Your support is needed and is appreciated as Amigaworld.net is primarily dependent upon the support of its users.

|
|
|
|
| Poster | Thread |  Hammer Hammer
 |  |
Re: Is it game over for OS4
Posted on 11-Oct-2021 6:29:49
| | [ #161 ] |
| |
 |
Elite Member
 |
Joined: 9-Mar-2003
Posts: 5616
From: Australia | | |
|
| @matthey
Quote:
The G5 PPC 970 CPU used a 130nm chip fab process in 2003. A laptop was likely not practical at this process. The PPC 970FX used a 90nm process in 2004 and likely could have been used in a laptop with power saving features (added to 970MP in 2005) and a lower power north bridge chip. It was not because the currently used G4 CPUs had a better performance/W (power efficiency) which was better for a laptop.
|
Your argument is similar when I joined this forum in 2003.
AMD's K8 Athlon "Claw Hammer" and "Odessa" were available for mobile and fab'ed on 130nm process node.
For the year 2003, Mobile Athlon 64 2700+ "Claw Hammer" (1.6 GHz) has 35 watts including integrated northbridge.
For the year 2004, Mobile Athlon 64 3000+ "Odessa" (2 GHz) has 35 watts including integrated northbridge.
Depending on the ASIC design, 130 nm process node can be used for laptops.
-----
Why debate for PowerPC 970 when new 14 nm POWER 9 (4C, 16T) *is* available for purchase?
The major issue for POWER 9 is the motherboard's cost. POWER 9 (4C, 16T, ECC, PCIe 4.0)'s cost is closer to AMD Ryzen 7 5800X (8C, 16T, ECC, PCIe 4.0)'s $400 USD.
CPU is nothing without the motherboard.
Last edited by Hammer on 11-Oct-2021 at 06:30 AM.
_________________
Amiga 1200 (rev 1D1, KS 3.2, PiStorm32/RPi CM4/Emu68)
Amiga 500 (rev 6A, ECS, KS 3.2, PiStorm/RPi 4B/Emu68)
Ryzen 9 7900X, DDR5-6000 64 GB RAM, GeForce RTX 4080 16 GB |
| | Status: Offline |
| | Hammer
| |
Re: Is it game over for OS4
Posted on 11-Oct-2021 6:40:53
| | [ #162 ] |
| |
|
Elite Member
|
Joined: 9-Mar-2003
Posts: 5616
From: Australia | | |
|
| @NutsAboutAmiga
Quote:
Apple doesn't own TSMC. Apple M1 fab'ed on TSMC's 5 nm process node. Apple M1 doesn't have a VHS clone business model.
ARM Ltd's CPUs are not Apple M1 level.
TSMC's N7 ("7nm") transistor density is similar to Intel's 10 nm SuperFET.
AMD moves to TSMC's 6nm process node with Rembrandt APU that includes hardware raytracing capable RDNA 2 iGPU.
Single thread benchmarks don't show SMT-capable X86-64's CPU core's performance.
Last edited by Hammer on 11-Oct-2021 at 06:53 AM.
Last edited by Hammer on 11-Oct-2021 at 06:43 AM.
_________________
Amiga 1200 (rev 1D1, KS 3.2, PiStorm32/RPi CM4/Emu68)
Amiga 500 (rev 6A, ECS, KS 3.2, PiStorm/RPi 4B/Emu68)
Ryzen 9 7900X, DDR5-6000 64 GB RAM, GeForce RTX 4080 16 GB |
| | Status: Offline |
| | Hammer
| |
Re: Is it game over for OS4
Posted on 11-Oct-2021 7:23:01
| | [ #163 ] |
| |
|
Elite Member
|
Joined: 9-Mar-2003
Posts: 5616
From: Australia | | |
|
| @cdimauro
Quote:
It was the Pentium Pro (there is no Pentium 6), and it's only an internal detail of the micro-architecture.
PentiumPro, as well ALL x86 processors, are CISC processors, and that's they advantage compared to RISCs.
|
To enable efficient pipelining, Pentium Pro (P6) converts variable-length instructions into fix-length instructions. Fix-length instructions are one of the major pillars of RISC idealogy.
AMD K5 has 29K variant RISC core with X86 decoders. AMD K6 has "RISC86".
Ryzen CPU design has clearly defined Load and Store units, hence X86 instructions with bundled load-store are broken down and allocated to individual functional units.
GpGPUs have scatter-gather instructions that combos multiple load or store functions. AVX v2 has gather instructions. AVX-512 have scatter instructions.
On modern X86-64 CPUs, most X86 instructions have single-cycle throughput e.g. fast single decoder path.
Pure RISC Taliban idealogy for small companies with low-budget resources.
Modern APU or SoC has extra specialized instructions e.g. hardware H.265 encoder and decoders.
AMD Rembrant APU has extra specialized instructions for hardware-accelerated raytracing via RDNA 2 iGPU. iGPUs and dGPUs include hardware-accelerated rasterization.
Modern GpGPU has memory decompression/compression e.g. delta color compression features.
Benchmarks like Geekbench leads to hardware optimized for encryption e.g. gaming the benchmarks. Geekbench is useless for raytracing workloads.
Apple M1 SoC includes hardware acceleration blocks.
Last edited by Hammer on 11-Oct-2021 at 07:44 AM.
Last edited by Hammer on 11-Oct-2021 at 07:27 AM.
Last edited by Hammer on 11-Oct-2021 at 07:24 AM.
_________________
Amiga 1200 (rev 1D1, KS 3.2, PiStorm32/RPi CM4/Emu68)
Amiga 500 (rev 6A, ECS, KS 3.2, PiStorm/RPi 4B/Emu68)
Ryzen 9 7900X, DDR5-6000 64 GB RAM, GeForce RTX 4080 16 GB |
| | Status: Offline |
| | redfox
| |
Re: Is it game over for OS4
Posted on 11-Oct-2021 18:19:51
| | [ #164 ] |
| |
|
Elite Member
|
Joined: 7-Mar-2003
Posts: 2072
From: Canada | | |
|
| @All

Last edited by redfox on 11-Oct-2021 at 06:21 PM.
|
| | Status: Offline |
| | cdimauro
| |
Re: Is it game over for OS4
Posted on 12-Oct-2021 6:15:14
| | [ #165 ] |
| |
 |
Elite Member
|
Joined: 29-Oct-2012
Posts: 3756
From: Germany | | |
|
| @Hammer
Quote:
Hammer wrote:
@cdimauro
Quote:
It was the Pentium Pro (there is no Pentium 6), and it's only an internal detail of the micro-architecture.
PentiumPro, as well ALL x86 processors, are CISC processors, and that's they advantage compared to RISCs.
|
To enable efficient pipelining, Pentium Pro (P6) converts variable-length instructions into fix-length instructions. Fix-length instructions are one of the major pillars of RISC idealogy.
