kiB-d 1,300,000
(V)R4300 scalar 5-stage 16kiB-i/8kiB-d 1,700,000 (Nintendo 64)
R5900 in-order 6-stage 16kiB-i/8kiB-d 13,500,000 (PS2 & PSX)
The R4000 on are 64-bit but often with 32-bit data busses for consoles and embedded use. The 68060 also has a 32-bit data bus. The console MIPS cores have many customizations increasing the transistors beyond just the MIPS CPU core. MIPS claimed a 7% transistor increase for 64-bit with the R4000 which likely increases with more core complexity (I expect a 5%-15% transistor increase). MIPS favored superpipelining the R4000 over superscalar operation which adds pipeline stages increasing transistors but not as much as a superscalar core.
The MIPS R4000 Processor (IEEE Micro 1992)
https://people.eecs.berkeley.edu/~kubitron/courses/cs252-S07/handouts/papers/R4000.pdf Quote:
The hardware cost of extending the architecture to 64 bits was about 7% of the die area. A longer, 64-bit ALU stage represents the cycle time speed penalty.
CPU pipeline
The R4000's 8 pipeline stages allow it to process more instructions at once than can the R3000's 5-stage pipeline. Superpipelining has split the instruction and data memory references across 2 stages. Consequently, we could distribute the logic more evenly across pipeline stages (see Figure 2). The single-cycle ALU stage takes slightly more time than each of the cache access stages.
Although the superpipeline increases the cycles per instruction due to longer branch and load delays, it greatly improves the achievable cycle time. Further increases in cache size will not require a fundamental redesign of the superpipeline. We considered superscalar design as another way to increase instruction-level parallelism, but our studies showed that with current technology the chip could perform higher with a less complex superpipeline.
|
Superpipelining is easier, cheaper in transistors/area, has more consistent instruction supply and fits better with RISC high CPU core clock speed goals but was sabotaged by MIPS and early RISC mistakes. The superpipeline "longer branch and load delays" increased from 1 cycle for the R3000 to 2 cycles each for the R4000. Early MIPS cores did not have pipeline interlocks to save transistors so a single NOP was placed in the code when no independent instruction was available resulting in much increased code size and pipeline interlocks were added to make the pipeline stall instead. With the R4000 superpipeline, there could be 2 cycle "branch and load delays" and earlier optimized MIPS code was highly likely to stall for at least 1 cycle at branches and loads. The 1st mistake was having a separate load/store unit pipeline from integer ALU pipeline which was finally fixed with the MIPS replacement RISC-V SiFive series 7 CPU core design that resembles the 68060 design, is also 8-stage and removes load delays completely, also called load-use delays and load-to-use delays. A Superscalar core increase the number of independent instructions which need to fill the load bubbles so, for example, the Cortex-A53 with a 3 cycle load-to-use delay needs 6 independent instructions between a load and the instruction which uses the result to avoid stalling. The 2nd mistake was the use of branch delay slots which was another common RISC mistake. Once again, rather than add bubbles into the pipeline that would stall, instructions were added after the branch which would be executed instead. The longer pipeline increases branch penalties meaning older optimized MIPS code stalls for a cycle. The CISC way to solve this problem is dynamic branch prediction and speculative execution while the RISC simplification philosophy saved transistors. The R4000 did not add dynamic branch prediction and its static branch prediction assumes branches are not taken so it stalls a lot and has bad performance for performance critical loops. Many later MIPS designs, including for consoles, went back to the scalar 5-stage RISC pipeline which was simple and small but did not scale up in performance. The 68060 design solved the load and branch problem while upgrading to an 8-stage superscalar pipeline with good branch prediction using both dynamic and static prediction. It has zero cycle loads, it folds branches that remove the branch itself from execution for critical loop performance, it has ~90% branch prediction, it has embedded market leading code density that allows ~50% multi-issue rate from a 4 byte/cycle fetch where superscalar operation is not possible with most other ISAs, it has efficient caches due to code density and better associativity than most early MIPS cores, it does not use multiplexed buses unlike most early MIPS cores and it has amazing performance with 68k code that existed before the 68060. The 68060 design is brilliant and the CPU/core is not large considering the performance features.
