Your support is needed and is appreciated as Amigaworld.net is primarily dependent upon the support of its users.

|
|
|
|
| Poster | Thread |  Karlos Karlos
|  |
Re: Integrating Warp3D into my 3D engine
Posted on 20-Feb-2025 8:34:02
| | [ #121 ] |
| |
 |
Elite Member
 |
Joined: 24-Aug-2003
Posts: 4960
From: As-sassin-aaate! As-sassin-aaate! Ooh! We forgot the ammunition! | | |
|
| @michalsc
If we are looking for pathological cases, wouldn't adding a register toa memory location be worse than adding a memory location to the register? You've still got to load the value in from memory to modify it, then you have to push it back out. Last edited by Karlos on 20-Feb-2025 at 08:36 AM.
_________________
Doing stupid things for fun... |
| | Status: Offline |
| | Karlos
| |
Re: Integrating Warp3D into my 3D engine
Posted on 20-Feb-2025 10:54:11
| | [ #122 ] |
| |
|
Elite Member
|
Joined: 24-Aug-2003
Posts: 4960
From: As-sassin-aaate! As-sassin-aaate! Ooh! We forgot the ammunition! | | |
|
| @michalsc & @matthey
I've pushed an updated with the suggested third loop, where the fetches go into d2-d5, then those are summed. It also uses bne to simplify the loop. The second "unrolled 4x" is the that version.
I made sure the performance governer was off on my Amiberry machine and got the following results after running 3 times in a row (all runs were basically consistent anyway):
Got Timer, frequency is 709379 Hz
Iterations: 10000000, step: 3
Result: 30000000, expected 30000000
Time: 18789 EClock ticks (26 ms)
Unrolled (4x):
Result: 30000000, expected 30000000
Time: 7190 EClock ticks (10 ms)
Unrolled (4x):
Result: 30000000, expected 30000000
Time: 10510 EClock ticks (14 ms)
Last edited by Karlos on 20-Feb-2025 at 10:54 AM.
_________________
Doing stupid things for fun... |
| | Status: Offline |
| | Karlos
| |
Re: Integrating Warp3D into my 3D engine
Posted on 20-Feb-2025 11:15:31
| | [ #123 ] |
| |
|
Elite Member
|
Joined: 24-Aug-2003
Posts: 4960
From: As-sassin-aaate! As-sassin-aaate! Ooh! We forgot the ammunition! | | |
|
| Does anyone have a working PPC machine to test this under Petunia or Trance?
Then we can all get back to arguing over what the results mean  Last edited by Karlos on 20-Feb-2025 at 11:16 AM.
_________________
Doing stupid things for fun... |
| | Status: Offline |
| | Karlos
| |
Re: Integrating Warp3D into my 3D engine
Posted on 20-Feb-2025 11:59:07
| | [ #124 ] |
| |
|
Elite Member
|
Joined: 24-Aug-2003
Posts: 4960
From: As-sassin-aaate! As-sassin-aaate! Ooh! We forgot the ammunition! | | |
|
| @ZXDunny
Quote:
ZXDunny wrote:
Again, PiStorm32Lite CM4 at 2.2GHz:
Got Timer, frequency is 709379 Hz
Iterations: 10000000, step: 3
Result: 30000000, expected 30000000
Time: 89085 EClock ticks (125 ms)
Unrolled (4x):
Result: 30000000, expected 30000000
Time: 22325 EClock ticks (31 ms)
|
That unrolled loop is 2,500,000 iterations of 6 instructions. Using the extremely crude interpretation of 2,500,000 * 6 * 709379 / 22325, we get 476.7 68K "MIPS" out of it._________________
Doing stupid things for fun... |
| | Status: Offline |
| | michalsc
| |
Re: Integrating Warp3D into my 3D engine
Posted on 20-Feb-2025 12:04:39
| | [ #125 ] |
| |
 |
AROS Core Developer
 |
Joined: 14-Jun-2005
Posts: 440
From: Germany | | |
|
| @Karlos
For consistency would be better to use BNE in **all** loops, not only in one of them :) Anyway, the results are, hmm, interesting :)
|
| | Status: Offline |
| | Karlos
| |
Re: Integrating Warp3D into my 3D engine
Posted on 20-Feb-2025 14:15:08
| | [ #126 ] |
| |
|
Elite Member
|
Joined: 24-Aug-2003
Posts: 4960
From: As-sassin-aaate! As-sassin-aaate! Ooh! We forgot the ammunition! | | |
|
| @michalsc
I'll push an update later, but anyone can modify it, that's why it's on GitHub :D
One initial thought is that, as you said, branching is much more of a performance hit than the basic arithmetic operations here. On a 68060 I would hope the branch costs nothing in these cases.
