| Poster | Thread |
 matthey matthey
|  |
PowerPC lost in space to RISC-V the final nail in the coffin for PowerPC?
Posted on 20-Nov-2024 23:23:10
| | [ #1 ] |
|
|
 |
Elite Member
 |
Joined: 14-Mar-2007
Posts: 2900
From: Kansas | | |
|
| The PowerPC RAD750 and RAD5500 cores and SoCs have been replaced by a SiFive RISC-V PIC64-HPSC SoC using SiFive X280 in-order CPU cores.
https://www.janschafrich.com/overview-over-nasas-new-risc-v-based-processor/
http://microelectronics.esa.int/riscv/rvws2022/presentations/04-SiFive_Intelligence_X280_for_Space_Exploration_v2.0_Dec_22.pdf
The X280 in-order CPU cores are based on the SiFive 7 series U74 cores I recognized earlier as having a CISC like CPU design and impressive performance.
https://fuse.wikichip.org/news/7115/sifive-introduces-a-new-coprocessor-interface-targets-custom-accelerators/ Quote:
Launched under the new family of processors called SiFive Intelligence, the X280 is the first core to cater to AI acceleration. At a high level, the X280 builds on top of their silicon-proven U7-series high-performance (Linux-capable) core. SiFiveâs Intelligence X280 is somewhat of a unique processor from SiFive. Targetting ML workloads, its main feature point is both the new RISC-V Vector (RVV) Extension as well as SiFive Intelligence Extensions â the companyâs own RISC-V custom-extension for handling ML workloads which includes fixed-point data types from 8-bits to 64-bits as well as 16-64 bit FP and the BFloat16 data type. On the RVV extension side, the X280 supports 512-bit vector register lengths, allowing variable length operations up to 512-bits.
|
The CISC core design reduces performance killing load-to-use stalls.
https://en.wikichip.org/wiki/sifive/microarchitectures/7_series Quote:
0-cycle load-to-use latency (down from 1 cycle)
|
SiFive has improved the U74 core design and performance at least twice which I mentioned in earlier posts has plenty of room for improvements even though RISC-V lacks several 68k performance advantages like being able to execute the equivalent of 2 RISC instructions from execution pipelines, more powerful addressing modes and better code density. I previously mentioned that if the weak RISC-V ISA could reach 2.64 DMIPS/MHz with the U74 core, then the 68k should be able to reach 3-4 DMIPS/MHz with the stronger 68k ISA. The X280 core is now reaching a claimed 3.3 DMIPS/MHz which is better than any PPC core ever.
http://microelectronics.esa.int/riscv/rvws2022/presentations/04-SiFive_Intelligence_X280_for_Space_Exploration_v2.0_Dec_22.pdf Quote:
Performance
o 5.8 CoreMarks/MHz 3.3 Dhrystone/MHz
o 4.5 SpecINT2006/GHz 3.4 SpecFP2006/GHz (HiPerf config)
o 4.8 TOPS (INT8 Matrix Multiplication)
|
https://www.sifive.com/cores/intelligence-x280 Quote:
Performance benchmarks
- 5.75 CoreMarks/MHz
- 3.25 DMIPS/MHz
- 4.6 SpecINT2k6/GHz
Built on silicon-proven U7-Series core
- 64-bit RISC-V ISA
- 8-stage dual-issue in-order pipeline
- Coherent multi-core, Linux capable
|
The X280 cores may benefit from a L3 cache instead of the L2 cache most U74 SoCs used, depending on the flexible configuration. Memory can be up to DDR4. I'm not sure what chip fab process is used but it is likely at least 28nm which is the largest the SiFive U74 SoCs used. Their up coming OoO cores are using 12nm and maybe even 7nm though.
https://www.sifive.com/blog/incredibly-scalable-high-performance-risc-v-core-ip Quote:
SiFive also offers high-bandwidth memory interface IP, supporting SiFive TileLink and industry standard protocols, for SoC or chiplet style designs for memory intensive workloads that require the latest HBM2E+ memory capabilities. With validation in 7nm and 12nm process technology currently in progress, SiFive is extending high-performance DRAM capabilities from existing 16nm processes to leading-edge technologies.
|
PPC Amiga1 hardware is stuck at 45nm for desktop hardware while RISC-V hardware is using up to 7nm for embedded hardware. Intel was not competing well with a 10nm process vs AMD 7nm process vs Apple 3nm Process. If it wasn't for AMD 7nm hardware competing against Apple 3nm hardware, some people might believe the x86-64 ISA was noncompetitive.
I will now answer some related questions asked by Minator that was off topic in another thread.
matthey Quote:
| an in-order 68k CPU core like the 68060 can compete with low end ARM OoO CPU cores in performance using less area/transistors and power resulting in a cost advantage and lower system cost. |
minator Quote:
What are you basing this on?
|
A RISC-V in-order 8-stage SiFive U74 core uses a CISC like design and is outperforming the in-order 8-stage Cortex-A53 and Cortex-A55 cores. It was competitive with low end OoO Cortex-A57 cores.
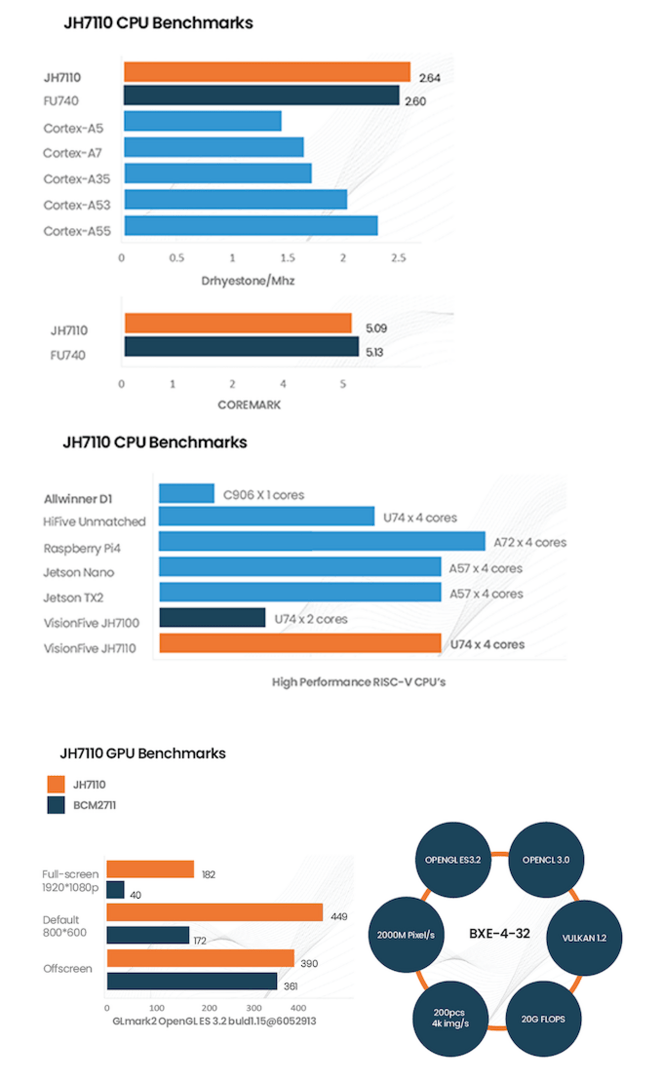
These would be low end configured Cortex-A57 cores using smaller caches and older fab sizes. The SiFive X280 is claimed to reach 3.3 DMIPS/MHz which may outperform some low end Cortex-A57 cores in some benchmarks (high end configuration Cortex-A57 cores may reach 4.1 DMIPS/MHz though). A Cortex-A57 OoO core is about 6 times the size in transistors of an in-order Cortex-A53 core and the in-order core is much lower power as active transistors use power. A wafer may give 6 times the number of in-order cores and better chip fab yields. The lower power of the in-order CPU core may allow to use a cheaper fab process or increase the fab process and use the smaller dies to compete against fat and hot OoO cores. The saved in-order CPU transistor and power budget can be used for the GPU transistor and power budget. If all a RISC OoO CPU is doing is removing load-to-use stalls then the in-order CISC design like the SiFive U74/X280 core design makes a lot of sense. Even more sense is to use a CISC ISA to gain more performance than any RISC ISA, especially the weak RISC-V ISA. You want to beef up an in-order CPU design as much as possible to compete with vulnerable OoO designs not to mention that a beefed 68k in-order CPU design could most likely outperform every PPC CPU ever made if a weak RISC-V ISA in-order core design can do it. In-order designs are relatively simple and cheaper to develop compared to OoO designs too. The major downside of in-order CPU cores can be the need for instruction scheduling but designs that minimize stalls like the 68060 and SiFive U74/X280 core designs minimize this disadvantage. Most compilers don't have a 68060 specific instruction scheduler yet performance is still very good and there is room for improvement at reducing scheduling needs and adding instruction schedulers to compilers. The 68060 was outperforming OoO PPC CPUs like the PPC601 and PPC603 in integer performance/MHz and should have been able to out clock them with the deeper pipeline while requiring fewer caches.