AMD K5 has 29K variant RISC core with X86 decoders. AMD K6 has "RISC86".
Ryzen CPU design has clearly defined Load and Store units, hence X86 instructions with bundled load-store are broken down and allocated to individual functional units.
GpGPUs have scatter-gather instructions that combos multiple load or store functions. AVX v2 has gather instructions. AVX-512 have scatter instructions.
On modern X86-64 CPUs, most X86 instructions have single-cycle throughput e.g. fast single decoder path. |
As I've said before, those are implementation details: internal things which doesn't matter when we look at the RISC definition (and, viceversa, to the CISC one).
Even if a CISC implementation uses a RISC internal (which isn't the case, according to the PentiumPro designer), it doesn't mean that RISCs "won".
In fact, and as I've written on my article, this proves the exact opposite, instead. I have not the much time now, but I explain why very quickly.
Imagine to "extract" the internal RISC of such microarchitecture, and to directly expose it to the external world. So, you have completely removed the CISC ISA, and the processor is using the RISC one.
This RISC uses very long opcodes (112 bit for the PentiumPro, if I recall correctly) for its instructions.
Now imagine such a processor where even the most simple instruction takes 14 byte, and how much pressure it exercise over the entire memory hierarchy, from the L1 cache to the memory: this requires both A LOT of space and HUGE memory bandwidths at all levels.
It's clear that it completely destroys its performances.
This is the clear, and I think the definite, proof that the ISA matters!
It's the CISC ISA which allows to get so good performances, because it allows to use much less space AND also to compress much more "useful work" (that it's "unpacked" in realtime).
Quote:
| Pure RISC Taliban idealogy for small companies with low-budget resources. |
And imagine how much the SIMD's Gather and Scatter instructions, that you mentioned before, match with the RISC ideology. 
If I take a look at what RISC-V designers have done to support those kind of instructions, and I simply laugh: something so much complicated, that the claimed simplicity of RISCs is pure memory...
Quote:
Modern APU or SoC has extra specialized instructions e.g. hardware H.265 encoder and decoders.
AMD Rembrant APU has extra specialized instructions for hardware-accelerated raytracing via RDNA 2 iGPU. iGPUs and dGPUs include hardware-accelerated rasterization.
Modern GpGPU has memory decompression/compression e.g. delta color compression features. |
Correct.
Quote:
| Benchmarks like Geekbench leads to hardware optimized for encryption e.g. gaming the benchmarks. Geekbench is useless for raytracing workloads. |
Geekbench is pure garbage.
Better use real applications.
Quote:
| Apple M1 SoC includes hardware acceleration blocks. |
Yes, all those accelerators are the future. |
| | Status: Offline |
| | IridiumFX
| |
Re: Is it game over for OS4
Posted on 13-Oct-2021 13:59:02
| | [ #166 ] |
| |
 |
Member
 |
Joined: 7-Apr-2017
Posts: 80
From: London, UK | | |
|
| @cdimauro
Quote:
...
In fact, and as I've written on my article, this proves the exact opposite, instead. I have not the much time now, but I explain why very quickly.
Imagine to "extract" the internal RISC of such microarchitecture, and to directly expose it to the external world. So, you have completely removed the CISC ISA, and the processor is using the RISC one.
This RISC uses very long opcodes (112 bit for the PentiumPro, if I recall correctly) for its instructions.
Now imagine such a processor where even the most simple instruction takes 14 byte, and how much pressure it exercise over the entire memory hierarchy, from the L1 cache to the memory: this requires both A LOT of space and HUGE memory bandwidths at all levels.
It's clear that it completely destroys its performances.
|
I am afraid, that's not how it works. At all.
The CPU decoder breaks down the instruction into a multitude of micro-ops. It makes no sense to keep a micro op of 112 bits. what for?
you look like a good scholar, I am sure you'll appreciate this gift:
https://www.agner.org/optimize/instruction_tables.pdf
from page 149 you can see how many micro-ops you get, starting from the upper level CISC instruction.
the ISA only matters as much as you can design an efficient decoder and feed your RISC core.
thanks |
| | Status: Offline |
| | matthey
| |
Re: Is it game over for OS4
Posted on 14-Oct-2021 4:00:52
| | [ #167 ] |
| |
|
Elite Member
|
Joined: 14-Mar-2007
Posts: 2150
From: Kansas | | |
|
| IridiumFX Quote:
I am afraid, that's not how it works. At all.
|
That is why cdimauro wrote "imagine". It is a hypothetical example. A 32 bit (4 byte) wide fixed length RISC encodings already creates an instruction fetch bottleneck which Dr David Patterson is aware of in his "Design and Implementation of RISC I" paper.
page 11 Quote:
Besides these changes in implementation, RISC II also incorporates an important architectural change: It was made compatible with instruction caches equipped with an "Instruction-Format Expander". As was mentioned above, an important part of RISC I's simplicity is due to the constant-length instruction format length of 32 bits. However, this approach is rather wasteful of code space. Studies by Garrison and VanDyke showed that the introduction of one additional instruction format of 16-bit length could lead to a savings of 30% in overall code size. These short instruction utilize some of the previous unused op-codes, and their effect is equivalent to the original 32-bit instructions. The RISC II CPU offers to the computer-system designer the option of improving code density for the price of a "Instruction-Format Expander," i.e. a circuit placed in the instruction-fetch path that recognizes all short instructions and translates ("expands") them into their 32-bit equivalent. Such an expander may conveniently be placed in an instruction cache. An instruction cache with a "Predictive-Program-Counter" scheme has just been designed at U.C. Berkeley, and an expander will soon be added to it.
|
page 20 Quote:
While RISC I has substantially reduced the number of data accesses in all programs, the number of instruction accesses has increased. This is due in part to the number of NOPs introduced, and in part to the inefficient, fixed size encoding of the instructions. It is clear that successors to RISC I will have to address the issue of code density.
|
Common and simple instructions with a 4 byte wide fixed length encoding already increase the code size by ~30% in one study and David notes that "RISC programs were only about 50% larger than the programs for other machines". RISC architectures didn't move to an 8 byte wide fixed length encoding because it would be substantially more wasteful for simple instructions. A 12+ byte wide fixed length encoding would waste an absurd amount of code and is laughable as an external architecturally visible encoding but I believe cdimauro is suggesting that it is actually used as an internal micro-op encoding which the external encoding is expanded (decompressed) into.
It is interesting that the paper suggests a variable length instruction encoding for RISC II despite cdimauro referring to a fixed length encoding as one of the 4 pillars of RISC. RISC I and the successor architecture SPARC did end up with fixed length encodings but I still see these architectures as examples of RISC rather than as defining RISC. ARM Thumb2 and RISC-V variable length encodings are implemented in a similar way with the main purpose to provide shorter replacement 16 bit instructions of 32 bit instructions to improve code density but they miss the opportunity to reduce the number of instructions. The RISC philosophy is that the increased number of simpler instructions can be executed at a faster rate which was true when RISC was introduced but then CISC gained pipelined execution and now RISC had to increase clock speeds to keep up but the instruction fetch bottleneck and heat are limiting factors. OoO execution helped execute the many simple dependent instructions but this violates the philosophy of simple RISC and produces more heat. RISC can use OoO execution with micro-op instructions and instruction fusing but then what is left of the RISC philosophy?