This suggests that optimising for Emu68 might be more like optimising for 020 - you want to try and keep operands in registers and avoid looping. On 040/060, memory operands that are cached are generally OK. _________________
Doing stupid things for fun... |
| | Status: Offline |
| | Karlos
| |
Re: Integrating Warp3D into my 3D engine
Posted on 20-Feb-2025 18:47:42
| | [ #127 ] |
| |
|
Elite Member
|
Joined: 24-Aug-2003
Posts: 4960
From: As-sassin-aaate! As-sassin-aaate! Ooh! We forgot the ammunition! | | |
|
| @michalsc / anyone else interested.
Update pushed, now tests the impact of both prefetch and unrolling (2x, 4x, 8x) and the iteration count is increased by a factor of 5 to get a longer sample.
Results from Amiberry, (i7 mobile) JIT enabled:
Got Timer, frequency is 709379 Hz
Using 50000000 iterations, step size is 3
Test Case 0: Add mem to reg, tight loop
Result: 150000000, expected 150000000
Time: 100007 EClock ticks (140 ms)
Test Case 1: Add mem to reg, 2x unrolled
Result: 150000000, expected 150000000
Time: 50732 EClock ticks (71 ms)
Test Case 2: Add mem to reg, 4x unrolled
Result: 150000000, expected 150000000
Time: 34671 EClock ticks (48 ms)
Test Case 3: Add mem to reg, 8x unrolled
Result: 150000000, expected 150000000
Time: 27527 EClock ticks (38 ms)
Test Case 4: Add mem to reg, 2x unrolled, prefetched
Result: 150000000, expected 150000000
Time: 86221 EClock ticks (121 ms)
Test Case 5: Add mem to reg, 4x unrolled, prefetched
Result: 150000000, expected 150000000
Time: 50412 EClock ticks (71 ms)
Test Case 6: Add mem to reg, 8x unrolled, prefetched
Result: 150000000, expected 150000000
Time: 36353 EClock ticks (51 ms)
JIT disabled:
Got Timer, frequency is 709379 Hz
Using 50000000 iterations, step size is 3
Test Case 0: Add mem to reg, tight loop
Result: 150000000, expected 150000000
Time: 1712416 EClock ticks (2413 ms)
Test Case 1: Add mem to reg, 2x unrolled
Result: 150000000, expected 150000000
Time: 1256873 EClock ticks (1771 ms)
Test Case 2: Add mem to reg, 4x unrolled
Result: 150000000, expected 150000000
Time: 1068493 EClock ticks (1506 ms)
Test Case 3: Add mem to reg, 8x unrolled
Result: 150000000, expected 150000000
Time: 867167 EClock ticks (1222 ms)
Test Case 4: Add mem to reg, 2x unrolled, prefetched
Result: 150000000, expected 150000000
Time: 1697447 EClock ticks (2392 ms)
Test Case 5: Add mem to reg, 4x unrolled, prefetched
Result: 150000000, expected 150000000
Time: 1790327 EClock ticks (2523 ms)
Test Case 6: Add mem to reg, 8x unrolled, prefetched
Result: 150000000, expected 150000000
Time: 1449095 EClock ticks (2042 ms)
