| Poster | Thread |
 Hammer Hammer
 |  |
Re: Amiga SIMD unit
Posted on 20-Sep-2020 23:03:59
| | [ #81 ] |
|
|
 |
Elite Member
 |
Joined: 9-Mar-2003
Posts: 6504
From: Australia | | |
|
| @matthey
FYI, OpenGL was running on DirectX8 era GPUs which has floating point datatype for vertex shaders and integer datatype for pixel shaders. Rasterization hardware accelerates floating-point geometry into pixel grid which is integer datatype. Hombre's geometry power is about PS1 level.
Last edited by Hammer on 20-Sep-2020 at 11:10 PM.
Last edited by Hammer on 20-Sep-2020 at 11:07 PM.
_________________
Amiga 1200 (rev 1D1, KS 3.2, PiStorm32/RPi CM4/Emu68)
Amiga 500 (rev 6A, ECS, KS 3.2, PiStorm/RPi 4B/Emu68)
Ryzen 9 7950X, DDR5-6000 64 GB RAM, GeForce RTX 4080 16 GB |
|
| Status: Offline |
|
|
matthey
| |
Re: Amiga SIMD unit
Posted on 21-Sep-2020 8:12:25
| | [ #82 ] |
|
|
|
Elite Member
|
Joined: 14-Mar-2007
Posts: 2751
From: Kansas | | |
|
| Quote:
Hammer wrote:
FYI, OpenGL was running on DirectX8 era GPUs which has floating point datatype for vertex shaders and integer datatype for pixel shaders. Rasterization hardware accelerates floating-point geometry into pixel grid which is integer datatype. Hombre's geometry power is about PS1 level.
|
The PS1 CPU didn't even have an FPU. The Geometry Transformation Engine (GTE) coprocessor used fixed point integers only (several parallel operations per instruction with separate register SIMD and MACs). Quality suffered though. Lack of sub-pixel accuracy projections caused wobbling objects and objects would jump several pixels in extreme cases (I also had the wobbling objects problem with a program using fixed point 3D projections I wrote in 68k assembler years ago). Perspective is not correct which looks wrong and can cause problems with clipping and textures. The PS1 did not even have a z-buffer which Hombre supposedly would have had. Floating point can be done using integer math but short cuts were made to keep it fast. Sacrificing 3D quality isn't really an option today so floating point performance in hardware is important.
Last edited by matthey on 21-Sep-2020 at 03:35 PM.
|
|
| Status: Offline |
|
|
Lou
| |
Re: Amiga SIMD unit
Posted on 21-Sep-2020 14:16:11
| | [ #83 ] |
|
|
 |
Elite Member
|
Joined: 2-Nov-2004
Posts: 4259
From: Rhode Island | | |
|
| I think you guys were missing the point that the pedal bike would still be a 10 or 12 speed bike with skinny tires. The engine would burn the tires off the rim... I'm not talking full motor-cycle chasis here... |
|
| Status: Offline |
|
|
matthey
| |
Re: Amiga SIMD unit
Posted on 21-Sep-2020 16:01:11
| | [ #84 ] |
|
|
|
Elite Member
|
Joined: 14-Mar-2007
Posts: 2751
From: Kansas | | |
|
| Quote:
Lou wrote:
I think you guys were missing the point that the pedal bike would still be a 10 or 12 speed bike with skinny tires. The engine would burn the tires off the rim... I'm not talking full motor-cycle chasis here... |
Was x86 which outperformed and killed PPC with only 8 GP registers a mono-cycle then?
|
|
| Status: Offline |
|
|
Lou
| |
Re: Amiga SIMD unit
Posted on 21-Sep-2020 16:49:31
| | [ #85 ] |
|
|
|
Elite Member
|
Joined: 2-Nov-2004
Posts: 4259
From: Rhode Island | | |
|
| @matthey
...the bad analogies continue... |
|
| Status: Offline |
|
|
matthey
| |
Re: Amiga SIMD unit
Posted on 21-Sep-2020 17:31:24
| | [ #86 ] |
|
|
|
Elite Member
|
Joined: 14-Mar-2007
Posts: 2751
From: Kansas | | |
|
| Quote:
Lou wrote:
...the bad analogies continue... |
Didn't you make the bicycle/motorcycle analogy?
|
|
| Status: Offline |
|
|
Lou
| |
Re: Amiga SIMD unit
Posted on 21-Sep-2020 20:11:01
| | [ #87 ] |
|
|
|
Elite Member
|
Joined: 2-Nov-2004
Posts: 4259
From: Rhode Island | | |
|
| @matthey
Ok how about...