Year | CPU | transistors
1975 6502 3,500
1979 68000 68,000
1984 68020 190,000
1985 ARM1 25,000
1985 80386 275,000
1986 ARM2 30,000
1987 68030 273,000
1990 68040 1,170,000
1993 Pentium 3,100,000 superscalar in-order 2-way
1994 68060 2,530,000 superscalar in-order 2-way
1994 ARM7 250,000
1995 PentiumPro 5,500,000 OoO uop
2002 ARM11 7,500,000
2008 Nehalem 731,000,000 (1st gen Core i7 with 4 cores) 64 bit OoO uop
2011 Cortex-A7 10,000,000 superscalar in-order 2-way
2012 Cortex-A53 12,500,000 64-bit superscalar in-order 2-way
2012 Cortex-A57 75,000,000 64-bit OoO 3-way big.LITTLE companion of Cortex-A53
Rough ARM transistor counts come from the following link.
https://www.sciencedirect.com/topics/computer-science/stage-pipeline
The transistor budgets of in-order ARM cores was increasing linearly but OoO ARM cores are increasing exponentially. The RPi 4 Cortex-A72 is two generations past the Cortex-A57. I can no longer find the transistor counts for newer ARM cores but I will guess the trend below for the RPi 4 and RPi 5.
RPi 1 ARM11 core - ~3 times 68060 transistors
RPi 2 Cortex-A7 - ~4 times 68060 transistors times 4 cores is ~16 times 68060 transistors
RPi 3 Cortex-A53 - ~5 times 68060 transistors times 4 cores is ~20 times 68060 transistors
??? Cortex-A57 - ~30 times 68060 transistors times 4 cores is ~119 times 68060 transistors
RPi 4 Cortex-A72 - ~40? times 68060 transistors times 4 cores is ~160? times 68060 transistors
RPi 5 Cortex-A76 - ~60? times 68060 transistors times 4 cores is ~240? times 68060 transistors
RPi 3 Cortex-A53 baseline
??? Cortex-A57 - ~6 times Cortex-A53 transistors
RPi 4 Cortex-A72 - ~8 times Cortex-A53 transistors
RPi 5 Cortex-A76 - ~12 times Cortex-A53 transistors
A SiFive U74 core is likely smaller than a Cortex-A53 core although it didn't have a SIMD unit before the X280 added a vector unit which is different and I don't know how it would compare. The ARM64/AArch64 ISA is large compared to RISC-V, the 68k and even PPC so the cores are larger area. Even OoO RISC-V cores have a large area and small code density advantage which is a selling point for RISC-V in the embedded market.


https://www.allaboutcircuits.com/news/with-its-new-risc-v-processors-sifive-bets-on-compute-density/
Who would buy an in-order Cortex-A55 when a SiFive P470 OoO core is 30% smaller and has 2.75 times the single thread performance? Who would buy a Cortex-A78 when a SiFive P670 core with 5% less performance is half the size?
I tried to find compute density charts like this with the SiFive U74/X280 cores but I couldn't. Many customers choose ARM because they make creating ASICs easy and have a good reputation for low power embedded cores but they changed ISAs and now their cores are fat which is not good for power and their code density is not embedded market leading like Thumb-2 and 68k ISAs. SiFive is trying to make creating custom ASICs easier, cheaper and more accessible too.
https://www.anandtech.com/show/10488/sifive-unveils-freedom-platforms-for-riscvbased-semicustom-chips Quote:
SiFive does not elaborate how much money its customers will be able to save due to the free RISC-V microarchitecture, any pre-developed platforms (with re-used components), proven silicon, open-source software or other advantages that the company has to offer. This is understandable because every customer product could be unique in complexity and customization. However, SiFive says that in certain cases it will be able to deliver products to startups that do not have any silicon teams at all, which essentially means that the developer plans to address needs of very small players. Typically, such companies cannot get access to custom silicon because of high costs and other difficulties, but SiFive implies that with their pre-developed Freedom platforms the startups may get their chance to build semi-custom chips and take advantage of things like higher performance and/or lower power consumption compared to off-the-shelf not-customized silicon or FPGAs. The VP of SiFive told us that he could see a future where a couple of engineers in a garage can get access to a custom SoC âwith a moderate Kickstarter campaign.â
|
A couple of engineers in a garage using crowd funding is of course beyond the tiny 68k Amiga market though.
minator Quote:
I guess the idea of an ASIC 68K is kind of cool, but it's not very realistic. Even if it could be built, it'll be slow.
If you increase clock speed by 10X the cycle time reduces by 10X, however this also means latency goes up by 10X the clock cycles. Without all the modern mechanisms used to deal with this, the CPU will be constantly stalling. I doubt it'll get anywhere near the performance of an Arm A53, never mind Arm's OOO cores.
|
ASIC logic speed has greatly outpaced memory speed which means a high CPU clock speed needs more caches. This is true of an in-order or OoO CPU core with a fat OoO CPU core using up the transistor and power budget for the caches. An in-order CPU core has about half the max performance potential of an OoO CPU core but that is more performance than any PPC CPU or virtual 68k Amiga as the in-order SiFive X280 core exhibits while leaving performance potential only an efficient CISC ISA can fully exploit.
minator Quote:
The 68K instruction set won't help, multi-length instructions makes instruction decoding complex and unpredictable, trying to prefetch is going to take a load of complex logic. Then you've got potential page faults in the middle of instructions, and how 68K handles exceptions is even worse.
|
A variable length encoding is no problem at all. It is dealt with with the decoupled instruction fetch pipeline (IFP) feeding into an instruction buffer which feeds the execution pipelines (OEPs). Most superscalar in-order RISC cores (and some OoO RISC cores) use the same technique because superscalar execution is of a variable number of instructions due to dependencies. The decoupled IFP and OEPs with an instruction buffer allow for a smaller fetch size saving power. The 68060 only fetches 4 bytes/cycle but is a powerful superscalar CPU while PPC and ARM64/AArch64 cores can't even be superscalar with such a small instruction fetch. The improved code density reduces fetch needs, increases remaining memory bandwidth and increases cache hit rates or allows to reduce cache sizes.