So lets do a comparison of 68060 to early MIPS/RISC cores based on transistors/area. We will start by looking at some other early CPUs to compare to the MIPS cores above.
Year | CPU | transistors
1975 6502 3,500
1979 68000 68,000
1984 68020 190,000
1985 ARM1 25,000
1985 80386 275,000
1986 ARM2 30,000
1987 68030 273,000
1990 68040 1,170,000
1993 Pentium 3,100,000 superscalar in-order 2-way
1994 68060 2,530,000 superscalar in-order 2-way
1994 ARM7 250,000
1995 5x86 2,000,000
1995 6x86 3,000,000 superscalar in-order 2-way
1995 PentiumPro 5,500,000 OoO uop
2002 ARM11 7,500,000
2008 Nehalem 731,000,000 (1st gen Core i7 with 4 cores) 64-bit OoO uop
2011 Cortex-A7 10,000,000 superscalar in-order 2-way
2012 Cortex-A53 12,500,000 64-bit superscalar in-order 2-way
2012 Cortex-A57 75,000,000 64-bit OoO 3-way big.LITTLE companion of Cortex-A53
I added in the Cyrix 5x86 and 6x86 which is the scalar and superscalar versions of a similar design to the 68060, original P5 Pentium and RISC-V SiFive series 7 designs. A down scaled 68060Lite scalar 68060 was also proposed for the modular 68060 design along with an up scaled 68060+ with double the caches. Cyrix claimed a 40% cost for superscalar.
Cyrix 5x86: Fifth-Generation Design Emphasizes Maximum Performance While Minimizing Transistor Count
https://dosdays.co.uk/media/cyrix/5x86/5X-DPAPR.PDF Quote:
5x86 Architecture
The increased complexity, transistor count, and power consumption of superscalar designs led Cyrix engineers to re-examine the benefits of the superscalar approach. Clearly the power dissipated in a second execution pipeline plus the added power dissipated in the control logic to oversee two execution pipelines should be minimal to achieve performance that will justify the transistors added. Analysis has shown that the increased complexity of two execution pipelines can cost 40% in transistor count while providing an increase of less than 20% in instructions-per-clock performance.
|
The difference between 5x86 and 6x86 is ~33% from info I could find on transistor counts but cache sizes may vary and I do not know if they are included. The "increase of less than 20% in instructions-per-clock performance" is likely x86 and cache specific. Larger and more efficient caches means fewer performance killing cache miss stalls. The 68k has considerably better code density, a more orthogonal ISA allowing for more instructions to execute in parallel with fewer transistors and I expect the performance gain from the longer pipeline and superscalar execution to have synergies.
68060
SpecInt92 49@50MHz
1.8 DMIPS/MHz
CPI 1.2 (measured by Moto on a range of desktop and embedded applications)
https://www.cecs.uci.edu/~papers/mpr/MPR/ARTICLES/080502.pdf
https://old.hotchips.org/wp-content/uploads/hc_archives/hc06/3_Tue/HC6.S8/HC6.8.3.pdf
R4000
SpecInt92 39@50MHz 8kiB I+D & no L2
1.5 DMIPS/MHz 8kiB I+D & no L2
CPI 1.54 Spec92int
https://people.eecs.berkeley.edu/~kubitron/courses/cs252-S07/handouts/papers/R4000.pdf
https://blog.jyotiprakash.org/delving-deeper-into-the-mips-pipeline
The 68060 has better performance of 26% for SpecInt92, 20% for DMIPS/MHz and 28% for CPI. I expect the MIPS code for the R4000 needed considerably more optimization and tuning for these results. The 68060 had poor compiler support but was very tolerant of bad code due to stall mitigations and dynamic branch prediction. Now for some core area/transistor sizes with adjustments.
68060 2,530,000 transistors
-40% for superscalar to 1,518,000
-?% for dynamic branch prediction
R4000 1,200,000 transistors
-7% for 64-bit to 1,116,000
+98% for +24kiB instruction cache matching 68060 hit rate to 2,379,648
That 24kiB of extra instruction cache to quadruple the L1 instruction cache size uses 1,179,648 transistors with 6T SRAM. This comes from RISC-V research.