_________________
Doing stupid things for fun... |
| | Status: Offline |
| | michalsc
| |
Re: Integrating Warp3D into my 3D engine
Posted on 20-Feb-2025 19:12:05
| | [ #128 ] |
| |
|
AROS Core Developer
|
Joined: 14-Jun-2005
Posts: 440
From: Germany | | |
|
| @Karlos
Thanks! For reference B1260@50MHz results:
Got Timer, frequency is 709379 Hz
Using 50000000 iterations, step size is 3
Test Case 0: Add mem to reg, tight loop
Result: 150000000, expected 150000000
Time: 1445597 EClock ticks (2037 ms)
Test Case 1: Add mem to reg, 2x unrolled
Result: 150000000, expected 150000000
Time: 1084610 EClock ticks (1528 ms)
Test Case 2: Add mem to reg, 4x unrolled
Result: 150000000, expected 150000000
Time: 903004 EClock ticks (1272 ms)
Test Case 3: Add mem to reg, 8x unrolled
Result: 150000000, expected 150000000
Time: 812672 EClock ticks (1145 ms)
Test Case 4: Add mem to reg, 2x unrolled, prefetched
Result: 150000000, expected 150000000
Time: 1445733 EClock ticks (2038 ms)
Test Case 5: Add mem to reg, 4x unrolled, prefetched
Result: 150000000, expected 150000000
Time: 1263914 EClock ticks (1781 ms)
Test Case 6: Add mem to reg, 8x unrolled, prefetched
Result: 150000000, expected 150000000
Time: 1354551 EClock ticks (1909 ms) |
| | Status: Offline |
| | pixie
 | |
Re: Integrating Warp3D into my 3D engine
Posted on 20-Feb-2025 19:16:55
| | [ #129 ] |
| |
 |
Elite Member
|
Joined: 10-Mar-2003
Posts: 3475
From: Figueira da Foz - Portugal | | |
|
| @Karlos
Quote:
| Results from Amiberry, (i7 mobile) JIT enabled |
Forgive my ignorance, but I thought that Amiberry was for ARM only_________________
Indigo 3D Lounge, my second home.
The Illusion of Choice | Am*ga |
| | Status: Offline |
| | Karlos
| |
Re: Integrating Warp3D into my 3D engine
Posted on 20-Feb-2025 19:25:13
| | [ #130 ] |
| |
|
Elite Member
|
Joined: 24-Aug-2003
Posts: 4960
From: As-sassin-aaate! As-sassin-aaate! Ooh! We forgot the ammunition! | | |
|
| @pixie
Originally, yes. However it's now become the alternative to WinUAE on non-Windows platforms, specifically Linux and MacOS (though only for x64 or ARM silicon).
Until recently I was making do with WinUAE on Wine but it's becoming trickier on my machine to run it without various problems that are nothing to do with WinUAE itself but how I was running it. Last edited by Karlos on 20-Feb-2025 at 07:27 PM.
_________________
Doing stupid things for fun... |
| | Status: Offline |
| | pixie
| |
Re: Integrating Warp3D into my 3D engine
Posted on 20-Feb-2025 19:31:45
| | [ #131 ] |
| |
|
Elite Member
|
Joined: 10-Mar-2003
Posts: 3475
From: Figueira da Foz - Portugal | | |
|
| @Karlos
I see!