Are page faults in the middle of instructions any worse than imprecise OoO exceptions with rollback and weak memory model ordering of loads/stores? Did RISC just move the complexity elsewhere after breaking down CISC instructions into smaller weaker RISC instructions and putting them back together in a less efficient way with OoO?
minator Quote:
BTW The A53 is a 12 year old processor, and it was the low end option even then. The RPi 5 is many times faster and half the price of an A500 mini.
|
The Cortex-A53 is still used because it is one of the smallest 64-bit ARM64/AArch64 cores. It is one of ARMs best attempts to minimize area for an application core (the Cortex-A35 tries to minimize power). The ARM ISA is fat and it isn't just SiFive going after them on area.
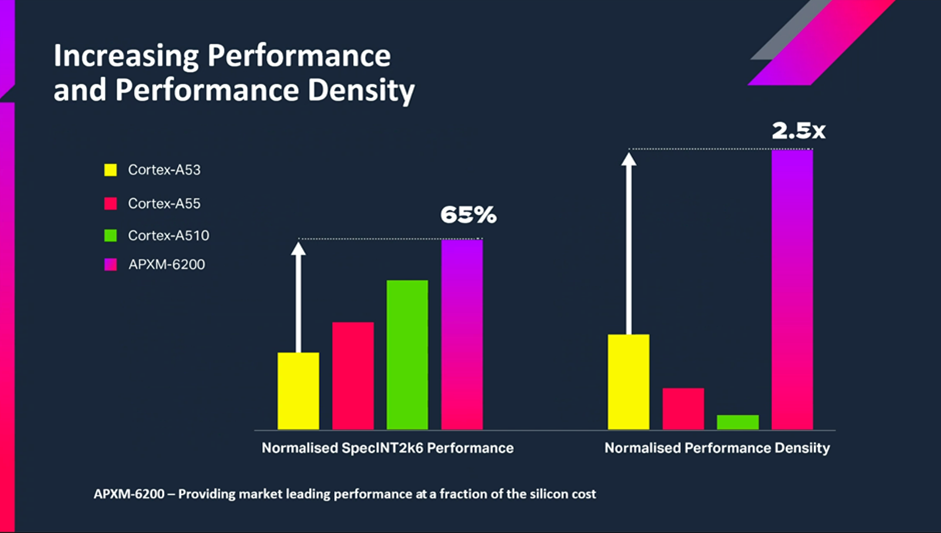
https://www.jonpeddie.com/news/imagination-launches-apxm-6200-risc-v-cpu-ip-core/
https://www.eetimes.com/imagination-reveals-risc-v-processor-at-embedded-world-2024/
That is an Imagination Technologies RISC-V APXM-6200 11-stage in-order core claiming to outperform newer in-order ARM cores. No RVC compression on this one so it would be better suited for small code embedded applications but those exist and the claim is to save memory bandwidth when used with an Imagination Technologies GPU so perhaps some kind of cache coherency between CPU and GPU core caches like HSA. There isn't a perfect CPU ISA for everything even though there are primarily only 3 major ISAs remaining and PPC being well behind the 3rd place primarily embedded player and standing still as technology disappears further and further out of sight much like as it did for Commodore. Trevor is like Irving after all. He loves his PPC and it does have an area advantage over ARM64/AArch64 which he is leveraging with the A1222+ CPU with castrated FPU. RISC-V is difficult to beat for area though. I would rather play the 68k in-order performance, code density and retro gaming advantages.
Last edited by matthey on 21-Nov-2024 at 07:06 PM.
Last edited by matthey on 20-Nov-2024 at 11:59 PM.
Last edited by matthey on 20-Nov-2024 at 11:48 PM.
Last edited by matthey on 20-Nov-2024 at 11:38 PM.
Last edited by matthey on 20-Nov-2024 at 11:30 PM.
Last edited by matthey on 20-Nov-2024 at 11:25 PM.
|
|
| Status: Offline |
|
|
Hammer
 | |
Re: PowerPC lost in space to RISC-V the final nail in the coffin for PowerPC?
Posted on 21-Nov-2024 2:52:33
| | [ #2 ] |
|
|
|
Elite Member
|
Joined: 9-Mar-2003
Posts: 6704
From: Australia | | |
|
| @matthey
Is that relevant for 68K Amiga?
PiStorm16 targets RPi CM4 (Cortex A72) for 16-bit Amigas.
PiStorm16 replaces the original PiStorm. _________________
|
|
| Status: Offline |
|
|
matthey
| |
Re: PowerPC lost in space to RISC-V the final nail in the coffin for PowerPC?
Posted on 21-Nov-2024 6:10:36
| | [ #3 ] |
|
|
|
Elite Member
|
Joined: 14-Mar-2007
Posts: 2900
From: Kansas | | |
|
| Hammer Quote:
Is that relevant for 68K Amiga?
|
The NASA PPC RAD750 CPU replacement is relevant to the PPC, 68k and Amiga. The PPC shallow pipeline 4-stage limited OoO CPU was replaced by a RISC-V 8-stage in-order SiFive X280 CPU that closely resembles the 8-stage in-order design of the 68060. What do they have in common?
68060 and SiFive U74/X280 core design similarities
o in-order 8-stage superscalar pipeline
o support for variable length encoded code
o 2 instruction dispatch/issue to 2 execution pipelines
o decoupled instruction fetch pipeline feeding an instruction buffer feeding the execution pipelines
o address generation ALU before execution ALU in execution pipeline to eliminate load-to-use stalls
o early execution of instructions in the AG ALU or late execution of instructions in the execute ALU
o Single cycle throughput of most instructions
o correct dynamic branch prediction gives zero cycle branches in most cases
There are differences too but the pipeline design is very similar. The architects obviously resurrected a CISC design and it very well could have been the 68060 design they copied. The weak RISC-V ISA leaves quite a bit of performance on the table compared to a good CISC ISA like the 68k but we can see that the 68060 architects nailed it only to be sabotaged to push the limited OoO shallow pipeline PPC603/G3 design that was difficult to clock up (the RAD750 only reached 200MHz using a 150nm process at best).
Will this change anything Amiga related? No. Trevor likes his PPC turds and making them fly. The sane Amiga masses left and the remaining Amiga fans are very tolerant of anything with an Amiga label or are happy with their original 68000@7MHz Amiga hardware. They don't care how Motorola and Commodore mistreated the 68k and Amiga. Amiga Corporation made it and Commodore fucked it up but nobody cares about fixing it anymore because it wouldn't be the original Motorola and Commodore nostalgic fuck ups. At least we can see that the 68060 was headed in the right direction and the PPC direction looks more dead end now. PPC is far more dead than the 68060 was when replaced by PPC and ironically one of the last PPC replacements was with a 68060 like design. The PPC Amiga attempted replacement in the first place would not have been necessary if Motorola/Freescale had clocked up the 68060 but then maybe the 68060 would have been clocked up for or by Commodore had they thought it was important to upgrade Amiga CPUs and chipsets. Maybe it would be better to let the Amiga die rather than use ancient bastardized castrated embedded PPC CPUs or emulate deficient Motorola/Freescale and Commodore 68k CPUs and chipsets while pretending there is some elegance from the original design left. At least then, the Amiga embarrassment would be over.