A modern GPU is like a gigantic raging river ... and ANY 68k Amiga would be a dam with a single little hydro-electric turbine taking advantage of it... |
|
| Status: Offline |
|
|
matthey
| |
Re: Amiga SIMD unit
Posted on 22-Sep-2020 3:40:50
| | [ #88 ] |
|
|
|
Elite Member
|
Joined: 14-Mar-2007
Posts: 2751
From: Kansas | | |
|
| Quote:
Lou wrote:
Ok how about...
A modern GPU is like a gigantic raging river ... and ANY 68k Amiga would be a dam with a single little hydro-electric turbine taking advantage of it... |
I would expect memory bandwidth to be the volume of river water in your analogy. A modern GPU on a gfx card would commonly have many small turbines placed on a distant river with losses transporting the electricity. A Heterogeneous System Architecture (HSA) would have the CPU and GPU turbines on the same river. A 68k turbine would be a small older design with surprising efficiency (instruction memory bandwidth efficency is industry leading while data memory bandwidth efficiency is competitive). Most engineers today want a few large CPU turbines to better utilize the bandwidth of water to produce a large quatity of electricity. HSA lets the GPU turbines use the bandwidth that the CPU turbines do not use and it may be worth considering that the CPU turbines do not need to be as big and that the CPU and GPU turbines could be more similar.
|
|
| Status: Offline |
|
|
Hammer
| |
Re: Amiga SIMD unit
Posted on 23-Sep-2020 4:31:03
| | [ #89 ] |
|
|
|
Elite Member
|
Joined: 9-Mar-2003
Posts: 6504
From: Australia | | |
|
| @matthey
Quote:
matthey wrote:
Quote:
Hammer wrote:
FYI, OpenGL was running on DirectX8 era GPUs which has floating point datatype for vertex shaders and integer datatype for pixel shaders. Rasterization hardware accelerates floating-point geometry into pixel grid which is integer datatype. Hombre's geometry power is about PS1 level.
|
The PS1 CPU didn't even have an FPU. The Geometry Transformation Engine (GTE) coprocessor used fixed point integers only (several parallel operations per instruction with separate register SIMD and MACs). Quality suffered though. Lack of sub-pixel accuracy projections caused wobbling objects and objects would jump several pixels in extreme cases (I also had the wobbling objects problem with a program using fixed point 3D projections I wrote in 68k assembler years ago). Perspective is not correct which looks wrong and can cause problems with clipping and textures. The PS1 did not even have a z-buffer which Hombre supposedly would have had. Floating point can be done using integer math but short cuts were made to keep it fast. Sacrificing 3D quality isn't really an option today so floating point performance in hardware is important.
|
PC 3D games such as Quake used FPU for its geometry and PA-7100 CPU has an integrated FPU and PA-RISC's MAX-1 integer SIMD is useful for integer pixel shading (e.g. DX8 PS).
Commodore added extra fix function 3D hardware (e.g. texture mapper, Z-buffer resolve, Gouraud shading) to PA-RISC 7150 type CPU to turn it into 3D processor which is OpenGL compliant.
Quote:
matthey wrote:
Quote:
Lou wrote:
I think you guys were missing the point that the pedal bike would still be a 10 or 12 speed bike with skinny tires. The engine would burn the tires off the rim... I'm not talking full motor-cycle chasis here...
|
Was x86 which outperformed and killed PPC with only 8 GP registers a mono-cycle then?
|
On x86's 8 GPR issue, X86 evolved with "register renaming" feature.
AMD's Jaguar CPU is a dual instruction issue per cycle with 128-bit AVX** SIMD design and Xbox One X has 8 Jaguar CPUs with 40 CU GCN.
**Subset of 256-bit AVX.
68080's quad instruction issue per cycle design needs to scale towards four CPU cores, gain 128-bit SIMD units and >1.5Ghz clock speed.
AMD's Jaguar CPU (dual instruction issue, two ALUs, 128-bit FADD,128-bit FMUL) is inferior to Intel's Core 2 CPU (quad-instruction issue, three ALUs with ports shared with 128-bit FADD, and 128-bit FMUL).
Last edited by Hammer on 23-Sep-2020 at 04:45 AM.
Last edited by Hammer on 23-Sep-2020 at 04:33 AM.