The RISC-V Compressed Instruction Set Manual
https://www2.eecs.berkeley.edu/Pubs/TechRpts/2015/Archive/EECS-2015-209.pdf Quote:
Benefiting from 25 years of hindsight, RISC-V was designed to support compressed instructions from the outset, leaving enough opcode space for RVC to be added as a simple extension on top of the base ISA (along with many other extensions). The philosophy of RVC is to reduce code size for embedded applications and to improve performance and energy-efficiency for all applications due to fewer misses in the instruction cache. Waterman shows that RVC fetches 25%-30% fewer instruction bits, which reduces instruction cache misses by 20%-25%, or roughly the same performance impact as doubling the instruction cache size.
|
The MIPS replacement RISC-V people figured out that code density is important even though they have not matched 68k code density yet and they borrowed a 68060 like CPU design to eliminate load-to-use stalls with the SiFive series 7 CPU core design even though they can not execute as powerful of instructions because of the weak RISC-V ISA. RISC seems to be about self inflicted handicaps and RISC philosophy followers stuck in the past.
minator Quote:
The 060 was very RISCy for a CISC chip and a worthy end to the 68K line, but RISC outperformed it at the high end and undercut it at the low end.
|
In Amiga Bill's interview of Joe Circello, someone asked Joe a question kind of like whether the 68060 breaks down instructions to RISC like micro-ops and actually has a RISC execution pipeline inside as some people think is the case for x86(-64) cores too. The 68060 does not waste transistors and power breaking down instructions into micro-ops and the superscalar execution pipelines are executing powerful CISC instructions accessing cache/memory in a single cycle. It is doing all this without microcode which every x86(-64) core design I am aware of including the Cyrix CPUs/cores above are using. Add in code density on par with Thumb-2 that is still embedded market leading but can be improved, and it looks like abandoned futuristic tech that should not have been abandoned like Roman concrete that rarely cracks and ancient wall and pyramid building tech that is highly earthquake resistant. Joe Circello made statements about RISC mistakes and RISC-V people relearning lost knowledge as he wears a RISC-V shirt and jokes about it.
Inside the Motorola 68060 & Chip Design: Interview with Lead Designer Joe Circello!
https://www.youtube.com/watch?v=1takr2k7Yfo
I do not know if Joe is even aware of how good and far ahead of its time the 68060 was. The price efficiency was sabotaged by not clocking it up but it was still a market success for embedded use. The tech needs to be scaled up for better performance instead of castrating it and scaling it down into ColdFire. The 68k is more difficult to pipeline than x86 but I believe it can be more powerful and more power efficient and the 68060 is proof that it can be successfully pipelined. The 68060 still has performance advantages over the P5 Pentium, Cyrix 6x86 and SiFive Series 7. The only question is how well it can be clocked up with its deep for the time 8-stage pipeline and that was a question Joe was not asked in the interview.
CPU max clock rating @ ~500nm process size with pipeline stages and MHz/stage
ARM710@40MHz 3-stage 13MHz/stage
PPC601+@120MHz 4-stage 30MHz/stage
PPC603@160MHz 4-stage 40MHz/stage
Pentium P54C@120MHz 5-stage 24MHz/stage
PPC604@180MHz 6-stage 30MHz/stage
X704@~500MHz 6-stage 83MHz/stage
HP PA-8000@180MHz 7-stage 26MHz/stage
Alpha 21064@300MHz 7-stage 43MHz/stage
MIPS R4400@200MHz 8-stage 25MHz/stage
68060@50MHz 8-stage 6MHz/stage
Average MHz/stage: 32MHz/stage

I do not believe the problem was technical. Low end PPC cores used shallow pipelines and static branch prediction to save area and power too. The PPC603(e) core design did not get deeper pipelines and dynamic branch prediction until the PPC G3 in 1997. The PPC was designated for high end embedded use and the 68k/CF was designated for low end use below where fat PPC would scale. Sadly, Moto did not know the RISC-V research even as they had to quickly double the caches of PPC603 with only 1.8 million transistors into the PPC603e now using 2.6 million transistors, more transistors than the 68060 and still not reaching the instruction cache performance. The 68060 also has a deeper pipeline for clocking up more, more superscalar processing units and dynamic branch prediction which explains why it could not be clocked up. Can you imagine telling Steve Jobs that the 68k he abandoned is reaching the clock speeds he demanded of PPC? Would it have been easier to switch back to the big endian 68k rather than to little endian x86? Is Trevor making the same mistake as Steve with PPC, too arrogant to look back and correct mistakes?