IridiumFX Quote:
The CPU decoder breaks down the instruction into a multitude of micro-ops. It makes no sense to keep a micro op of 112 bits. what for?
|
A wider encoding allows for a decreased number of instructions and more powerful instructions. RISC breaks instructions up into many simple dependent instructions which have to be executed at a faster rate.
page 17 Quote:
In comparison of the static number of instructions and static size of programs we found that on the average RISC uses only two thirds more instructions than the VAX and about two fifths more than the PDP-11, in spite of the fact that RISC I has only very simple instructions and addressing modes. The most surprising result was that the RISC programs were only about 50% larger than the programs for the other machines even though code density optimization was virtually ignored.
|
RISC I decreased the clock cycle length as the instructions were simpler which made up for part of the increased number of instructions which needed to be executed but the big improvement in performance came from pipelining and decreased data accesses which were a bottleneck on the VAX and for some CISC architectures, especially the ones which had too few of registers, used the stack too much, passed function arguments on the stack (there was not enough memory for extensive inlining of functions then), etc. When CISC improved with pipelining to mostly executing single cycle instructions using a data cache, it was daunting for RISC cores to try to execute, say 66% or even 40% more, often dependent instructions. A well designed CISC architecture with 16 GP registers and a good ABI can reduce data access traffic to within a few percent of a 32 GP register RISC architecture while RISC has the handicap of having to deal with substantially more code and extra instructions to execute. RISC architectures improved too by adding more complex instructions which decreased the number of instructions and improved code density but were usually still at a code density disadvantage with a 32 bit fixed length encoding. A variable length encoding for RISC further improves code density but usually increases instead of decreases the number of instructions as a 16 bit encoding usually reduces the number of GP registers available. CISC has fewer and more powerful instructions to execute while RISC has to execute more weak instructions which are often dependent. Modern so called RISC has abandoned much of the original RISC philosophy in order to try to keep up yet the RISC propaganda remains.
IridiumFX Quote:
the ISA only matters as much as you can design an efficient decoder and feed your RISC core.
|
RISC ISAs generally have simple encodings to decode, especially for fixed length encodings. Unfortunately, CISC is usually judged based on x86(-64) which is a poor example. Sometimes there is not much difference between a so called RISC and CISC encoding. Take for example the ColdFire.
https://www.nxp.com/files-static/training_pdf/29147_COLDFIRE_CORES_WBT.pdf Quote:
This module introduces you to the variable-length RISC ColdFire architecture which gives customers greater flexibility to lower memory and system costs. Because instructions can be 16-, 32- or 48 bits long, code is packed tighter in memory resulting in better code density than traditional 32- and 64-bit RISC machines. More efficient use of on-chip memory reduces bus bandwidth and the external memory required, which results in lower system cost.
|
There is not a significant difference between the 68060 and ColdFire encoding besides the arbitrary cutoff of longer instructions so only 6 byte long instructions are allowed. The 68060 only allowed single cycle instruction execution up to 6 bytes long even though allowing 8 byte long instructions would have covered almost all frequently used 68k instructions and improved performance. Gunnar von Boehn suggested an 8 byte limit for the ColdFire.
https://community.nxp.com/t5/ColdFire-68K-Microcontrollers/Coldfire-compatible-FPGA-core-with-ISA-enhancement-Brainstorming/m-p/238714
It looks to me like the CISC 68060 decoder is very similar to the RISC ColdFire decoder right down to the arbitrary 6 byte limitation. There are no micro-ops and I wouldn't be surprised if the internal encoding has similarities to the external encoding but converted to a fixed length 6 byte encoding. Maybe that RISC stands for Reduced Instruction Set Cycles like the PPC. AmigaOS 4 users tend to be the RISC experts and would never be brainwashed by propaganda though.
Last edited by matthey on 14-Oct-2021 at 04:32 AM.
Last edited by matthey on 14-Oct-2021 at 04:23 AM.
Last edited by matthey on 14-Oct-2021 at 04:08 AM.
|
| | Status: Offline |
| | cdimauro
| |
Re: Is it game over for OS4
Posted on 14-Oct-2021 6:00:39
| | [ #168 ] |
| |
|
Elite Member
|
Joined: 29-Oct-2012
Posts: 3756
From: Germany | | |
|
| @IridiumFX Quote:
IridiumFX wrote:
@cdimauro Quote:
...
In fact, and as I've written on my article, this proves the exact opposite, instead. I have not the much time now, but I explain why very quickly.
Imagine to "extract" the internal RISC of such microarchitecture, and to directly expose it to the external world. So, you have completely removed the CISC ISA, and the processor is using the RISC one.
This RISC uses very long opcodes (112 bit for the PentiumPro, if I recall correctly) for its instructions.
Now imagine such a processor where even the most simple instruction takes 14 byte, and how much pressure it exercise over the entire memory hierarchy, from the L1 cache to the memory: this requires both A LOT of space and HUGE memory bandwidths at all levels.
It's clear that it completely destroys its performances. |
I am afraid, that's not how it works. At all.
The CPU decoder breaks down the instruction into a multitude of micro-ops. It makes no sense to keep a micro op of 112 bits. what for?
you look like a good scholar, I am sure you'll appreciate this gift:
https://www.agner.org/optimize/instruction_tables.pdf
from page 149 you can see how many micro-ops you get, starting from the upper level CISC instruction.
the ISA only matters as much as you can design an efficient decoder and feed your RISC core.
thanks |
matthey has already clarified most of the things, but let me add something to definitely put a tombstone to the false myth that modern CISCs have a RISC core inside, and that this is the reason why they are fast.
To rebut your last sentence (which is the myth, essentially) I extract something from page 149 of Agner's instructions manual (which I know and follows from years, BTW  ). ).
Let's pick the PUSH m instruction. As you can clearly see from the its entry on the table, it generates exactly one micro-op instruction on Pentium Pro, Pentium II and Pentium III.
Now let's take a look at what this instruction does:
1) it decrements the stack pointer (register SP);
2) it loads the operand from the memory location m;
3) it saves the loaded data to the memory address pointed by the stack pointer.
So, in one instruction you have what a RISC normally does in 3 instructions (2 if they include the decrement operation in load instructions. But this violats, again, the RISC principles: instructions should be simple). This clearly violats the pillars #2 (only load/store instructions can access memory) and #4 (instructions should be simple).
So, this example is enough to prove that the internal core which is processing those micro-ops is definitely NOT a RISC, rather another (more simplified) CISC.