_________________
Amiga 1200 (rev 1D1, KS 3.2, PiStorm32/RPi CM4/Emu68)
Amiga 500 (rev 6A, ECS, KS 3.2, PiStorm/RPi 4B/Emu68)
Ryzen 9 7950X, DDR5-6000 64 GB RAM, GeForce RTX 4080 16 GB |
|
| Status: Offline |
|
|
matthey
| |
Re: Amiga SIMD unit
Posted on 24-Sep-2020 1:26:52
| | [ #90 ] |
|
|
|
Elite Member
|
Joined: 14-Mar-2007
Posts: 2751
From: Kansas | | |
|
| Quote:
Hammer wrote:
PC 3D games such as Quake used FPU for its geometry and PA-7100 CPU has an integrated FPU and PA-RISC's MAX-1 integer SIMD is useful for integer pixel shading (e.g. DX8 PS).
|
Quake was a game changer which pushed x86 hardware to support floating point performance for 3D instead of quality for non-game applications. Later T&L 3D gfx card support was another game changer which lessened the need for CPU FP performance but FP performance was here to stay.
Quote:
Commodore added extra fix function 3D hardware (e.g. texture mapper, Z-buffer resolve, Gouraud shading) to PA-RISC 7150 type CPU to turn it into 3D processor which is OpenGL compliant.
|
Yes, fixed point integers can be used for part of the 3D rendering and this mixed integer and FP workload was often faster with early processors with minimal FP support. PA-RISC's MAX-1 simple integer SIMD was weak and limiting as it only supported 2x16 bit ops. The PS1 hardware was higher performance for integers but also restrictive, clocked lower and had no FP support. It looks like the Hombre would have had more features and would have been more versatile but both systems are primitive. We should remember the constraints like 3MB of memory for the PS1. Both hardware was dead end. PA-RISC could not easily add SIMD fp support (FP in the integer file and only 2xSP in a 64 bit wide register) and the PS2 Emotion Engine was a redesign with strong FP support.
OpenGL was released in mid 1992 by SGI so was new during planning for Hombre. The SGI RealityEngine 3D gfx hardware used an Intel i860 processor which is a unique VLIW processor. It has good theoretical fp performance which was difficult to extract and still performed better with a mixed integer and fp workload. Using FP datatypes and algorithms is often simpler with nicer results even if slower.
Quote:
On x86's 8 GPR issue, X86 evolved with "register renaming" feature.
|
Register renaming helps performance more with fewer registers. x86 was still at a disadvantage to 32 register RISC in memory traffic but it didn't make as much of a difference in performance as expected. Only 8 XMM FPU/SIMD registers actually made a bigger difference to FP performance. "Performance Characterization of the 64-bit x86 Architecture from Compiler Optimizations Perspective" compared the x86_64 with 16 GP integer and 16 SIMD registers to x86 with 8 GP integer and 8 SIMD registers using benchmarks and found the following.
CINT2000 42% more memory traffic, 4.4% performance loss
CFP2000 78% more memory traffic, 5.6% performance loss
The data memory traffic performance disadvantage practically disappeared with x86_64 but so did much of the instruction memory traffic performance advantage with larger code size.
Quote:
AMD's Jaguar CPU is a dual instruction issue per cycle with 128-bit AVX** SIMD design and Xbox One X has 8 Jaguar CPUs with 40 CU GCN.
**Subset of 256-bit AVX.
68080's quad instruction issue per cycle design needs to scale towards four CPU cores, gain 128-bit SIMD units and >1.5Ghz clock speed.
AMD's Jaguar CPU (dual instruction issue, two ALUs, 128-bit FADD,128-bit FMUL) is inferior to Intel's Core 2 CPU (quad-instruction issue, three ALUs with ports shared with 128-bit FADD, and 128-bit FMUL).
|
The FP performance per x86_64 core is impressive but those cores are massive. In contrast, the Apollo Core is weak at FP performance and ISA decisions make it difficult to improve like PA-RISC. It looks destined to repeat a common SIMD mistake with lots of SIMD baggage if it ever tries to scale to higher performance. Microsoft was talking about supporting 80+ cores in 2003 but it looks like CPU cores are for single threaded performance while GPU cores are for parallel core processing. HSA with hybrid CPU+GPU cores makes cache coherence and scheduling easier but it appears the CPU cores keep getting bigger for single thread performance and GPU cores keep getting more specialized for high latency parallel operation. Maybe it will work on a small scale with the Libre project though.
Last edited by matthey on 22-Oct-2020 at 06:18 AM.
Last edited by matthey on 24-Sep-2020 at 02:12 PM.