Mine for reference
5800X undervolted to 1.025v
Got Timer, frequency is 709379 Hz
Using 50000000 iterations, step size is 3
Test Case 0: Add mem to reg, tight loop
Result: 150000000, expected 150000000
Time: 90307 EClock ticks (127 ms)
Test Case 1: Add mem to reg, 2x unrolled
Result: 150000000, expected 150000000
Time: 59009 EClock ticks (83 ms)
Test Case 2: Add mem to reg, 4x unrolled
Result: 150000000, expected 150000000
Time: 25297 EClock ticks (35 ms)
Test Case 3: Add mem to reg, 8x unrolled
Result: 150000000, expected 150000000
Time: 15331 EClock ticks (21 ms)
Test Case 4: Add mem to reg, 2x unrolled, prefetched
Result: 150000000, expected 150000000
Time: 43449 EClock ticks (61 ms)
Test Case 5: Add mem to reg, 4x unrolled, prefetched
Result: 150000000, expected 150000000
Time: 28934 EClock ticks (40 ms)
Test Case 6: Add mem to reg, 8x unrolled, prefetched
Result: 150000000, expected 150000000
Time: 31528 EClock ticks (44 ms)
Normal 5800X
Got Timer, frequency is 715909 Hz
Using 50000000 iterations, step size is 3
Test Case 0: Add mem to reg, tight loop
Result: 150000000, expected 150000000
Time: 57562 EClock ticks (80 ms)
Test Case 1: Add mem to reg, 2x unrolled
Result: 150000000, expected 150000000
Time: 28465 EClock ticks (39 ms)
Test Case 2: Add mem to reg, 4x unrolled
Result: 150000000, expected 150000000
Time: 14843 EClock ticks (20 ms)
Test Case 3: Add mem to reg, 8x unrolled
Result: 150000000, expected 150000000
Time: 9714 EClock ticks (13 ms)
Test Case 4: Add mem to reg, 2x unrolled, prefetched
Result: 150000000, expected 150000000
Time: 29508 EClock ticks (41 ms)
Test Case 5: Add mem to reg, 4x unrolled, prefetched
Result: 150000000, expected 150000000
Time: 19565 EClock ticks (27 ms)
Test Case 6: Add mem to reg, 8x unrolled, prefetched
Result: 150000000, expected 150000000
Time: 16297 EClock ticks (22 ms)
Last edited by pixie on 20-Feb-2025 at 07:46 PM.
_________________
Indigo 3D Lounge, my second home.
The Illusion of Choice | Am*ga |
| | Status: Offline |
| | Karlos
| |
Re: Integrating Warp3D into my 3D engine
Posted on 20-Feb-2025 20:34:54
| | [ #132 ] |
| |
|
Elite Member
|
Joined: 24-Aug-2003
Posts: 4960
From: As-sassin-aaate! As-sassin-aaate! Ooh! We forgot the ammunition! | | |
|
| @michalsc
The non-prefetched trend is quite interesting, I think.
From a loop of 1 to 2x gives 2037/1528 = 1.333x
2x to 4x gives 1528/1272 = 1.2x
4x to 8x gives 1272/1145 = 1.111x
The end increase relative to the tight loop is 2037/1145 = 1.779x
I think this ties in with the branch basically being for free and the proportion of the remaining code executed being the loop decrement changing from half the code, to one third, to one fifth and eventually one ninth. _________________
Doing stupid things for fun... |
| | Status: Offline |
| | michalsc
| |
Re: Integrating Warp3D into my 3D engine
Posted on 20-Feb-2025 20:51:28
| | [ #133 ] |
| |
|
AROS Core Developer
|
Joined: 14-Jun-2005
Posts: 440
From: Germany | | |
|
| @Karlos
yup :) And here, PiStorm32 with CM4 @2.3 GHz - Cortex A72:
Got Timer, frequency is 709379 Hz
Using 50000000 iterations, step size is 3
Test Case 0: Add mem to reg, tight loop
Result: 150000000, expected 150000000
Time: 398425 EClock ticks (561 ms)
Test Case 1: Add mem to reg, 2x unrolled
Result: 150000000, expected 150000000
Time: 203329 EClock ticks (286 ms)
Test Case 2: Add mem to reg, 4x unrolled
Result: 150000000, expected 150000000
Time: 110589 EClock ticks (155 ms)
Test Case 3: Add mem to reg, 8x unrolled
Result: 150000000, expected 150000000
Time: 62655 EClock ticks (88 ms)
Test Case 4: Add mem to reg, 2x unrolled, prefetched
Result: 150000000, expected 150000000
Time: 195707 EClock ticks (275 ms)
Test Case 5: Add mem to reg, 4x unrolled, prefetched
Result: 150000000, expected 150000000
Time: 105918 EClock ticks (149 ms)
Test Case 6: Add mem to reg, 8x unrolled, prefetched
Result: 150000000, expected 150000000
Time: 63553 EClock ticks (89 ms)
|
| | Status: Offline |
| | Karlos
| |
Re: Integrating Warp3D into my 3D engine
Posted on 20-Feb-2025 21:14:21
| | [ #134 ] |
| |
|
Elite Member
|
Joined: 24-Aug-2003
Posts: 4960
From: As-sassin-aaate! As-sassin-aaate! Ooh! We forgot the ammunition! | | |
|
| @michalsc
At a glance, the prefetch doesn't appear to make any significant difference. This could be because the branching overhead is still much larger than the remaining work.