Last edited by matthey on 21-Nov-2024 at 01:33 PM.
Last edited by matthey on 21-Nov-2024 at 01:32 PM.
|
|
| Status: Offline |
|
|
kolla
| |
Re: PowerPC lost in space to RISC-V the final nail in the coffin for PowerPC?
Posted on 21-Nov-2024 14:27:54
| | [ #4 ] |
|
|
 |
Elite Member
|
Joined: 20-Aug-2003
Posts: 3576
From: Trondheim, Norway | | |
|
| @matthey
Quote:
| They don't care how Motorola and Commodore mistreated the 68k and Amiga |
How much "care" is one supposed to have for this, more than 30 years later?
Maybe some of us just learned to move on and appreciate what we can accomplish with what we already have and what we realistically can build ourselves._________________
B5D6A1D019D5D45BCC56F4782AC220D8B3E2A6CC |
|
| Status: Offline |
|
|
matthey
| |
Re: PowerPC lost in space to RISC-V the final nail in the coffin for PowerPC?
Posted on 21-Nov-2024 17:12:17
| | [ #5 ] |
|
|
|
Elite Member
|
Joined: 14-Mar-2007
Posts: 2900
From: Kansas | | |
|
| kolla Quote:
How much "care" is one supposed to have for this, more than 30 years later?
Maybe some of us just learned to move on and appreciate what we can accomplish with what we already have and what we realistically can build ourselves.
|
The Amiga fans still using so called Amigas are very tolerant and/or hardcore and/or perpetual optimists and/or fatalists. I do not believe current so called Amiga users are 1% of Amiga fans but more like 1% of 1% of Amiga fans (maybe 1 in 10,000). The vast majority of Amiga fans may remember the Amiga but have moved on because "what we already have", or more accurately stated as "what we have left", is a joke. I know 10+ Amiga fans here in the US that have a positive opinion of the Amiga and could easily afford Amiga hardware but the value is not anywhere close to competitive. They do not use 1990s spec noncompetitive virtual Amigas or failing museum pieces with Frankenstein add-ons. They do not use expensive FPGA hardware with 100MHz CPU performance at best or insanely priced desktop wannabe PPC AmigaNOne hardware with 10 years newer incompatible hardware that is still 20 years out of date and lacks desktop features including SMP after more than 10 years of work, longer than the original 68k Amiga was around. No, the sane Amiga fans have moved on because Amiga hardware is an embarrassment and the bad situation is deteriorating into EOL emulation. There was a glimpse of hope and perhaps even an opportunity with the hot retro market but THEA500 Mini was just a nostalgic toy for Amiga fans to play for awhile and throw in a drawer. Amiga Neverland is the land of perpetual missed opportunities. Trevor should stop his long failed PPC AmigaNOne abomination and give the Amiga IP back to Amiga Corporation that his conman fixer Ben stole for him. It still may be possible to do something respectful with the 68k Amiga that could be cheap and useful at the level of RPi hardware. He does not seem to have any respect or understanding of the 68k or Amiga though much like clueless egotistical Irving Gould.
Last edited by matthey on 21-Nov-2024 at 05:14 PM.
|
|
| Status: Offline |
|
|
kolla
| |
Re: PowerPC lost in space to RISC-V the final nail in the coffin for PowerPC?
Posted on 21-Nov-2024 17:29:29
| | [ #6 ] |
|
|
|
Elite Member
|
Joined: 20-Aug-2003
Posts: 3576
From: Trondheim, Norway | | |
|
| @matthey
MiSTer Pi is doing well, I even have colleagues who (without my input whatsoever) have bought one and are exploring also the Minimig universe, typically with the Amiga Vision distribution.
Meanwhile, grumpy old you are shouting at clouds, demanding we should all be as miserable as you about stuff that happened three decades ago? F that. Fix your systems, put them on rotation, one week with each, figure out what you can do with them, what they are still useful for, whatâs still fun⦠_________________
B5D6A1D019D5D45BCC56F4782AC220D8B3E2A6CC |
|
| Status: Offline |
|
|
Hammer
| |
Re: PowerPC lost in space to RISC-V the final nail in the coffin for PowerPC?
Posted on 21-Nov-2024 20:23:11
| | [ #7 ] |
|
|
|
Elite Member
|
Joined: 9-Mar-2003
Posts: 6704
From: Australia | | |
|
| @matthey
Quote:
| The NASA PPC RAD750 CPU replacement is relevant to the PPC, 68k and Amiga. The PPC shallow pipeline 4-stage limited OoO CPU was replaced by a RISC-V 8-stage in-order SiFive X280 CPU that closely resembles the 8-stage in-order design of the 68060. What do they have in common? |
The Falcon 9 has 3 dual-core x86 processors at 1.6 GHz running an instance of Linux on each core.
Space X has flown more orbital Falcon 9 rockets when compared to NASA's partnership with Boeing or ULA (Boeing-Lockheed Martin).
Quote:
the 8-stage in-order design of the 68060. What do they have in common?
68060 and SiFive U74/X280 core design similarities
o in-order 8-stage superscalar pipeline
o support for variable length encoded code
o 2 instruction dispatch/issue to 2 execution pipelines
o decoupled instruction fetch pipeline feeding an instruction buffer feeding the execution pipelines
o address generation ALU before execution ALU in execution pipeline to eliminate load-to-use stalls
o early execution of instructions in the AG ALU or late execution of instructions in the execute ALU
o Single cycle throughput of most instructions
o correct dynamic branch prediction gives zero cycle branches in most cases
|
CISC has extra instruction decoders which adds an extra stage.
From https://www.sifive.com/cores/intelligence-x280
X280 has the following:
512-bit vector register length.
3.25 DMIPS / MHz
64 bit wide IEU
SiFive Intelligence X280 IP is available for licensing i.e. needs to be paid by the customer. SiFive's licensing requirement negates the advantage against ARM.
Last edited by Hammer on 21-Nov-2024 at 09:15 PM.
Last edited by Hammer on 21-Nov-2024 at 09:12 PM.
Last edited by Hammer on 21-Nov-2024 at 08:36 PM.
Last edited by Hammer on 21-Nov-2024 at 08:27 PM.
_________________
|
|
| Status: Offline |
|
|
matthey
| |
Re: PowerPC lost in space to RISC-V the final nail in the coffin for PowerPC?
Posted on 22-Nov-2024 1:26:46
| | [ #8 ] |
|
|
|
Elite Member
|
Joined: 14-Mar-2007
Posts: 2900
From: Kansas | | |
|
| Hammer Quote:
The Falcon 9 has 3 dual-core x86 processors at 1.6 GHz running an instance of Linux on each core.
Space X has flown more orbital Falcon 9 rockets when compared to NASA's partnership with Boeing or ULA (Boeing-Lockheed Martin).
|
That is one way to get redundancy but not low power and poor interrupt response time. Surely they are not using the normal monolith Linux kernel?
Hammer Quote:
CISC has extra instruction decoders which adds an extra stage.
|
You mean x86(-64) has extra instruction decoder stages? Quite possible as x86(-64) is not nearly as orthogonal as the 68k and VLE 8-bit encoded code is more difficult to decode than VLE 16-bit encoded code due to inferior alignment and longer encoded sequences of code, some of which override earlier decoded data. Most 68k instructions can be decoded by looking at the first 16-bits of instructions and the first 6 bytes of 68k instructions is enough for ColdFire variable length RISC encodings, a subset of the 68k ISA.