Let me add a few more things, just to enforce the concept.
The first one is that, if you take a look at the table, you can see the some instructions require more cycles to be executed. This, again, violats pillar #4.
Second, if you count the number of micro-ops, you can see that you have HUNDRENDS of them. This violats pillar #1 (there should be a small set of instructions).
Third, and last, if you take this count you can see that the number of micro-ops in the ISA of this micro-CISC core are GREATHER THAN the number of x86 instructions. That's because a single x86 instruction can generate more than one micro-op (and they should be specialized to achieve the goal to emulate the behavior of the original x86 instruction).
So, and as you can see, I've proven that the statement that CISC cores use RISC cores inside to improve performance is wrong (and this was the opinion of the PentiumPro designer): it's a false myth which is part of the RISC propaganda which academics are spreading around since years to miserably their (false, because it's not anymore) totem.
@matthey Quote:
Common and simple instructions with a 4 byte wide fixed length encoding already increase the code size by ~30% in one study and David notes that "RISC programs were only about 50% larger than the programs for other machines". RISC architectures didn't move to an 8 byte wide fixed length encoding because it would be substantially more wasteful for simple instructions. A 12+ byte wide fixed length encoding would waste an absurd amount of code and is laughable as an external architecturally visible encoding but I believe cdimauro is suggesting that it is actually used as an internal micro-op encoding which the external encoding is expanded (decompressed) into. |
Exactly.
Because if you try to use externally, so exposing the internal RISC (which isn't a RISC: see above), will simply destroy the performances, due to the ridiculous side of those instructions.
Quote:
| It is interesting that the paper suggests a variable length instruction encoding for RISC II despite cdimauro referring to a fixed length encoding as one of the 4 pillars of RISC. |
It's interesting because, as I've reported on the historical excursus on my article, the RISC concepts were so ineffective (in the real world) that they (RISC promoters) had to regret from some pillars.
The fixed-length encoding is one the pillars which has fallen down first, as you have reported above.
Quote:
| RISC I and the successor architecture SPARC did end up with fixed length encodings but I still see these architectures as examples of RISC rather than as defining RISC. ARM Thumb2 and RISC-V variable length encodings are implemented in a similar way with the main purpose to provide shorter replacement 16 bit instructions of 32 bit instructions to improve code density but they miss the opportunity to reduce the number of instructions. The RISC philosophy is that the increased number of simpler instructions can be executed at a faster rate which was true when RISC was introduced but then CISC gained pipelined execution and now RISC had to increase clock speeds to keep up but the instruction fetch bottleneck and heat are limiting factors. OoO execution helped execute the many simple dependent instructions but this violates the philosophy of simple RISC and produces more heat. RISC can use OoO execution with micro-op instructions and instruction fusing but then what is left of the RISC philosophy? |
Indeed and good point: this is another reason why the RISC philosophy doesn't apply anymore.
There's a recent paper, again from prof. Patterson, which shows as 16-bit instructions fusion on RISC-V can solve the problem of poor performances of processors based on this ISA. The reason is that RISC-V lacks complex addressing modes, to report the more evident example.
I don't know if he doesn't understand that those proposals are essentially killing the RISC philosophy which is defined and promoted (bu him, especially) since 40 years, or it's simply part of the RISC propaganda that he continues to spread...
Quote:
| RISC I decreased the clock cycle length as the instructions were simpler which made up for part of the increased number of instructions which needed to be executed but the big improvement in performance came from pipelining and decreased data accesses which were a bottleneck on the VAX and for some CISC architectures, especially the ones which had too few of registers, used the stack too much, passed function arguments on the stack (there was not enough memory for extensive inlining of functions then), etc. When CISC improved with pipelining to mostly executing single cycle instructions using a data cache, it was daunting for RISC cores to try to execute, say 66% or even 40% more, often dependent instructions. A well designed CISC architecture with 16 GP registers and a good ABI can reduce data access traffic to within a few percent of a 32 GP register RISC architecture while RISC has the handicap of having to deal with substantially more code and extra instructions to execute. RISC architectures improved too by adding more complex instructions which decreased the number of instructions and improved code density but were usually still at a code density disadvantage with a 32 bit fixed length encoding. A variable length encoding for RISC further improves code density but usually increases instead of decreases the number of instructions as a 16 bit encoding usually reduces the number of GP registers available. CISC has fewer and more powerful instructions to execute while RISC has to execute more weak instructions which are often dependent. Modern so called RISC has abandoned much of the original RISC philosophy in order to try to keep up yet the RISC propaganda remains. |
Indeed. This is my thesis, and facts prove it.
Quote:
Quote:
IridiumFX [quote]
the ISA only matters as much as you can design an efficient decoder and feed your RISC core.
|
RISC ISAs generally have simple encodings to decode, especially for fixed length encodings. Unfortunately, CISC is usually judged based on x86(-64) which is a poor example. Sometimes there is not much difference between a so called RISC and CISC encoding. |
Correct. My ISA, for example, is a complete x86/x64 rewriting (so, it has all features of those ISAs, plus more. So, it's even much more complex), but its instructions are very easy to decode and only a few bits from the beginning of the opcodes are need to extract:
- the opcode length;
- memory extension(s), if present;
- memory displacement(s), if present;
- immediate value, if present.
This is another myth that has to be dismantled: CISCs are difficult to decode.
Quote:
Take for example the ColdFire.
https://www.nxp.com/files-static/training_pdf/29147_COLDFIRE_CORES_WBT.pdf Quote:
This module introduces you to the variable-length RISC ColdFire architecture which gives customers greater flexibility to lower memory and system costs. Because instructions can be 16-, 32- or 48 bits long, code is packed tighter in memory resulting in better code density than traditional 32- and 64-bit RISC machines. More efficient use of on-chip memory reduces bus bandwidth and the external memory required, which results in lower system cost.
|
There is not a significant difference between the 68060 and ColdFire encoding besides the arbitrary cutoff of longer instructions so only 6 byte long instructions are allowed. The 68060 only allowed single cycle instruction execution up to 6 bytes long even though allowing 8 byte long instructions would have covered almost all frequently used 68k instructions and improved performance. Gunnar von Boehn suggested an 8 byte limit for the ColdFire.
https://community.nxp.com/t5/ColdFire-68K-Microcontrollers/Coldfire-compatible-FPGA-core-with-ISA-enhancement-Brainstorming/m-p/238714
It looks to me like the CISC 68060 decoder is very similar to the RISC ColdFire decoder right down to the arbitrary 6 byte limitation. There are no micro-ops and I wouldn't be surprised if the internal encoding has similarities to the external encoding but converted to a fixed length 6 byte encoding. |
Well ColdFires aren't RISC, anyway...
Quote:
| Maybe that RISC stands for Reduced Instruction Set Cycles like the PPC. AmigaOS 4 users tend to be the RISC experts and would never be brainwashed by propaganda though. |
LOL
I fully agree (of course). 