Last edited by matthey on 24-Sep-2020 at 01:27 AM.
|
|
| Status: Offline |
|
|
Hammer
| |
Re: Amiga SIMD unit
Posted on 24-Sep-2020 4:41:27
| | [ #91 ] |
|
|
|
Elite Member
|
Joined: 9-Mar-2003
Posts: 6504
From: Australia | | |
|
| @matthey
Quote:
Quake was a game changer which pushed x86 hardware to support floating point performance for 3D instead of quality for non-game applications. Later T&L 3D gfx card support was another game changer which lessened the need for CPU FP performance but FP performance was here to stay.
|
From https://twitter.com/SebAaltonen/status/1063153928857104384
Mesh+task shaders finally fix the huge mistake done way back when hardware T&L was introduced. PS2 programmable geometry pipe was way superior to hardware T&L, vertex shaders, geometry shaders, domain shaders and hull shaders. RTX cards finally make rasterization good again.
from Sebastian Aaltonen (principal engineer at Unity).
Quote:
Yes, fixed point integers can be used for part of the 3D rendering and this mixed integer and FP workload was often faster with early processors with minimal FP support. PA-RISC's MAX-1 simple integer SIMD was weak and limiting as it only supported 2x16 bit ops.
|
FYI, DirectX8's pixel shaders are INT16s.
Quote:
The PS1 hardware was higher performance for integers but also restrictive, clocked lower and had no FP support. It looks like the Hombre would have had more features and would have been more versatile but both systems are primitive. We should remember the constraints like 3MB of memory for the PS1. Both hardware was dead end. PA-RISC could not easily add SIMD fp support (FP in the integer file and only 2xSP in a 64 bit wide register) and the PS2 Emotion Engine was a redesign with strong FP support.
|
PS1 and Hombre were 1994-1995 era designs.
There are paths adding FP SIMD on PA-RISC when X86 CPUs managed to pull it off e.g.
1. Intel's SSE 128bit SIMD support was added to X86 with a seperate XMM registers.
2. AMD's 3DNow added 64bit wide (FP) SIMD on the existing X87 registers which also used by 64bit wide MMX integer SIMD.
Quote:
Register renaming helps performance more with fewer registers. x86 was still at a disadvantage to 32 register RISC in memory traffic but it didn't make as much of a difference in performance as expected. Only 8 XMM FPU/SIMD registers actually made a bigger difference to FP performance. "Performance Characterization of the 64-bit x86 Architecture from Compiler Optimizations Perspective" compared the x86_64 with 16 GP and SIMD registers to x86 with 8 GP and SIMD registers using benchmarks and found the following.
|
For X86's memory traffic issue with 8 registers, X86 has instruction compression via it's CISC nature.
https://techreport.com/review/8131/64-bit-computing-in-theory-and-practice/

Both the Pentium 4 and Athlon 64 gain significantly with the 64-bit version of picCOLOR. Compared directly the to 32-bit version of the program without inline MMX assembly code, the 64-bit version of picCOLOR is quite a bit faster. In a bit of drama, the Athlon 64 4000+ manages to leapfrog the Pentium 4 660 during the move to 64 bitsthe P4 is faster in 32 bits, but the Athlon 64 benefits more from using the x86-64 ISA.
X86-64 gain is dependent on hardware implementation.

Another X86-64 gain when compared to X86-32.
AMD K8's SSE hardware support
128bit FADD SSE1, quad packed FP32
64bit FMUL SSE1, quad packed FP32
64bit FADD SSE2, dual packed FP64
64bit FMUL SSE2, dual packed FP64
Intel Core 2 was the first X86 CPU with SSE1/SSE2 128-bit FADD and 128-bit FMUL hardware support.
Forward compatibility 128-bit SSE1/SSE2 instruction set on 64-bit wide SIMD hardware (e.g. K7 Athlon XP, Pentium IV) was preparing for 128-bit SIMD hardware evolution.
AVX-512 includes 32 register model, but Xbox Series X and PS5 have AVX2 hardware support which impacts mainstream game development just as AMD Jaguar's 128bit wide SIMD units influenced mainstream game development in XBO/PS4 era game development.
On 28 nm process tech, AMD Jaguar CPU is slightly larger than ARM Cortex A15 CPU.
 Last edited by Hammer on 24-Sep-2020 at 05:02 AM.
Last edited by Hammer on 24-Sep-2020 at 04:59 AM.
Last edited by Hammer on 24-Sep-2020 at 04:54 AM.
Last edited by Hammer on 24-Sep-2020 at 04:43 AM.