Last edited by matthey on 10-Jun-2026 at 10:20 PM.
Last edited by matthey on 10-Jun-2026 at 08:58 PM.
Last edited by matthey on 10-Jun-2026 at 08:56 PM.
Last edited by matthey on 10-Jun-2026 at 08:49 PM.
|
| | Status: Offline |
| | kolla
| |
Re: RGL, Amiga Corp & Atari partner Plaion to produce NeoGeo AES+ using ASICs
Posted on 11-Jun-2026 22:19:20
| | [ #56 ] |
| |
|
Elite Member
|
Joined: 20-Aug-2003
Posts: 3593
From: Trondheim, Norway | | |
|
| @matthey
Why are you arguing with yourself? Why do you stack your reasoning backwards? My point is simple: emulating the 68k CPU while keeping the chipset - be it "real" or FPGA - separate, as we do with PiStorm/Emu68, has advantages over emulating the entire Amiga in software. Of course, this advantage only exists in so far you actually _use_ the chipset, once youâre only using P96 and AHI those advantages are gone and you may just as well stick to plain software emulation. So exactly why do you insist that software emulation of _just_ the CPU is "bad", and then drag in UAE variants - where CPU _and_ chipset are emulated, sequentially - as an argument? Yes, (classic) Amiga needs 68k, but whether that CPU is implemented in software emulation or hardware is of very little importance compared to whether the chipset too is emulated in software or hardware.
So, next giant wall of (repetitive, irrelevant, pointless) text coming up, I guess⦠_________________
B5D6A1D019D5D45BCC56F4782AC220D8B3E2A6CC |
| | Status: Offline |
| | matthey
| |
Re: RGL, Amiga Corp & Atari partner Plaion to produce NeoGeo AES+ using ASICs
Posted on 13-Jun-2026 0:48:33
| | [ #57 ] |
| |
|
Elite Member
|
Joined: 14-Mar-2007
Posts: 2925
From: Kansas | | |
|
| @kolla
I understand the strategy and logic which is valid but it is still an overall fail for the 68k Amiga market. Yes, a sequential CPU can emulate a CPU better than a FPGA, a more parallel logic FPGA can simulate a chipset better than a CPU and both together can work in parallel with synergies but this does not create a competitive product. The problem is that an emulated CPU is nowhere near competitive as I explained. An ASIC CPU and FPGA chipset may be competitive enough for retro, hobby and low end embedded use, between low end RPi SBCs and RPi MCUs. Scaling up requires a 3D GPU and while FPGAs can perform parallel GPU workloads well, the price efficiency (performance/$) is nowhere near competitive with an ASIC either. Looking at the big picture, an ASIC is needed to be competitive with RPi like hardware. There is no other winning strategy to successfully proliferate using the hot retro 68k market as a catapult. SiFive understood and the RISC-V VisionFive 2 SBC is competitive enough with RPi hardware to remain on the market for 3.5 years with a relatively new ISA using an ASIC SoC even though the memory footprint does not match RPi's 32-bit Thumb-2 hardware and there is a lack of pre-compiled software, especially games. Plaion and SNK understood with the development of the NeoGeo AES+ even though a console without OS has limited CPU performance gains of ~100% with good compatibility while the 68k Amiga/CD32, Atari ST, X68000, Mac 68k and SinclairQL already support the 68060 and a semi-modern 68060 could be ~1,000% to ~10,000% better performance, massively increasing the value. The NeoGeo AES+ quick FPGA to ASIC conversions have limitations and hardware competitiveness closer to a FPGA than a competitive ASIC. From what I have comprehended from developers, the ASICs gained better 5V tolerance and more pins for the cartridge slot while the cost reduction is secondary.