P.S. Again, sorry, but I've no time to read.Last edited by cdimauro on 15-Oct-2021 at 06:10 AM.
|
| | Status: Offline |
| | Hammer
| |
Re: Is it game over for OS4
Posted on 15-Oct-2021 17:49:33
| | [ #169 ] |
| |
|
Elite Member
|
Joined: 9-Mar-2003
Posts: 5616
From: Australia | | |
|
| @cdimauro
Quote:
As I've said before, those are implementation details: internal things which doesn't matter when we look at the RISC definition (and, viceversa, to the CISC one).
Even if a CISC implementation uses a RISC internal (which isn't the case, according to the PentiumPro designer), it doesn't mean that RISCs "won".
|
Pentium Pro (P6) still has stack-based X87 FPU and it's partly pipelined. Classic X87 stack behavior still influences Pentium Pro (P6)'s X87 FPU. P6s FMUL unit isn't fully pipelined.
68060's FPU is not pipelined.
AMD's K7 Athlon has three fully pipelined X87 FPU and it's not limited by X87 stack issues. K7 Athlon crushed Pentium III in 3D Studio Max render time. K7 Athlon's FPU is superscalar and out-of-order processing capable.
https://www.anandtech.com/show/377/9
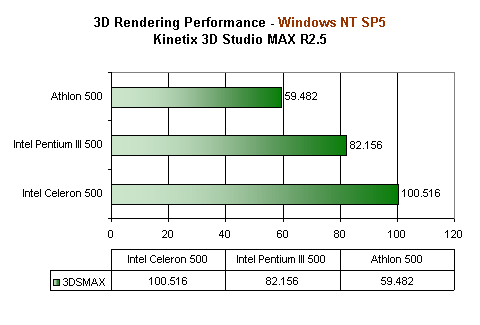
3D Studio Max render time (lower is better)
K7 Athlon @ 500Mhz, 59.48
Pentium III @ 500Mhz, 82.156
Athlon's FPU is seen in the 3D Studio MAX tests where, clock for clock, it dominates the Pentium III offering performance on par with that of a dual Pentium III 500 system (a claim made by Anandtech).
During the Intel Pentium III/Pentium IV era, my PC was AMD K7/K8 Athlon. I only switch back to Intel with Core 2 Duo. I have Pentium III Coppermine/Pentium IV/Pentium M laptops from the company and I didn't spend $$$ on them.
While Intel Pentium Pro's integer performance is strong, Intel Pentium Pro's FPU is weak when compared to DEC's Alpha.
AMD should have won in the market place but Intel was guilty of anti-competitive practices in the court of law.
Quote:
| This is the clear, and I think the definite, proof that the ISA matters! |
From https://www.youtube.com/watch?v=1-EnpufRSco
According to Jim Keller, on RISC vs CISC, Instruction sets don't matter.
K7 Athlon designers have beaten Pentium Pro/II/III (P6) designers. Apple avoids comparing its PowerPC marketing benchmarks against AMD Athlon.
Both Pentium III and K7 Athlon process the same X86/X87 instructions with different results.
K7 Athlon's design is closer to Alpha EV6 and both share the same EV6 frontside bus.
I'm going to use Jim Keller against your "Pentium Pro" designer.
When compared to Alpha's FPU, Pentium Pro/II/III's X87 FPU was an abomination.
Robert P. "Bob" Colwell was the chief IA-32 architect on the Pentium Pro, Pentium II, Pentium III, and Pentium 4 microprocessors. Colwell was in the era when Intel executed anti-competitive behavior. Pentium 4.... a joke CPU.
Last edited by Hammer on 15-Oct-2021 at 06:51 PM.
Last edited by Hammer on 15-Oct-2021 at 06:35 PM.
Last edited by Hammer on 15-Oct-2021 at 06:31 PM.
Last edited by Hammer on 15-Oct-2021 at 06:25 PM.
Last edited by Hammer on 15-Oct-2021 at 06:22 PM.
Last edited by Hammer on 15-Oct-2021 at 06:21 PM.
Last edited by Hammer on 15-Oct-2021 at 06:17 PM.
Last edited by Hammer on 15-Oct-2021 at 06:10 PM.
Last edited by Hammer on 15-Oct-2021 at 06:08 PM.
Last edited by Hammer on 15-Oct-2021 at 06:05 PM.
Last edited by Hammer on 15-Oct-2021 at 05:58 PM.
Last edited by Hammer on 15-Oct-2021 at 05:53 PM.
_________________
Amiga 1200 (rev 1D1, KS 3.2, PiStorm32/RPi CM4/Emu68)
Amiga 500 (rev 6A, ECS, KS 3.2, PiStorm/RPi 4B/Emu68)
Ryzen 9 7900X, DDR5-6000 64 GB RAM, GeForce RTX 4080 16 GB |
| | Status: Offline |
| | IridiumFX
| |
Re: Is it game over for OS4
Posted on 15-Oct-2021 18:44:29
| | [ #170 ] |
| |
|
Member
|
Joined: 7-Apr-2017
Posts: 80
From: London, UK | | |
|
| @cdimauro
Quote:
To rebut your last sentence (which is the myth, essentially) I extract something from page 149 of Agner's instructions manual (which I know and follows from years, BTW ).
Let's pick the PUSH m instruction. As you can clearly see from the its entry on the table, it generates exactly one micro-op instruction on Pentium Pro, Pentium II and Pentium III.
Now let's take a look at what this instruction does:
1) it decrements the stack pointer (register SP);
2) it loads the operand from the memory location m;
3) it saves the loaded data to the memory address pointed by the stack pointer.
So, in one instruction you have what a RISC normally does in 3 instructions (2 if they include the decrement operation in load instructions. But this violats, again, the RISC principles: instructions should be simple). This clearly violats the pillars #2 (only load/store instructions can access memory) and #4 (instructions should be simple).
So, this example is enough to prove that the internal core which is processing those micro-ops is definitely NOT a RISC, rather another (more simplified) CISC.
Let me add a few more things, just to enforce the concept.
The first one is that, if you take a look at the table, you can see the some instructions require more cycles to be executed. This, again, violats pillar #4.
|
With all due respect, unless we're reading different docs:
- PUSH r/i generates 3 micro-instructions
- PUSH m is generating 4 micro-instructions
- PUSH sr is generating 4 micro-instructions
the μops section is split in p0 to p4 and they have to be added together
Quoting Agner, "The number of μops that the instruction generates for each execution port."
as for your pillar #4, the one instruction per cycle is throughput, not execution time. You may remember even the IBM 801 and RISC I were pipelined. A pipeline implies multiple clock cycles execution.
I am pretty sure Intel designed the inner core the way it was more practical to themselves, without respecting any outer standard or philosophy, does not matter.
I am also not here to disprove your point, but just to address the bits that need to be corrected.