The 68060 performs most decoding in a single stage called the instruction early decode (IED) stage.
The Superscalar Architecture of the MC68060 Quote:
During the instruction address generation cycle, the instruction fetch pipeline calculates the next prefetch address. Also accessed in this cycle is a virtually mapped branch cache that improves prefetch efficiency by detecting changes in the sequential flow of the fetch stream based on past execution history. During the instruction fetch cycle, this pipeline accesses a physically mapped instruction cache with an associated address translation cache to provide an effective, low-latency instruction fetch.
The 32 bits of instruction prefetch then feed the instruction early decode stage. This stage implements a table lookup function to provide decode information to the operand execution pipelines concerning instruction resource requirements along with information for controlling the top stage of the pipelines. This decode information allows efficient evaluation of the superscalar dispatch algorithm.
At the conclusion of this stage, the instruction and its associated decode information move into the first-in, first-out instruction buffer, packaged as machine instructions. During the instruction buffer stage, the instruction fetch pipeline moves opcodes and extension words out of the FIFO buffer into the dual operand-execution pipelines. This buffer provides the decoupling mechanism between the fetch and execution pipelines, allowing the instruction fetch pipeline to load the fetched stream and the operand-execution pipelines to unload the contents as the stream executes.
Comprising the dual operand-execution pipelines are the primary operand-execution pipeline (pOEP) and secondary operand-execution pipeline (sOEP). Each decodes instructions, fetches required operands, and executes instructions. The primary pipeline contains an integer execution engine that can perform any supported 68K instruction and a floating-point execution engine. The secondary pipeline contains an integer execution engine that can perform most, but not all, 68K operations. The microprocessor executes up to three instructions in one machine cycle: two integer instructions
plus a taken branch or a floating-point instruction, an integer instruction, and a taken branch.
Multiported register files contain the program-visible registers for both the integer and floating-point programming model.
The four stages of the operand-execution pipelines are decode instruction and select components of the operand address (DS); operand address generation (AG); operand fetch cycle (OC); and instruction execution (EX) stages.
The pipelines have two optional stages for operand memory writes: data available (DA), and write back (W).
During the decode and select stage, each pipeline uses the early decode information and accesses the integer register file (not shown in figure) for operands needed for effective-address calculation. In the operand address generation stage, each pipeline computes the effective address for instructions requiring data from memory. The operand fetch cycle fetches register and memory operands. Finally, the instruction execution stage performs the desired instruction executions in the integer or floating-point execution engines. Two additional stages, data available and write back, complete operand store operations.
|
You could argue that the decode instruction and select components (DS) stage is additional decoding but it sounds more like superscalar instruction dispatch with resource dependency checking and select/access of resources. The pre-decoded instructions in the instruction buffer use a fixed length RISC like encoding but contain more powerful memory accessing CISC instructions like x86(-64) micro/macro ops. They are no more difficult to execute other than requiring more resources and RISC CPU cores with instruction buffers perform the same dispatch/issue and resource select stage. Load/store architectures simplify this at the cost of memory access performance but the 68060 is having no problems dispatching instructions into 2 execution pipes in a single stage. Wider issue/dispatch increases complexity quickly but CISC cores don't need to be as wide because they can execute 2 RISC like instructions in a single execution pipe with no dependency issues compared to wider issue RISC cores that need OoO execution for performance to remove the dependencies from breaking down fewer strong CISC instructions into many weak RISC instructions.
If you disagree with me and say CISC needs 2 decode stages for an 8-stage pipeline, then look at the SiFive U74 core.
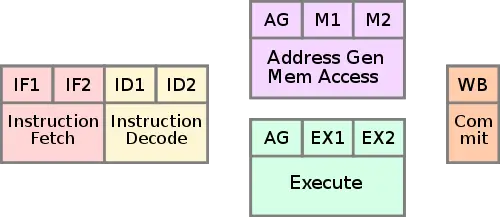
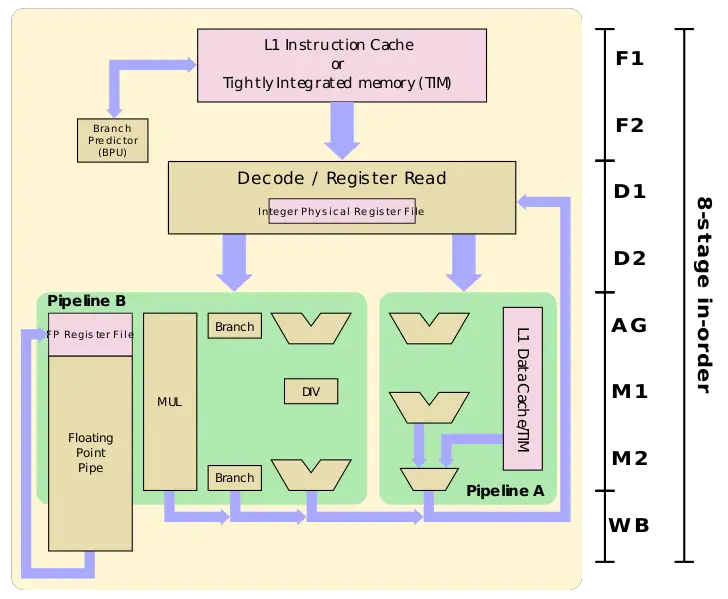
The SiFive U74 pipeline shows 2/8 stages are for decode. Does this mean RISC-V has a higher decoding overhead than the 68060? No. The stage names are just general labels for most of the work done in that stage while other work is often done in parallel. I believe the SiFive U74 pipeline is performing more decoding and possibly more work before the instruction goes in the instruction buffer. One difference between the SiFive U74 and 68060 cores appears to be that the former accesses the GP int register file in the fetch pipeline while the latter accesses registers in the execution pipelines. Longer pipelines for higher clock rates may have added decoding stages so pipelines of different lengths should not be compared. There likely is a decoding difference between ISAs but I doubt pipeline "decoding" stage labels are a good determination of decoding latency. More decode latency may be acceptable with higher code density like the 68k has as instruction fetch and the number of instructions in caches are increased without increasing the cache sizes which increase cache access latency. Multi-level caches with small and low access latency L1 caches closest to the CPU pipeline are used because cache access latency is important for performance too.
Hammer Quote:
From https://www.sifive.com/cores/intelligence-x280
X280 has the following:
512-bit vector register length.
3.25 DMIPS / MHz
64 bit wide IEU
SiFive Intelligence X280 IP is available for licensing i.e. needs to be paid by the customer. SiFive's licensing requirement negates the advantage against ARM.
|
I believe SiFive's licensing terms are more flexible than ARMs and it sounded to me like no royalties were required for SiFive IP where ARM not only has more restrictive licensing but has royalties for their CPU cores, for their GPU cores and for their custom IP blocks which more recent license maneuvering strongly encourages and may be required in the future. ARM makes chip design easy but they lock you in as a customer and are more controlling than a la carte like they used to be.
|
|
| Status: Offline |
|
|
Hammer
| |
Re: PowerPC lost in space to RISC-V the final nail in the coffin for PowerPC?