Interesting console news...
Microsoft has considered spinning off Xbox, the Information reports
https://www.reuters.com/business/microsoft-has-considered-spinning-out-xbox-information-reports-2026-06-12/ Quote:
Xbox has struggled in recent years as âMicrosoft's bet on subscriptions and cloud gaming failed to offset âdeclining console sales and a shortage of blockbuster titles.
|
The strategy of "subscriptions and cloud gaming failed". The businesses behind the major consoles have tried to create consistent revenue streams (cash flow). This may work for wealthier users as Apple has been successful with it but some gamers do not want to lose their software investments if they can not pay their subs or a business goes under. Collectors of systems like the NeoGeo AES+ can sell their game collections which often have more value than the hardware. Locked down very closed consoles also limit what users can do with their powerful general purpose capable hardware. The NeoGeo AES+ is a niche retro console that will likely sell in the hundred of thousands if not low millions of units but it has too expensive of cartridges, not enough performance and not enough flexibility for a more open and general purpose mini-console. More than likely, end of Amiga leaders will continue to have their heads stuck in the sand while RPi introduces a RPi mini-console grabbing that market too like they did with the small footprint hardware market that the 68k Amiga is better suited for.
|
| | Status: Offline |
| | cdimauro
| |
Re: RGL, Amiga Corp & Atari partner Plaion to produce NeoGeo AES+ using ASICs
Posted on 13-Jun-2026 9:39:19
| | [ #58 ] |
| |
 |
Elite Member
|
Joined: 29-Oct-2012
Posts: 4645
From: Germany | | |
|
| @matthey
Quote:
matthey wrote:
cdimauro Quote:
I've finally had time to watch the entire video. Videogames weren't interesting, because most of them were ports which are better on other platforms.
Videogames are THE business reason for "revivals" like what we're discussing now. So, a "MiniQL" remains not interesting.
|
Games are the primary reason for retro gaming system revivals, especially for gaming focused systems like consoles, but they are not the only reason. Nostalgia for older users includes the experience, visuals, history, developers & development, all software including productivity and OS, demos, etc. Younger users receive an education and a history lesson as they play around and discover things they did not know about. Minis have missed much of the nostalgia market due to their cheap and limited hardware. |
OK, but old applications for such very old systems don't require Ghz machines to obtain a much better user experience with this kind of software (games usually don't need faster hardware. On the exact contrary, they need the exact hardware to avoid glitches/issues).
You can pump a lot their emulated processors even on cheap FPGA systems, offering a vastly superior experience.
Quote:
Emulators have done a better job with the extras. For example, Amiga Forever comes with many extras that are not games.
Amiga Forever extras
~96 games
~111 demos
10 gallery items (Amiga-Atari: "Lorraine" overview, first demos, Amiga 1000 cover, etc.)
10 videos (historic like Jay Miner interviews, Launch of Amiga, the Deathbed Vigil, etc.)
Some of the extras are on DVD which could optionally use streaming from internet but Minis support neither. |
I don't see applications...
Quote:
| Sadly, most stand alone retro hardware is severely lacking in more ways than the emulation for PCs which is not accurate |
Emulation could not be accurate only because the precise specs / schematics aren't available.
There's nothing, theoretically, which prevents emulation to be perfect.
Either you decide to emulate a system in software (via regular processors) or in hardware (FPGA), or don't go through emulatation at all (ASIC), you require its complete schemas in order to have a perfect replica of the original.
Quote:
| and a different experience due to Windows. |
You can boot Windows very very fast nowadays, and directly start an emulator instead of a regular Explorer.
Same for Linux-based systems (including those Mini consoles/computers).
However, I understand your point.
Quote:
| Better value, while retaining Mini like prices for stand alone hardware, can be achieved with ASICs like the NeoGeo AES+ demonstrates. Much better value can be achieved for stand alone systems which allow to increase performance by many times. The same 68k ASIC SoC could be used to support multiple systems further increasing value while increasing mass production potential to reduce prices. |
Right. IF you've the a good volume then an ASIC is much cheaper than any emulation-based system, for obvious reasons.