Quote:
P.S. Again, sorry, but I've no time to read.
|
no worries, I am super busy as well. That's why I try to keep my posts shortLast edited by IridiumFX on 15-Oct-2021 at 09:51 PM.
|
| | Status: Offline |
| | Hammer
| |
Re: Is it game over for OS4
Posted on 15-Oct-2021 19:01:45
| | [ #171 ] |
| |
|
Elite Member
|
Joined: 9-Mar-2003
Posts: 5616
From: Australia | | |
|
| @cdimauro
Quote:
Let's pick the PUSH m instruction. As you can clearly see from the its entry on the table, it generates exactly one micro-op instruction on Pentium Pro, Pentium II and Pentium III.
Now let's take a look at what this instruction does:
1) it decrements the stack pointer (register SP);
2) it loads the operand from the memory location m;
3) it saves the loaded data to the memory address pointed by the stack pointer.
So, in one instruction you have what a RISC normally does in 3 instructions (2 if they include the decrement operation in load instructions. But this violats, again, the RISC principles: instructions should be simple). This clearly violats the pillars #2 (only load/store instructions can access memory) and #4 (instructions should be simple).
So, this example is enough to prove that the internal core which is processing those micro-ops is definitely NOT a RISC, rather another (more simplified) CISC.
|
Complex PUSH instruction is acting like instruction compression for generating 3 simple instructions to feed the multiple parallel pipelines.
RISC ideology is moving that complexity into software.
_________________
Amiga 1200 (rev 1D1, KS 3.2, PiStorm32/RPi CM4/Emu68)
Amiga 500 (rev 6A, ECS, KS 3.2, PiStorm/RPi 4B/Emu68)
Ryzen 9 7900X, DDR5-6000 64 GB RAM, GeForce RTX 4080 16 GB |
| | Status: Offline |
| | cdimauro
| |
Re: Is it game over for OS4
Posted on 17-Oct-2021 7:40:40
| | [ #172 ] |
| |
|
Elite Member
|
Joined: 29-Oct-2012
Posts: 3756
From: Germany | | |
|
| @Hammer Quote:
Hammer wrote:
@cdimauro Quote:
As I've said before, those are implementation details: internal things which doesn't matter when we look at the RISC definition (and, viceversa, to the CISC one).
Even if a CISC implementation uses a RISC internal (which isn't the case, according to the PentiumPro designer), it doesn't mean that RISCs "won". |
Pentium Pro (P6) still has stack-based X87 FPU and it's partly pipelined. Classic X87 stack behavior still influences Pentium Pro (P6)'s X87 FPU. P6s FMUL unit isn't fully pipelined.
68060's FPU is not pipelined.
AMD's K7 Athlon has three fully pipelined X87 FPU and it's not limited by X87 stack issues. K7 Athlon crushed Pentium III in 3D Studio Max render time. K7 Athlon's FPU is superscalar and out-of-order processing capable.
https://www.anandtech.com/show/377/9
3D Studio Max render time (lower is better)
K7 Athlon @ 500Mhz, 59.48
Pentium III @ 500Mhz, 82.156
Athlon's FPU is seen in the 3D Studio MAX tests where, clock for clock, it dominates the Pentium III offering performance on par with that of a dual Pentium III 500 system (a claim made by Anandtech). |
I really don't understand why you have to insert your AMD propaganda when a discussion is about COMPLETELY DIFFERENT THINGS.
Can you show how, from the RISC vs CISC dispute, you ended by with your AMD propaganda? Which Pindaric fly have you made?
Anyway, the situation isn't so bad for Pentium: https://www.anandtech.com/show/355/23
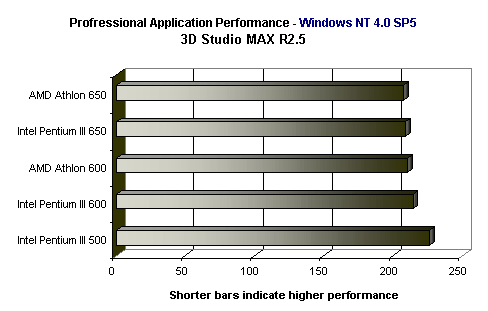
And since you're just cherry-picking what you like to promote your beloved AMD, I can do the same:
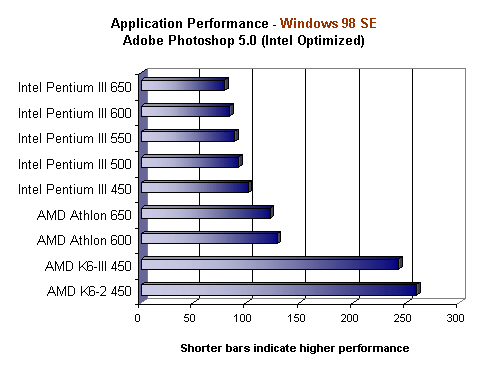
Goodbye AMD and Athlon...
Quote:
During the Intel Pentium III/Pentium IV era, my PC was AMD K7/K8 Athlon. I only switch back to Intel with Core 2 Duo. I have Pentium III Coppermine/Pentium IV/Pentium M laptops from the company and I didn't spend $$$ on them.
While Intel Pentium Pro's integer performance is strong, Intel Pentium Pro's FPU is weak when compared to DEC's Alpha. |
And now... you're even bringing DEC Alpha only to bash Intel?
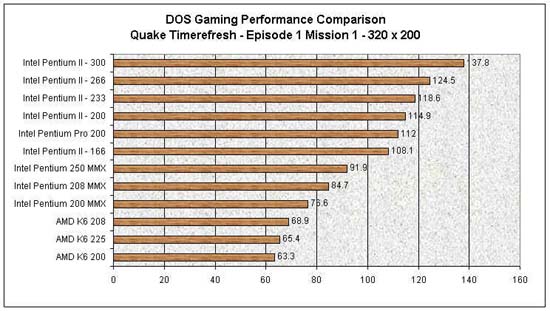
Why you didn't picked AMD? Simple: because its processors sucked compared to the PentiumPro:
https://www.anandtech.com/show/55/3
Quote:
| AMD should have won in the market place but Intel was guilty of anti-competitive practices in the court of law. |
That's only the wishful thinking of an AMD fanatic.
Quote:
First, and more important, who cares? I've PROVED with FACTS my thesis.
Second, you have misunderstood Keller, because it was about end reasults.
Quote:
K7 Athlon designers have beaten Pentium Pro/II/III (P6) designers. Apple avoids comparing its PowerPC marketing benchmarks against AMD Athlon.
Both Pentium III and K7 Athlon process the same X86/X87 instructions with different results.
K7 Athlon's design is closer to Alpha EV6 and both share the same EV6 frontside bus. |
Again your AMD propaganda, cherry-picking what do you like, only to put in good shape your beloved AMD.
Why haven't you reported the full list of x86 processors, starting from the 8086, and shown & compared Intel's and AMD ones?