Posted on 22-Nov-2024 2:45:53
| | [ #9 ] |
|
|
|
Elite Member
|
Joined: 9-Mar-2003
Posts: 6704
From: Australia | | |
|
| @matthey
Quote:
That is one way to get redundancy but not low power and poor interrupt response time. Surely they are not using the normal monolith Linux kernel?
|
Falcon 9 uses custom Linux with RT extensions.
Modern dual core X86 @ 1.6 Ghz is low power.
Quote:
You mean x86(-64) has extra instruction decoder stages? Quite possible as x86(-64) is not nearly as orthogonal as the 68k and VLE 8-bit encoded code is more difficult to decode than VLE 16-bit encoded code due to inferior alignment and longer encoded sequences of code, some of which override earlier decoded data. Most 68k instructions can be decoded by looking at the first 16-bits of instructions and the first 6 bytes of 68k instructions is enough for ColdFire variable length RISC encodings, a subset of the 68k ISA.
|
68060 can't avoid instruction CISC to fix length decoders.
Semi-modern ARM CPUs such as Cortex A53 have decoders and they are lightweight.
The pipeline stage adds completion cycle latency, so it's a design compromise between a certain pipeline depth for reaching a certain speed and instruction completion cycle latency.
1 cycle throughput means the instruction completes the pipeline in one pass.
Quote:
I believe SiFive's licensing terms are more flexible than ARMs and it sounded to me like no royalties were required for SiFive IP where ARM not only has more restrictive licensing but has royalties for their CPU cores, for their GPU cores and for their custom IP blocks which more recent license maneuvering strongly encourages and may be required in the future. ARM makes chip design easy but they lock you in as a customer and are more controlling than a la carte like they used to be.
|
SiFive's X280 implementation is not free, hence the reason for SiFive's licensing terms.
Last edited by Hammer on 22-Nov-2024 at 02:50 AM.
_________________
|
|
| Status: Offline |
|
|
matthey
| |
Re: PowerPC lost in space to RISC-V the final nail in the coffin for PowerPC?
Posted on 22-Nov-2024 22:09:51
| | [ #10 ] |
|
|
|
Elite Member
|
Joined: 14-Mar-2007
Posts: 2900
From: Kansas | | |
|
| Hammer Quote:
Falcon 9 uses custom Linux with RT extensions.
|
The hardware and OS are still not the best choice for real time embedded use but a big improvement over Linux with a monolithic kernel and Windows.
Hammer Quote:
Modern dual core X86 @ 1.6 Ghz is low power.
|
Modern x86-64 cores have good power efficiency (performance/W) because of the high performance. They are not low power compared to the competition using other ISAs and the same chip fab process but economies of scale have allowed them to use new fab processes which reduce power and reduce the price for good price efficiency (performance/$). Lowering the clock speed of course reduces the power and could be temporarily increased for more performance.
Hammer Quote:
68060 can't avoid instruction CISC to fix length decoders.
Semi-modern ARM CPUs such as Cortex A53 have decoders and they are lightweight.
|
The 68k, ColdFire and x86(-64) ISA design choice was to use a VLE all the time which I believe was a good choice. RISC-V allows to use code with a 32-bit fixed length encoding (RV32IM or RV64IM) on hardware that supports compressed code (RV32IMC and RV64IMC). There can be a small performance advantage of better branch target alignment on some hardware but it is usually more than offset by the advantages of smaller code for caches and instruction fetch. Most larger RISC-V cores are choosing to implement compression/VLE even though this adds decode latency and sometimes maybe even an extra pipeline stage. The RISC-V hardware already suffers any pipeline decode latency to support a VLE so fixed length code has few advantages and uncompressed 32-bit fixed length RISC-V code density is like all the dead classic RISC ISAs including Alpha, PA-RISC, MIPS, SPARC and PPC. A more specialized VLE only ISA can have better performance, better code density, use the encoding space more efficiently and have more standardization than an everything ISA like RISC-V.
ARM64/AArch64 code with a 32-bit fixed length encoding is easier to decode but superscalar cores often use instruction buffers because instruction execution is irregular due to dependencies that would cause stalls/bubbles without it and the fetch size can be reduced to save power. Let's take a look at the Cortex-A53 pipeline.
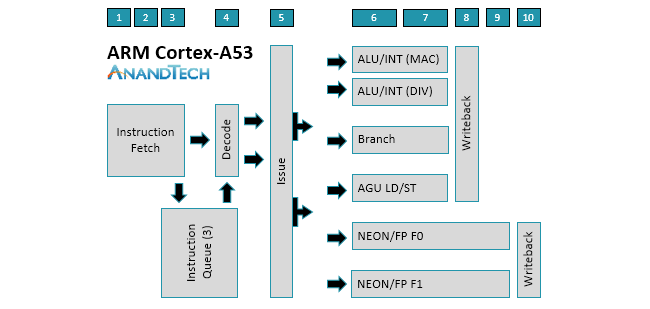
https://www.anandtech.com/show/11441/dynamiq-and-arms-new-cpus-cortex-a75-a55/4
The Cortex-A53 has an instruction buffer/queue. The diagram only shows a single decode stage but this is not a detailed diagram. I found the following more detailed diagram that claims to be of a Cortex-A53.
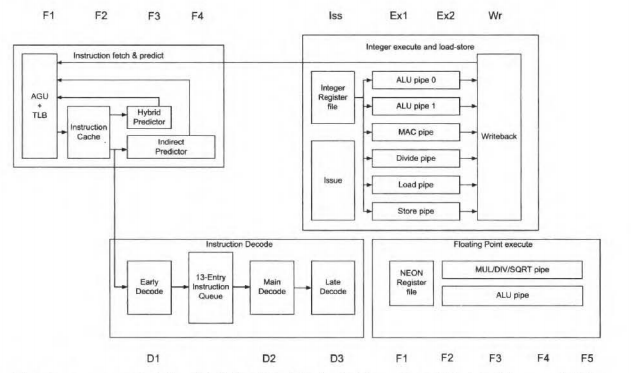
https://community.arm.com/support-forums/f/architectures-and-processors-forum/55763/about-arm-contex-a53-pipeline-architecture
This is an ARM core but likely not a Cortex-A53. The work performed around the instruction buffer/queue is shown which is similar to other cores including the Cortex-A53 and 68060. Early decode, instruction queue into buffer, decode/select and issue/dispatch are the steps even though the shorter 8-stage 68060 pipeline combines the decode/select and issue stages. There is not much difference between the Cortex-A53 and 68060 pipelines until the execution pipelines. The instruction buffer/queue hides early decoding latency unless the instruction buffer is empty so even instructions that take multiple cycles to fetch and/or decode usually do not affect performance. Lastly, I'll show a newer in-order Cortex-A510 pipeline which has 3/10 stages of decode.

https://en.wikichip.org/wiki/arm_holdings/microarchitectures/cortex-a510
ARM created a micro-oped in-order core and breaking down instructions further requires more latency adding decode stages, more transistors and more power even with the 32-bit fixed length encoding. Definitely not a normal small practical low latency 8-stage pipeline embedded core anymore but overall performance no doubt improved with the higher clock rate made possible by more stages. The larger core size is reduced by sharing resources between cores like the vector unit reminiscent of the AMD Bulldozer resource sharing.
Hammer Quote:
The pipeline stage adds completion cycle latency, so it's a design compromise between a certain pipeline depth for reaching a certain speed and instruction completion cycle latency.