Specifically, you need to embedded several cores for retro purposes. To support several 68k systems then you need at least:
- a 68000 (better if it can support a 68010, and you can select at boot time if you want a 68000 or a 68010) with perfect cycle timings / behavior;
- a 68020 (cycle timings are important, but they can be less precise here). Better if it can support a 68030 as well (selectable at boot time, of course), since they are very similar;
- a super fast 68040/68060 (selectable at boot time).
I propose to add another not-cycle-exact 68000 or 68020 (the cheapest to implement) as a "system processor", only used for controlling the entire platform and to implement the GUI / user interface with OSD graphics etc..
Since retro systems have other processors from different families, it'd be good to provide some cores of them (6502/6510/8502, 8085, 8086, z80, z180, ...) as well.
ASICs are VERY convenient because they can use several million transistors and yet they cost a single dollar, or even less.
So, all of the above is certainly doable, but it requires some experts to work on it and design this retro platform in a manner that it's usable to emulate most of the systems. Which means that the ASIC should also provide some "basic blocks" like embedded memories which are available and usable depending on the system to emulate.
Another important thing is regulating the priorities on accessing the memory by the various components. As we know, retro simulation requires very precise timings, and the above cores need to be carefully controlled on when and how they can access the memory. I've no idea on how to do it, because there are plenty of systems which exists, and they have their own quirks (Amiga has its own due to the chip mem vs chipset vs fast mem).
Anyway, ON PAPER it's possible to design a single, very cheap, ASIC which can support multiple systems, and that provides much better value compared to any existing solutions. But IMO it's very difficult to design and implement it.
Quote:
cdimauro Quote:
Yes, some of them were interesting (I've played Dark Castle on a Mac Plus, when I was a guest at the Wesleyan University, on 1988). Yet, limited and not much compelling. Many of them had better versions for other platforms.
|
I hear the ports are better on other platforms argument but different platforms have the best ports or desirable features for each game. Some platforms are getting more enhanced games and are easier release targets. The 68k Amiga had enhanced games for AGA/CD32 but there have been other enhanced games since then.
enhanced & re-released original Amiga games
DungeonMaster - Meynaf's patches include features from other ports and new levels
Worms DC v1.5 30th anniversary
Turrican II: The Final Fight (AGA)
Banshee AGA
Double Dragon AGA
Rick Dangerous Enhanced (AGA)
Renegade: Enhanced (AGA)
Final Fight: Enhanced (AGA)
Out Run: Amiga Edition (AGA)
Super Cars 2 (AGA)
recent Amiga game ports & re-releases that would benefit from more performance
Alien Breed 3D (AGA/RTG) - many patches
Quake (AGA/RTG) - continues to be developed for the Amiga
The Settlers II (AGA/RTG)
Star Wars: Dark Forces (AGA/RTG)
Amispear (ECS/AGA/RTG)
Doom RPG (AGA/RTG)
Heart of Darkness (RTG)
Heart of the Alien (ECS/AGA/RTG/CD)
Ultima VII Exult (AGA/RTG)
Mini Slug (RTG)
Death Rally (AGA/RTG)
Exhumed / Powerslave (AGA/RTG)
Blood (AGA/RTG)
Older but ~2000+: Descent Freespace, Quake II, Payback, Heretic II, Hexen, Foundation: Gold, Descent, Genetic Species, OnEscapee, Myst
games which could be released for the 68k Amiga with more performance
Wipeout rewrite/enhanced
Shogo: Mobile Armor Division
Wings Remastered Edition
Tower57
Gorky17
Legend of Grimrock I & II - Indie games by former Amiga game programmers
newer UFO enemy unknown ports
OpenRedAlert
Return to Castle Wolfenstein
Quake III Arena
Dungeon Keeper
I am just scratching the surface with popular games. Some other 68k systems have significant development too like for the Sega Genesis despite the cartridge limitation. |
I see, but they aren't many, especially if we consider that many of them can already be played on other systems, with even better experience.
Anyway, a retro-ASIC can offer similar enhancements "for free".