Scared to show AMD sucked for very long time before Athlon?
Scared to show the complete AMD failure with Bulldozer & successors?
Quote:
| I'm going to use Jim Keller against your "Pentium Pro" designer. |
See above: who cares?
Quote:
| When compared to Alpha's FPU, Pentium Pro/II/III's X87 FPU was an abomination. |
See above: AMD propaganda + cherry-picking.
You're an AMD die-hard fanatic.
Quote:
| Robert P. "Bob" Colwell was the chief IA-32 architect on the Pentium Pro, Pentium II, Pentium III, and Pentium 4 microprocessors. Colwell was in the era when Intel executed anti-competitive behavior. Pentium 4.... a joke CPU. |
A joke? In your fervid imagination:
https://www.anandtech.com/show/866/7
https://www.anandtech.com/show/866/10
And from the conclusions:
https://www.anandtech.com/show/866/13
"the Northwood core is exactly what the Pentium 4 needed. While the processor may still not be the most affordable, it is finally competitive enough where a user wouldn't be able to tell the difference in speed between one and the fastest Athlon XP.
[...]
Both the Athlon XP 2000+ and the Pentium 4 2.2GHz processors"
A joke? What a beautiful joke, then.
But let's continue. It seems that you kike 3D Rending performances. Here we go:
https://www.anandtech.com/show/1031/16
https://www.anandtech.com/show/1031/17
https://www.anandtech.com/show/1031/18
A joke, right? Or rather a nightmare for your beloved AMD?
Let's see if you finally stop your ridiculous AMD propaganda. |
| | Status: Offline |
| | cdimauro
| |
Re: Is it game over for OS4
Posted on 17-Oct-2021 8:14:14
| | [ #173 ] |
| |
|
Elite Member
|
Joined: 29-Oct-2012
Posts: 3756
From: Germany | | |
|
| @IridiumFX Quote:
IridiumFX wrote:
@cdimauro Quote:
To rebut your last sentence (which is the myth, essentially) I extract something from page 149 of Agner's instructions manual (which I know and follows from years, BTW ).
Let's pick the PUSH m instruction. As you can clearly see from the its entry on the table, it generates exactly one micro-op instruction on Pentium Pro, Pentium II and Pentium III.
Now let's take a look at what this instruction does:
1) it decrements the stack pointer (register SP);
2) it loads the operand from the memory location m;
3) it saves the loaded data to the memory address pointed by the stack pointer.
So, in one instruction you have what a RISC normally does in 3 instructions (2 if they include the decrement operation in load instructions. But this violats, again, the RISC principles: instructions should be simple). This clearly violats the pillars #2 (only load/store instructions can access memory) and #4 (instructions should be simple).
So, this example is enough to prove that the internal core which is processing those micro-ops is definitely NOT a RISC, rather another (more simplified) CISC.
Let me add a few more things, just to enforce the concept.
The first one is that, if you take a look at the table, you can see the some instructions require more cycles to be executed. This, again, violats pillar #4. |
With all due respect, unless we're reading different docs:
- PUSH r/i generates 3 micro-instructions
- PUSH m is generating 4 micro-instructions
- PUSH sr is generating 4 micro-instructions
the μops section is split in p0 to p4 and they have to be added together
Quoting Agner, "The number of μops that the instruction generates for each execution port." |
You're right. I haven't read that part, and I've wrongly considered that Intel's uops table like it was for AMD. My fault.
So, Intel, for its latest processors, used to split instructions in multiple simpler uops.
However for AMD it's completely different, and this is for all of its modern processors, ranging from K7 to Zen3, and also for Bobcat and Jaguar.
On pag.10 of Agner's manual there's the PUSH instruction, which is split in two macro-ops (this is how AMD calls its internal instructions).
However this isn't particularly significant to the scope of the discussion, because PUSH (and POP) reads and writes memory to two different locations, so it makes sense to have dedicate instructions for both.
The most important thing comes if we take a look at the super-CISCy instructions which directly access memory and operate on its value.
On the same page we can find the ADD/ADC/SUB/SBB instructions, which are very common (but those aren't the only ones: you can see that many instructions fall on the pattern).
Let's take a look at the most complicated one:
ADD m,i
for example:
ADD DOUBLE WORD PTR [EBX+ECX*4+0x12345678],0x87654321
This instruction:
- loads the value from the 32-bit memory location which is found by calculating EBX+ECX*4+0x12345678;
- increments this value by 0x87654321;
- stores the result to the 32-bit memory location which is found by calculating EBX+ECX*4+0x12345678.
So, the above AMD processors execute all the above operations using ONE single macro-op.
I think that, at least this, clearly proves that the simplified core used internally by AMD cannot really be classified as RISC, and rather it's still a CISC one (and quite complex).
BTW, if you try to emulate what this instruction does with any RISC (either if it 100% aderent to the 4 pillars, or not) you can easily end-up by use much more than 3 instructions.
Quote:
| as for your pillar #4, the one instruction per cycle is throughput, not execution time. You may remember even the IBM 801 and RISC I were pipelined. A pipeline implies multiple clock cycles execution. |
Correct, but the pipeline is an invariant for all instructions (with some differences that might be found only for the branch ones), so this doesn't matter when talking about the execution time for istructions.
Specifically, what's important, and always referred to in benchmarks and in the literature, is the number of cycles that an instruction takes in its execution phase.
Usually it's called latency, but Agner called it Reciprocal throughput instead ("This is also called issue latency. This value indicates the average number of clock cycles from the execution of an instruction begins to a subsequent independent instruction of the same kind can begin to execute.").
Quote:
| I am pretty sure Intel designed the inner core the way it was more practical to themselves, without respecting any outer standard or philosophy, does not matter. |
I think the same.
Quote:
| I am also not here to disprove your point, but just to address the bits that need to be corrected. |
That's ok, and thanks for that.
Quote:
Quote:
P.S. Again, sorry, but I've no time to read. |
no worries, I am super busy as well. That's why I try to keep my posts short |
Well, the problem is exactly this: the lack of time didn't allowed me to read again the manual to refresh such important information, and I made a big mistake (I was recalling what AMD processor did, so I've wrongly assumed the same for Intel).
I should try to take more time, even when I talk of stuff which I'm informed about.
@Hammer Quote:
Hammer wrote:
@cdimauro
Quote:
Let's pick the PUSH m instruction. As you can clearly see from the its entry on the table, it generates exactly one micro-op instruction on Pentium Pro, Pentium II and Pentium III.
Now let's take a look at what this instruction does:
1) it decrements the stack pointer (register SP);
2) it loads the operand from the memory location m;
3) it saves the loaded data to the memory address pointed by the stack pointer.
So, in one instruction you have what a RISC normally does in 3 instructions (2 if they include the decrement operation in load instructions. But this violats, again, the RISC principles: instructions should be simple). This clearly violats the pillars #2 (only load/store instructions can access memory) and #4 (instructions should be simple).