_________________
Amiga 1200 (rev 1D1, KS 3.2, PiStorm32/RPi CM4/Emu68)
Amiga 500 (rev 6A, ECS, KS 3.2, PiStorm/RPi 4B/Emu68)
Ryzen 9 7950X, DDR5-6000 64 GB RAM, GeForce RTX 4080 16 GB |
|
| Status: Offline |
|
|
Lou
| |
Re: Amiga SIMD unit
Posted on 24-Sep-2020 18:16:56
| | [ #92 ] |
|
|
|
Elite Member
|
Joined: 2-Nov-2004
Posts: 4259
From: Rhode Island | | |
|
| @Hammer
The 2017 Xbox One X gpu is the RX 490 we never got... /sigh
Advantages over the RX 480:
- 384 bit bus (vs 256 bit)
- 12 GB (vs 4 and 8 GB versions)
- 40 CUs (vs 36)
The RX 580 was the 16nm 480 moved 14nm process... it clocked marginally higher but used 20-30 less watts at the same clock speed.
The RX 590 should have been called a RX 680 since it was just the 580 moved to 12nm hence they spent the power budget on clocking it 8-10% faster than the 580 but was otherwise identical to the 480/580...
I own a 480 that has been reflashed into a 580 as well as an actual 580.
I just ordered a 590 from ebay for poops and giggles...
So to summarize:
480->580 was improved performance per watt
580->590 improved clockspeed and hence greater power usage Last edited by Lou on 24-Sep-2020 at 06:22 PM.
Last edited by Lou on 24-Sep-2020 at 06:20 PM.
Last edited by Lou on 24-Sep-2020 at 06:20 PM.
Last edited by Lou on 24-Sep-2020 at 06:18 PM.
|
|
| Status: Offline |
|
|
matthey
| |
Re: Amiga SIMD unit
Posted on 24-Sep-2020 20:50:31
| | [ #93 ] |
|
|
|
Elite Member
|
Joined: 14-Mar-2007
Posts: 2751
From: Kansas | | |
|
| Quote:
Hammer wrote:
@matthey
From https://twitter.com/SebAaltonen/status/1063153928857104384
Mesh+task shaders finally fix the huge mistake done way back when hardware T&L was introduced. PS2 programmable geometry pipe was way superior to hardware T&L, vertex shaders, geometry shaders, domain shaders and hull shaders. RTX cards finally make rasterization good again.
from Sebastian Aaltonen (principal engineer at Unity).
|
Hardware T&L gave enough of a performance boost to gfx cards when gfx buses were slow that older non T&L cards quickly became obsolete (contributed to the downfall of 3dfx). Fixed pipelines and fewer variables usually result in lower power designs which allowed more low end hardware to support 3D. Today, we have fast gfx buses and HSA with ray tracing requirements pushing 3D toward more dynamic and versatile parallel pipelines. For lower end hardware, ray tracing does use more power than rasterization but more realistic lighting, shadows and reflections are included with no additional cost. Even consoles with power constraints can do ray tracing. Perhaps even the PS2 hardware could do ray tracing at lower resolutions. The two vector units doing most of the parallel workloads are programmable and versatile which is part of what is needed.
Quote:
FYI, DirectX8's pixel shaders are INT16s.
|
PA-RISC MAX-1 supported the needed 16 bit datatype with SIMD but superscalar parallelism could likely match it in some other CPUs of the time. PA-RISC did support saturating math which is often helpful for images. Still, the 68060 MPEG-1 decoding performance was not far behind PA-RISC with MAX-1 (an application which HP chose to show off the MAX-1 SIMD performance boost) so DSP like workloads were not always that enhanced. Sometimes, the SIMD unit isn't even versatile enough to use.
Quote:
For X86's memory traffic issue with 8 registers, X86 has instruction compression via it's CISC nature.
|
8086 is the most compact but lost code density when enhanced to x86. x86 lost code density when enhanced to x86_64. Code density loss can be minimized by using the stack, byte sized datatypes and only using the first 8 GP registers which the 8086 encoding was optimized for but this lowers performance as data memory traffic increases offsetting the gains of reduced instruction memory traffic from better code density. Compilers usually optimize for reduced data memory traffic and don't even consider instruction memory traffic unless optimizing for size where x86_64 data memory traffic goes through the roof (the 68k does not exhibit this problem as smaller code usually reduces overall I+D memory traffic). Optimized x86_64 code has better code density than traditional RISC like MIPS, SPARC and PPC but is similar to RISC-V compressed and AArch64. Much of the CISC instruction compression advantage has been lost with x86_64.
Quote:
https://techreport.com/review/8131/64-bit-computing-in-theory-and-practice/
Both the Pentium 4 and Athlon 64 gain significantly with the 64-bit version of picCOLOR. Compared directly the to 32-bit version of the program without inline MMX assembly code, the 64-bit version of picCOLOR is quite a bit faster. In a bit of drama, the Athlon 64 4000+ manages to leapfrog the Pentium 4 660 during the move to 64 bitsthe P4 is faster in 32 bits, but the Athlon 64 benefits more from using the x86-64 ISA.