Quote:
cdimauro Quote:
OK, but this doesn't answer my original question: aren't the current solutions able to run such 20-40 games with much better performance?
|
Yes, 68k emulation using ARM SoCs with in-order CPU cores have better performance than original spec 68k hardware standards. However, ARM hardware has no production cost advantage but actually a cost disadvantage due to royalties. A 68k ASIC SoC with 68060 like in-order cores at a similar clock speed using a similar chip process should have a similar or lower production cost while providing much more performance for 68k software without emulation. It would be possible to give access to the ARM/Linux side of emulation hardware to run ARM compiled games natively at higher performance but that is not how most ARM/Linux stand alone emulation systems works and it loses the advantage of standard hardware/OS, unless it is a RPi, and even then it is not as standard or as small of footprint as a 68k Amiga without emulation could be.
|
Are you sure that a commercial "retro-platform" (like the one which I've proposed above) has no royalties to pay to any CPU vendor? |
| | Status: Offline |
| | cdimauro
| |
Re: RGL, Amiga Corp & Atari partner Plaion to produce NeoGeo AES+ using ASICs
Posted on 13-Jun-2026 9:42:25
| | [ #59 ] |
| |
|
Elite Member
|
Joined: 29-Oct-2012
Posts: 4645
From: Germany | | |
|
| @matthey
Quote:
matthey wrote:
Has someone been listening to me finally?
Why ASIC technology could start the next Amiga hardware revolution
https://www.generationamiga.com/2026/05/14/why-asic-technology-could-start-the-next-amiga-hardware-revolution/ Quote:
...
The arrival of modern systems such as the Neo Geo AES+ has shown that retro hardware does not have to choose only between original machines, software emulation and FPGA recreation. There is another path: newly manufactured, purpose-built silicon designed to reproduce classic hardware as a stable product rather than a flexible approximation. For the Amiga, that path is not merely attractive. It may be necessary.
|
The 68k Amiga continues a slow death without an ASIC 68k Amiga SoC but with one it becomes modern growing and supported hardware again like the RPi. If failure is not an option, indeed, "It may be necessary." "The real choice is between renewal and managed decline"

|
5.2Ghz on a 7nm node process isn't realistic, at all, for a super pumped 68k core. |
| | Status: Offline |
| | cdimauro
| |
Re: RGL, Amiga Corp & Atari partner Plaion to produce NeoGeo AES+ using ASICs
Posted on 13-Jun-2026 9:55:34
| | [ #60 ] |
| |
|
Elite Member
|
Joined: 29-Oct-2012
Posts: 4645
From: Germany | | |
|
| @matthey
Quote:
matthey wrote:
While the under $100 USD VisionFive 2 SBC with SoC using SiFive series 7 cores has not been as popular as RPi SBCs, SiFive gained the NASA contract to replace the PPC by bolting a vector processor to Series 7 cores. At the following link, see page 9 for performance claims and page 10 for a diagram of vector unit bolted on to X280 (upgraded series 7) CPU core.
http://microelectronics.esa.int/riscv/rvws2022/presentations/04-SiFive_Intelligence_X280_for_Space_Exploration_v2.0_Dec_22.pdf
I wonder how similar the vector unit bolt on is to the vector unit Mitch Alsup designed for the open source Libre-SoC project. Some 68k developers may prefer a more integrated SIMD unit but a vector unit like the X280 uses may be easier to bolt on and is likely more scalable than a SIMD unit. |
You can have both, if you properly design this 68k ISA extension.
The main problem is that the opcode space is very limited.
I've suggested to reuse/remap line A for the SIMD/Vector extension, and line F for the corresponding scalar versions of the same instruction, when we discussed with you, Gunnar, and some other guys on Olaf's Amiga Development forum (2011-2013), which is the only reasonable way to add this important part to the 68k ISA.
The remapping is 100% backward-compatible, because you need new code to support this extension -> new binaries compiled which enable & use it. Old code doesn't enable it, so those lanes can continue to work as usual, ensuring full compatibility with the existing/legacy code. |
| | Status: Offline |
| |
|
|
|
[ home ][ about us ][ privacy ]
[ forums ][ classifieds ]
[ links ][ news archive ]
[ link to us ][ user account ]
|