So, this example is enough to prove that the internal core which is processing those micro-ops is definitely NOT a RISC, rather another (more simplified) CISC.
|
Complex PUSH instruction is acting like instruction compression for generating 3 simple instructions to feed the multiple parallel pipelines. |
Multiple execution units.
Anyway, the problem with PUSH (and POP) is that they are moving data from two different memory locations, as I've reported before.
This doesn't happen on AMD processors, where much more complicated instructions can use just one macro-op (and even execute in one cycle) because the referenced memory is exactly the same when both reading and writing.
Quote:
| RISC ideology is moving that complexity into software. |
That was the idea, at the very beginning (see my previous comments).
But it was a complete failure, and RISCs had to move complexity into the core. Caches is a first example. Another was pipelining. Then super-pipelining. And out-of-order execution was the last trick which has definitely put a tombstone on this topic: complexity NEEDS to be put into cores IF you want to have high performances. |
| | Status: Offline |
| | terminills
| |
Re: Is it game over for OS4
Posted on 17-Oct-2021 14:49:06
| | [ #174 ] |
| |
 |
AROS Core Developer
 |
Joined: 8-Mar-2003
Posts: 1474
From: Unknown | | |
|
| @cdimauro
I'm not going to go into your Intel propaganda I'll merely state what was happening at the time.
Being a system builder at the time I can tell you $ for $ the Athlon at the time demolished the Pentium III as the Pentium III was close to twice the price. However Hammer is correct Intel did strong arm shops into downplaying the value of the Athlon at the time.
_________________
Support AROS sponsor a developer.
"AROS is prolly illegal ~ Evert Carton" intentionally quoted out of context for dramatic effect |
| | Status: Offline |
| | kolla
| |
Re: Is it game over for OS4
Posted on 17-Oct-2021 18:09:01
| | [ #175 ] |
| |
 |
Elite Member
|
Joined: 21-Aug-2003
Posts: 3072
From: Trondheim, Norway | | |
|
| @terminills
Quote:
must resist
_________________
B5D6A1D019D5D45BCC56F4782AC220D8B3E2A6CC |
| | Status: Offline |
| | Rose
| |
Re: Is it game over for OS4
Posted on 17-Oct-2021 18:12:00
| | [ #176 ] |
| |
|
Cult Member
|
Joined: 5-Nov-2009
Posts: 982
From: Unknown | | |
|
| @kolla
I can't resist....
 |
| | Status: Offline |
| | NutsAboutAmiga
| |
Re: Is it game over for OS4
Posted on 17-Oct-2021 18:18:56
| | [ #177 ] |
| |
 |
Elite Member
|
Joined: 9-Jun-2004
Posts: 12857
From: Norway | | |
|
| | | Status: Offline |
| | NutsAboutAmiga
| |
Re: Is it game over for OS4
Posted on 17-Oct-2021 18:26:41
| | [ #178 ] |
| |
|
Elite Member
|
Joined: 9-Jun-2004
Posts: 12857
From: Norway | | |
|
| @cdimauro
Quote:
| and out-of-order execution was the last trick which has definitely put a tombstone |
The compiler can arrange the instructions, so they run out sequence before run time.
the task of talking a CISC instruction and braking it down to microcode (RISC) instruction before run time, is a unnecessary/useless action.
Anyway concept of microcode, you kind find in JIT compilers, like EMU68, its interesting how can ignore setting flags for example, because knows the flag is not read. Not sure micro code is dead, but maybe risc instructions is too complex as well.
But this thing keeps changing as new idea comes and goes. Im sure JIT compilers will continue get insperation from hardware, and hardware will continue to get insperation from software.Last edited by NutsAboutAmiga on 17-Oct-2021 at 06:32 PM.
Last edited by NutsAboutAmiga on 17-Oct-2021 at 06:31 PM.
Last edited by NutsAboutAmiga on 17-Oct-2021 at 06:28 PM.
_________________
http://lifeofliveforit.blogspot.no/
Facebook::LiveForIt Software for AmigaOS |
| | Status: Offline |
| | Rose
| |
Re: Is it game over for OS4
Posted on 17-Oct-2021 18:34:06
| | [ #179 ] |
| |
|
Cult Member
|
Joined: 5-Nov-2009
Posts: 982
From: Unknown | | |
|
| @NutsAboutAmiga
Quote:
There was PowerPC port of Win NT but it didn't kill x64. Arm version of Windows has been around and shipping for few years already on few tablets and ultralights.
Installbase of +1B will take care of x64 staying alive. |
| | Status: Offline |
| | NutsAboutAmiga
| |
Re: Is it game over for OS4
Posted on 17-Oct-2021 18:53:08
| | [ #180 ] |
| |
|
Elite Member
|
Joined: 9-Jun-2004
Posts: 12857
From: Norway | | |
|
| @Rose
Yes, because intel innovated, the beat was agents Intel in the 90s.
but then they implemented RISC style microcode.
https://en.wikipedia.org/wiki/Intel_Microcode
What the CPU does is translate CISC into micro code, and execute that instead.
https://en.wikipedia.org/wiki/Micro-operation
Backwards compatibly is a major feature, throwing out instructions, starting over, is complicated. creates incompatibilities, and is where time consuming, anyway I believe emulation techniques has improved lately, Apple being able to switch x86 quickly overnight, shows software companies do not need to be so faithful. (IBM was argonaut and did focus on desktop, they focused on Power chips for servers, the PowerPC chips was cut down version of that.)
Now microcode is also costly because adds another layer, that is not need on a pure RISC, like ARM64, or POWER chips. As POWER mostly focusing on servers, the ARM chips found its way into mobile phone, where they can't have large heat fans, and battery life was important.
Apple switch back to RISC, instead of PowerPC, they went with ARM, for laptops, M1 chip, does kick a puch, and is running with good battery life in laptops and tablets. Intel now has to compete with that. So now Intel is making ARM chips.
Desktop computers is more or less dead now. Its all mobile/tablets and laptops (lets not forget smart TVs), thats where the focus is.
Last edited by NutsAboutAmiga on 17-Oct-2021 at 07:59 PM.
Last edited by NutsAboutAmiga on 17-Oct-2021 at 07:04 PM.
Last edited by NutsAboutAmiga on 17-Oct-2021 at 07:01 PM.
Last edited by NutsAboutAmiga on 17-Oct-2021 at 06:59 PM.
Last edited by NutsAboutAmiga on 17-Oct-2021 at 06:58 PM.
Last edited by NutsAboutAmiga on 17-Oct-2021 at 06:57 PM.
_________________
http://lifeofliveforit.blogspot.no/
Facebook::LiveForIt Software for AmigaOS |
| | Status: Offline |
| |
|
|
|
[ home ][ about us ][ privacy ]
[ forums ][ classifieds ]
[ links ][ news archive ]
[ link to us ][ user account ]
|