X86-64 gain is dependent on hardware implementation.
Another X86-64 gain when compared to X86-32.
|
Most of the x86_64 gain came from doubling the number of GP integer and SIMD registers which will vary by hardware but should be around 5% on average. There are other ISA changes which could make a larger difference for specific algorithms. Some algorithms with low data memory traffic and not needing many registers are faster with the more compact 32 bit code and these benefit from faster load times as well.
Quote:
AMD K8's SSE hardware support
128bit FADD SSE1, quad packed FP32
64bit FMUL SSE1, quad packed FP32
64bit FADD SSE2, dual packed FP64
64bit FMUL SSE2, dual packed FP64
Intel Core 2 was the first X86 CPU with SSE1/SSE2 128-bit FADD and 128-bit FMUL hardware support.
Forward compatibility 128-bit SSE1/SSE2 instruction set on 64-bit wide SIMD hardware (e.g. K7 Athlon XP, Pentium IV) was preparing for 128-bit SIMD hardware evolution.
AVX-512 includes 32 register model, but Xbox Series X and PS5 have AVX2 hardware support which impacts mainstream game development just as AMD Jaguar's 128bit wide SIMD units influenced mainstream game development in XBO/PS4 era game development.
On 28 nm process tech, AMD Jaguar CPU is slightly larger than ARM Cortex A15 CPU.
|
Much of the area of modern SoC chip goes into caches and GPU parallelism. Maybe this makes the area of powerful SIMD units seem smaller. It's interesting how CPU SMP+SIMD and GPU SIMT+SIMD parallelism have grown so far apart when the datatypes used are similar.
|
|
| Status: Offline |
|
|
Hammer
| |
Re: Amiga SIMD unit
Posted on 25-Sep-2020 0:14:38
| | [ #94 ] |
|
|
|
Elite Member
|
Joined: 9-Mar-2003
Posts: 6504
From: Australia | | |
|
| @Lou
Quote:
Lou wrote:
@Hammer
The 2017 Xbox One X gpu is the RX 490 we never got... /sigh
Advantages over the RX 480:
- 384 bit bus (vs 256 bit)
- 12 GB (vs 4 and 8 GB versions)
- 40 CUs (vs 36)
The RX 580 was the 16nm 480 moved 14nm process... it clocked marginally higher but used 20-30 less watts at the same clock speed.
The RX 590 should have been called a RX 680 since it was just the 580 moved to 12nm hence they spent the power budget on clocking it 8-10% faster than the 580 but was otherwise identical to the 480/580...
I own a 480 that has been reflashed into a 580 as well as an actual 580.
I just ordered a 590 from ebay for poops and giggles...
So to summarize:
480->580 was improved performance per watt
580->590 improved clockspeed and hence greater power usage
|
I agree with your comments on the missing RX-490 SKU.
AMD's RTG didn't upgrade R9-390X 44 CU with Polaris + X1X improvements e.g. higher clock speed, delta color compression, 2MB L2 cache, native INT16/FP16 data type support, and X1X's 2MB render cache.
I owned MSI R9-390X Gaming X prior to MSI GTX 980 Ti Gaming X.
AMD's RTG was also busy with designing three game console APUs for Microsoft and Sony i.e.
Xbox Series X, 56 CU RDNA 2 with 8 cores Zen 2. 52 CU active.
Xbox Series S, 22(?) CU RDNA 2 with 8 cores Zen 2. 20 CU active.
PS5, 40 CU RDNA 2 with 8 cores Zen 2. 36 CU active.
Xbox Series S APU would be a nice upgrade for PC's Ryzen 4700 series APUs.
Last edited by Hammer on 25-Sep-2020 at 12:21 AM.
_________________
Amiga 1200 (rev 1D1, KS 3.2, PiStorm32/RPi CM4/Emu68)
Amiga 500 (rev 6A, ECS, KS 3.2, PiStorm/RPi 4B/Emu68)
Ryzen 9 7950X, DDR5-6000 64 GB RAM, GeForce RTX 4080 16 GB |
|
| Status: Offline |
|
|
Hammer
| |
Re: Amiga SIMD unit
Posted on 25-Sep-2020 0:37:21
| | [ #95 ] |
|
|
|
Elite Member
|
Joined: 9-Mar-2003
Posts: 6504
From: Australia | | |
|
| @matthey
Quote:
8086 is the most compact but lost code density when enhanced to x86. x86 lost code density when enhanced to x86_64. Code density loss can be minimized by using the stack, byte sized datatypes and only using the first 8 GP registers which the 8086 encoding was optimized for but this lowers performance as data memory traffic increases offsetting the gains of reduced instruction memory traffic from better code density. Compilers usually optimize for reduced data memory traffic and don't even consider instruction memory traffic unless optimizing for size where x86_64 data memory traffic goes through the roof (the 68k does not exhibit this problem as smaller code usually reduces overall I+D memory traffic). Optimized x86_64 code has better code density than traditional RISC like MIPS, SPARC and PPC but is similar to RISC-V compressed and AArch64. Much of the CISC instruction compression advantage has been lost with x86_64
|
For Quake 3 workloads on PowerPC (IBM PowerPC 970) vs X86 (AMD K8 Athlon 64 or Intel Core 2),
1. X86 has the advantage of lower front side bus traffic when shifting data between integer GPRs and FP SIMD registers while PowerPC incurred the FSB (front-side-bus) memory traffic performance hit.