1 cycle throughput means the instruction completes the pipeline in one pass.
|
Engineering is the art of compromise. ARM cores with a 32-bit fixed length encoding often make the same latency adding compromise to avoid stalls/bubbles in a superscalar pipeline due to dependencies. There is not much difference in the front end (fetch, early decode, instruction queue/buffer) between ARM, RISC-V and 68060 cores. I do not see any extra 68060 decode stages as extra fetch cycles due to the small 4 byte/cycle fetch and early decode of the few large instructions in the instruction fetch pipeline are usually hidden by the decoupling of the instruction fetch pipeline and execution pipelines. My educated guess is that roughly 95% of 68020 integer instructions in code can be decoded with size length from decoding the first 16-bits and 98% of 68020 instructions in code can be decoded by looking at the first 32-bits including MULx.L, DIVx.L and most FPU instructions. Decoding the first byte of an x86(-64) instruction is only fully decoded for 4% of x86-64 instructions and 18% of x86 instructions. Even 2 sequential bytes decoded likely does not reach 50% of x86-64 instructions and later decoded bytes can override earlier ones. The common case for 68k decoding is much easier than the common case for x86(-64) decoding and the better code density of 68k code offsets more decoding overhead.
The 68060 and SiFive U74/X280 cores have an extra stage in the execution pipelines (IFP=4 stages, instruction queue, OEP=4 stages) that the Cortex-A53 does not even though the Cortex-A53 execution pipeline is longer (IFP=3, instruction queue, OEP=5 stages). This requires an extra stage and ALU by combining a load/store unit and integer unit but removes load-to-use stalls, allows early or late execution of instructions reducing execution latency and allows more powerful CISC instructions to execute that are the equivalent of 2 RISC instructions in the case of the 68060. The Cortex-A53 should have moved as much decoding as possible before the instruction queue/buffer where fetch and (pre-)decode latency can be hidden and 2 execution pipeline stages exist that the 68060 and SiFive U7/X280 cores do not have or more likely are combined into other stages. The Cortex-A53 design is clearly inferior despite simpler decoding. It could be architect inexperience, lack of logic optimization (the Cortex-A55 is a better optimized version of the Cortex-A53 design as compared in the anandtech.com article above) or adding stages to be able to clock the core higher without rethinking the whole design which was common for RISC CPU cores. Branch prediction becomes more expensive with a deeper pipeline which RISC architects seem to know but they commonly miss that load-to-use latency grows as pipelines get deeper with many RISC core designs. They study the scalar classic RISC pipeline in school and admire how simple it is but making it superscalar throws a wrench in the regularity and adding a deeper pipeline for higher clock speed is not as simple as adding stages that do not do much. They probably did not read the following RISC research paper either.
Zero-Cycle Loads: Microarchitecture Support for Reducing Load Latency
https://ftp.cs.wisc.edu/sohi/papers/1995/micro.zcl.pdf
It could have been a RISC superiority propaganda and arrogance thing too. CISC architects figured it out early but props to the RISC-V architect for going with an old school CISC design for a RISC core even though some of the advantages are lost with RISC. Maybe he read the old paper above too.
Hammer Quote:
SiFive's X280 implementation is not free, hence the reason for SiFive's licensing terms.
|
There is no such thing as a free lunch. How much development cost and time would be required for designing and testing all the I/O on a modern SoC?
Last edited by matthey on 22-Nov-2024 at 11:47 PM.
Last edited by matthey on 22-Nov-2024 at 10:16 PM.
|
|
| Status: Offline |
|
|
Hammer
| |
Re: PowerPC lost in space to RISC-V the final nail in the coffin for PowerPC?
Posted on 22-Nov-2024 23:48:03
| | [ #11 ] |
|
|
|
Elite Member
|
Joined: 9-Mar-2003
Posts: 6704
From: Australia | | |
|
| @matthey
Quote:
| The hardware and OS are still not the best choice for real time embedded use but a big improvement over Linux with a monolithic kernel and Windows. |
LOL.
Quote:
Modern x86-64 cores have good power efficiency (performance/W) because of the high performance. They are not low power compared to the competition using other ISAs and the same chip fab process
. |
False.
Intel TSMC 3 mn fab Lunar Lake beats TSMC 3 mn fab Qualcomm Elite X.
Intel Luna Lake iGPU crushed Qualcomm Elite X's iGPU.
https://www.tomsguide.com/computing/laptops/intel-lunar-lake-benchmarks-heres-how-it-compares-to-snapdragon-x-and-apple-m3
PugetBench Adobe CC test results,
You can see that the Intel Core Ultra 7 258V chip in the Lunar Lake laptops we've tested is pretty capable when it comes to Adobe apps, delivering Photoshop scores that beat the Snapdragon X laptops we've tested so far.
(skip)
Battery life test results...
It's awfully close though, with the Lunar Lake laptops we've tested so far nipping at the heels of Apple's long-lasting 16-inch MacBook Pro
- Tom's Hardware
https://youtu.be/Ym6av2u5DYU?t=934
Video playback
Dell XPS 13 9345 (Snapdragon X Elite) = 27h 44m
Dell XPS 13 9350 (Lunar Lake) = 28h 44m
https://youtu.be/Ym6av2u5DYU?t=978
Modern office
Dell XPS 13 9345 (Snapdragon X Elite) = 24h 21m
Dell XPS 13 9350 (Lunar Lake) = 26h 47m
Gaming
Dell XPS 13 9345 (Snapdragon X Elite) = 2h 17m
Dell XPS 13 9350 (Lunar Lake) = 3h 01m
Both Dell XPS 13 9350 (Lunar Lake) and Dell XPS 13 9345 (Snapdragon X Elite) have 55 WHr batteries.
AMD's Ryzen "Strix Point" APU uses TSMC's older 4 nm fab. AMD is currently porting APU designs on TSMC 3 nm fabs.
Last edited by Hammer on 23-Nov-2024 at 12:15 AM.
Last edited by Hammer on 23-Nov-2024 at 12:10 AM.
Last edited by Hammer on 23-Nov-2024 at 12:01 AM.
_________________
|
|
| Status: Offline |
|
|
matthey
| |
Re: PowerPC lost in space to RISC-V the final nail in the coffin for PowerPC?
Posted on 23-Nov-2024 1:49:04
| | [ #12 ] |
|
|
|
Elite Member
|
Joined: 14-Mar-2007
Posts: 2900
From: Kansas | | |
|
| Hammer Quote:
It's a good showing for Intel after abandoning their own aging for desktop/laptop 7nm fab process for their high end chips and using the TSMC 3nm process. Intel is skilled at designing low power microarchitectures because they have had to be with x86-64 cores. There are area/transistor tradeoffs which can be made to lower power like using 8 transistors per bit SRAM instead of 6 transistors per bit SRAM and using slower eDRAM instead of SRAM for high level caches. I would be surprised if Intel x86-64 cores were smaller area/transistors than the Qualcomm ARM cores. You didn't mention Apple laptop results which usually have the longest battery life, at least when turning down their usually brighter screens. The GPU cores may make more of a difference in some of these tests than the CPU cores. Like I said, x86-64 CPU cores have good performance/W which is why they are used in servers so for high performance workloads they are competitive because they finish the work quickly and go back to sleep. When battery power is a problem, even x86-64 e-cores are OoO and large compared to in-order ARM cores.