2. X86's stack-based architecture was optimized for C/C++ style function calls.
3. PowerPC's 128-bit Altivec SIMD advantage was negated with Core 2's full 128-bit SIMD support for ADD and MUL functions. AMD K8 Athlon 64 has 128-bit FADD SSE1.
4. For high frame rate gaming, the interaction between CPU+NB and PCI-e GPU needs to be the lowest latency. PowerPC 970's Northbridge is shit.
------------
For X86,
Intel AVX 2 includes GPU style gather instructions.
Intel AVX-512 includes GPU style scatter instructions. Intel AVX-512 includes the AI-related instruction set.
https://youtu.be/-w7wUs30OXk
Dev Diaries: The CPU driven BVH Ray Tracing in World of Tanks with Intel's Umbrella middleware.
BVH Ray Tracing with Intel's Umbrella middleware works fine on Ryzen 9 3900X's AVX 2.
Last edited by Hammer on 25-Sep-2020 at 12:52 AM.
Last edited by Hammer on 25-Sep-2020 at 12:50 AM.
Last edited by Hammer on 25-Sep-2020 at 12:39 AM.
Last edited by Hammer on 25-Sep-2020 at 12:38 AM.
_________________
Amiga 1200 (rev 1D1, KS 3.2, PiStorm32/RPi CM4/Emu68)
Amiga 500 (rev 6A, ECS, KS 3.2, PiStorm/RPi 4B/Emu68)
Ryzen 9 7950X, DDR5-6000 64 GB RAM, GeForce RTX 4080 16 GB |
|
| Status: Offline |
|
|
Lou
| |
Re: Amiga SIMD unit
Posted on 25-Sep-2020 17:34:59
| | [ #96 ] |
|
|
|
Elite Member
|
Joined: 2-Nov-2004
Posts: 4259
From: Rhode Island | | |
|
| @Hammer
yeah the PS4 Pro used an RX 470 with some Vega features...from what I understand...
Wasn't the 390 just a refreshed 290? (like the 480/580) ... which was the precursor to the Vega line....as IIRC the top 290 Fury X used HBM memory.
I current top card is the Radeon VII, I have it mining ETH at >91 MH/s with it's 60 CUs... I'm looking forward to the RX 6900XT with 80 CU's... |
|
| Status: Offline |
|
|
Hammer
| |
Re: Amiga SIMD unit
Posted on 26-Sep-2020 0:32:03
| | [ #97 ] |
|
|
|
Elite Member
|
Joined: 9-Mar-2003
Posts: 6504
From: Australia | | |
|
| @Lou
PS4 Pro GPU has Rapid Pack Math (RPM) in common with Vega, but missing ROPS connection to multi-MB L2 cache.
X1X GPU has Polaris FP16 packing(which reduces the available 32bit ALUs, which doesn't happen on Vega) and 2MB render cache for ROPS. X1X GPU has TMU's 2MB L2 cache + ROPS 2MB render cache = 4MB
RX Vega 56/64 has 4MB L2 cache for both TMU and ROPS.
AMD wasn't able to scale quad Shader Engines (quad rasterization, quad geometry) from R9-290X for PS4 Pro, X1X, Vega 56/64 and VII.
R9-390X is a refreshed R9-290X with faster memory modules and some R9-290X AIB OC (add-in board vendors overclocks) can be re-flashed into R9-390X.
Xbox Series X's GPU is still dual Shader Engine RDNA 2 with 56 CU or 26 DCU.
PS5's GPU is a dual Shader Engine RDNA 2 with 40 CU or 20 DCU.
Big NAVI's quad Shader Engine layout can scale from either PS5's 20 DCU or XSX's 26 DCU designs, hence Big NAVI's total DCU count can scale from 40 DCU (80 CU equivalent) to 56 DCU (112 CU equivalent).