Last edited by matthey on 23-Nov-2024 at 03:38 AM.
|
|
| Status: Offline |
|
|
OneTimer1
| |
Re: PowerPC lost in space to RISC-V the final nail in the coffin for PowerPC?
Posted on 23-Nov-2024 21:28:03
| | [ #13 ] |
|
|
 |
Super Member
 |
Joined: 3-Aug-2015
Posts: 1517
From: Germany | | |
|
| @matthey
There is no need for fancy diagrams.
PowerPC had its first big chance a CPU for desktops PCs / Workstations with Apple and IBM, it had a second chance as an embedded CPU for gaming systems like Playstation and XBox 360 but now it's over, it's a platform in decline.
Motorola/Freescale has become a part of NXP and they are pushing forward ARM chips, it's over. Last edited by OneTimer1 on 23-Nov-2024 at 09:35 PM.
|
|
| Status: Offline |
|
|
NutsAboutAmiga
| |
Re: PowerPC lost in space to RISC-V the final nail in the coffin for PowerPC?
Posted on 23-Nov-2024 22:08:07
| | [ #14 ] |
|
|
 |
Elite Member
|
Joined: 9-Jun-2004
Posts: 13049
From: Norway | | |
|
| @matthey
My impression of the RISC-V is thatâs its experimental, and designed for embedded use, the instruction set is not set in stone, thatâs exactly the problem we have with low-cost CPUâs we have. I find it funny and tragic that we always pick the worst alternatives, old or embedded chip, and sometimes they are old and embedded. When there are chips on the market that are made for servers and workstations. Most of the cost is not in chips, itâs in design the hardware, and getting it tested, plus all the drivers you need.
This brings me to next subject all OpenGL 3.0 and etc, thatâs not really relevant, as that has been supported by OS, itâs not hardware thing. It really does not matter whatâs support on Linux, as thatâs not what interests the Amiga community.
_________________
http://lifeofliveforit.blogspot.no/
Facebook::LiveForIt Software for AmigaOS |
|
| Status: Offline |
|
|
kolla
| |
Re: PowerPC lost in space to RISC-V the final nail in the coffin for PowerPC?
Posted on 23-Nov-2024 23:58:21
| | [ #15 ] |
|
|
|
Elite Member
|
Joined: 20-Aug-2003
Posts: 3576
From: Trondheim, Norway | | |
|
| @matthey
Quote:
| big improvement over Linux with a monolithic kernel |
Itâs still a monolithic kernel - real-time doesnât imply microkernel.
Also, the mentioned real-time paches are at last being merged into main these days
Secondly - have SpaceX equipment been so high up that radiation hardened processors have been needed yet? Certainly most of their activities have been in rather low orbits, within protecting of earthâs magnetic fields etc._________________
B5D6A1D019D5D45BCC56F4782AC220D8B3E2A6CC |
|
| Status: Offline |
|
|
kolla
| |
Re: PowerPC lost in space to RISC-V the final nail in the coffin for PowerPC?
Posted on 24-Nov-2024 0:08:56
| | [ #16 ] |
|
|
|
Elite Member
|
Joined: 20-Aug-2003
Posts: 3576
From: Trondheim, Norway | | |
|
| @NutsAboutAmiga
Quote:
| instruction set is not set in stone |
When are they ever, even in x86?_________________
B5D6A1D019D5D45BCC56F4782AC220D8B3E2A6CC |
|
| Status: Offline |
|
|
matthey
| |
Re: PowerPC lost in space to RISC-V the final nail in the coffin for PowerPC?
Posted on 24-Nov-2024 6:06:49
| | [ #17 ] |
|
|
|
Elite Member
|
Joined: 14-Mar-2007
Posts: 2900
From: Kansas | | |
|
| OneTimer1 Quote:
There is no need for fancy diagrams.
PowerPC had its first big chance a CPU for desktops PCs / Workstations with Apple and IBM, it had a second chance as an embedded CPU for gaming systems like Playstation and XBox 360 but now it's over, it's a platform in decline.
Motorola/Freescale has become a part of NXP and they are pushing forward ARM chips, it's over.
|
PPC being replaced in space was no surprise as PPC is long dead and buried. Being replaced by a small simple in-order RISC-V core with better performance than any PPC CPU ever is a surprise though. The ARM64/AArch64 ISA is closer to the PPC ISA but RISC-V was chosen. I'm not sure what factor(s) won the contract but having a high performance but low power in-order core made it possible despite the weak RISC-V ISA.
NutsAboutAmiga Quote:
My impression of the RISC-V is thatâs its experimental, and designed for embedded use, the instruction set is not set in stone, thatâs exactly the problem we have with low-cost CPUâs we have. I find it funny and tragic that we always pick the worst alternatives, old or embedded chip, and sometimes they are old and embedded. When there are chips on the market that are made for servers and workstations. Most of the cost is not in chips, itâs in design the hardware, and getting it tested, plus all the drivers you need.
|
Maybe RISC ISAs are experimental. RISC-I, RISC-II, RISC-III, RISC-IV, RISC-V, ARM32/AArch32, Thumb, Thumb-2, ARM64/AArch64. Even among the many do over ISAs of active RISC development and with perhaps the most standardized ISA of ARM64/AArch64, big endian support is being dropped from newer core designs.
kolla Quote:
Itâs still a monolithic kernel - real-time doesnât imply microkernel.
Also, the mentioned real-time paches are at last being merged into main these days
|
So throw everything in a big fat monolithic kernel and optimize it?
kolla Quote:
Secondly - have SpaceX equipment been so high up that radiation hardened processors have been needed yet? Certainly most of their activities have been in rather low orbits, within protecting of earthâs magnetic fields etc.
|
My understanding is that even jets at high altitude have a higher chance of radiation bit flips than ground level bits. Electronics redundancy and error detection/correction may be adequate without radiation hardening though.
|
|
| Status: Offline |
|
|
kolla
| |
Re: PowerPC lost in space to RISC-V the final nail in the coffin for PowerPC?
Posted on 24-Nov-2024 9:23:03
| | [ #18 ] |
|
|
|
Elite Member
|
Joined: 20-Aug-2003
Posts: 3576
From: Trondheim, Norway | | |
|
| @matthey
Quote:
So throw everything in a big fat monolithic kernel and optimize it?
|
Do you even grasp what the concept of "real time" means?
Because it really seems like you don't.
Quote:
My understanding is that even jets at high altitude have a higher chance of radiation bit flips than ground level bits. |
Sure, as does living closer to the magnetic poles (I've been operating servers at 78°)... but there's also a vast difference between "radiation" and "radiation".
_________________
B5D6A1D019D5D45BCC56F4782AC220D8B3E2A6CC |
|
| Status: Offline |
|
|
Yssing
| |
Re: PowerPC lost in space to RISC-V the final nail in the coffin for PowerPC?
Posted on 24-Nov-2024 22:30:38
| | [ #19 ] |
|
|
 |
Super Member
|
Joined: 24-Apr-2003
Posts: 1135
From: Unknown | | |
|
| @matthey
Maybe it is about time to ditch PPC and go for RISC-V _________________
|
|
| Status: Offline |
|
|
Hammer
| |
Re: PowerPC lost in space to RISC-V the final nail in the coffin for PowerPC?
Posted on 24-Nov-2024 23:14:41
| | [ #20 ] |
|
|
|
Elite Member
|
Joined: 9-Mar-2003
Posts: 6704
From: Australia | | |
|
| |
| Status: Offline |
|
|