DCU = RDNA's dual compute unit which is closely linked together.
---------------
Mining ETH is mostly integer datatypes.
Turing RTX 2080 Ti's 68 SM units have 4352 integer and 4352 floating-point units.
VII has 4,096 INT/FP stream units and 64 scalar units with higher memory bandwidth.
Turing's delta color compression is disabled with CUDA workloads.
RTX 3090 is the Ethereum mining monster. https://wccftech.com/nvidia-geforce-rtx-3090-impressive-mining-performance-122-mhs-ethereum/
I prefer RTX due to hardware-accelerated raytracing in Blender3D.
Last edited by Hammer on 26-Sep-2020 at 12:43 AM.
Last edited by Hammer on 26-Sep-2020 at 12:41 AM.
Last edited by Hammer on 26-Sep-2020 at 12:40 AM.
Last edited by Hammer on 26-Sep-2020 at 12:32 AM.
_________________
Amiga 1200 (rev 1D1, KS 3.2, PiStorm32/RPi CM4/Emu68)
Amiga 500 (rev 6A, ECS, KS 3.2, PiStorm/RPi 4B/Emu68)
Ryzen 9 7950X, DDR5-6000 64 GB RAM, GeForce RTX 4080 16 GB |
|
| Status: Offline |
|
|
Lou
| |
Re: Amiga SIMD unit
Posted on 26-Sep-2020 13:57:27
| | [ #98 ] |
|
|
|
Elite Member
|
Joined: 2-Nov-2004
Posts: 4259
From: Rhode Island | | |
|
| @Hammer
Quote:
I fully expect an 80CU RX 6900XT to beat that and use less power while doing so...
If anything, the only reason it wouldn't would be due to lower memory bandwidth if the rumors are true. If AMD produces a card with HBM2e, then it won't even be a question.
...oh and it will probably cost 33% less if they do...Last edited by Lou on 26-Sep-2020 at 01:58 PM.
|
|
| Status: Offline |
|
|
Fl@sh
| |
Re: Amiga SIMD unit
Posted on 26-Sep-2020 21:27:21
| | [ #99 ] |
|
|
 |
Regular Member
 |
Joined: 6-Oct-2004
Posts: 253
From: Napoli - Italy | | |
|
| @all
About PPC Altivec G4/G5 vs Intel SSE1/SSE2 both, on paper, have same potentials.
Maybe Altivec is still more simple and similar to AVX/AVX2 ISA rather than SSE1/SSE2.
I.E. this is a link about all Altivec instruction set and yes we have also FMADD, even with FLOAT datatype, between vectors http://mirror.informatimago.com/next/developer.apple.com/hardware/ve/instruction_crossref.html#compare
For Altivec we have also much better human readable instructions and up until three arguments for instruction.
I don't know anything about apollo core due my lack of interest about 68k arch, but maybe some choices like AMMX simd implementation was generated due small fpga space, focusing on reusing transistor logic where possible.
IMHO much better bypass it for now and implement something more powerfull and future proof in a next bigger fpga version. Last edited by Fl@sh on 26-Sep-2020 at 09:30 PM.
_________________
Pegasos II G4@1GHz 2GB Radeon 9250 256MB
AmigaOS4.1 fe - MorphOS - Debian 9 Jessie |
|
| Status: Offline |
|
|
Hammer
| |
Re: Amiga SIMD unit
Posted on 28-Sep-2020 4:08:21
| | [ #100 ] |
|
|
|
Elite Member
|
Joined: 9-Mar-2003
Posts: 6504
From: Australia | | |
|
| @matthey
AMD's 3DNow optimizations for Quake II which are dual packed FP32 SIMD
https://www.tomshardware.com/reviews/amd,68-3.html
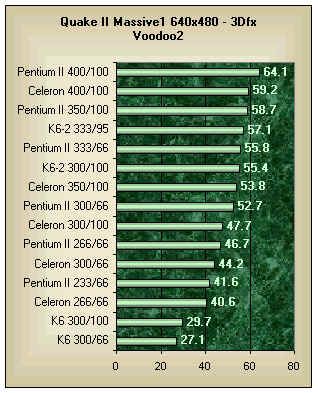 Last edited by Hammer on 28-Sep-2020 at 04:09 AM.
_________________
Amiga 1200 (rev 1D1, KS 3.2, PiStorm32/RPi CM4/Emu68)
Amiga 500 (rev 6A, ECS, KS 3.2, PiStorm/RPi 4B/Emu68)
Ryzen 9 7950X, DDR5-6000 64 GB RAM, GeForce RTX 4080 16 GB |
|
| Status: Offline |
|
|