What are your thoughts? _________________
Doing stupid things for fun... |
| | Status: Offline |
| | michalsc
| |
Re: Integrating Warp3D into my 3D engine
Posted on 20-Feb-2025 21:30:51
| | [ #135 ] |
| |
|
AROS Core Developer
|
Joined: 14-Jun-2005
Posts: 440
From: Germany | | |
|
| @Karlos
Prefetching does not help due to one more reason - the cortex a72 does have only one load/store unit. In this case data prefetching stalls already because of that - the win is eventually only after the last data fetch where it is already hardly visible. Register renaming does not work well either in this case because subsequent adds have the same target register. So I would say this is a great example to show where m68k->ARM translation may suffer.
It may look differently on newer ARM cpus, such as the one in my new board for experiments. There you have two independent load/store units and much more other units working in parallel. |
| | Status: Offline |
| | Karlos
| |
Re: Integrating Warp3D into my 3D engine
Posted on 20-Feb-2025 21:53:37
| | [ #136 ] |
| |
|
Elite Member
|
Joined: 24-Aug-2003
Posts: 4960
From: As-sassin-aaate! As-sassin-aaate! Ooh! We forgot the ammunition! | | |
|
| @michalsc
How bad is it compared to my 3GHz x64 ? In the 8x normal unrolled case, I get 38ms to your 88ms, which is 2.3x faster.
If you factor in the clock speed advantage then it's only 1.77x faster. Last edited by Karlos on 20-Feb-2025 at 09:55 PM.
_________________
Doing stupid things for fun... |
| | Status: Offline |
| | Karlos
| |
Re: Integrating Warp3D into my 3D engine
Posted on 20-Feb-2025 22:37:22
| | [ #137 ] |
| |
|
Elite Member
|
Joined: 24-Aug-2003
Posts: 4960
From: As-sassin-aaate! As-sassin-aaate! Ooh! We forgot the ammunition! | | |
|
| The original premise here was that the load to use stalls would be monumentally bad for performance here, but it doesn't seem like my x64 benchmarks, adjusted for clocks, are drastically better.
So is it the case that Emu68 in the CM4 isn't as badly impacted or is it the case that emulation in UAE just isn't that much better in this example, or can no meaningful conclusions be drawn because the implementations are so different? _________________
Doing stupid things for fun... |
| | Status: Offline |
| | matthey
| |
Re: Integrating Warp3D into my 3D engine
Posted on 21-Feb-2025 1:45:02
| | [ #138 ] |
| |
 |
Elite Member
|
Joined: 14-Mar-2007
Posts: 2758
From: Kansas | | |
|
| michalsc Quote:
Prefetching does not help due to one more reason - the cortex a72 does have only one load/store unit. In this case data prefetching stalls already because of that - the win is eventually only after the last data fetch where it is already hardly visible. Register renaming does not work well either in this case because subsequent adds have the same target register. So I would say this is a great example to show where m68k->ARM translation may suffer.
|
The OoO Cortex-A72 has two AGU pipelines with independent load and store queues but it can only perform one load and one store per cycle. The 68060 has two AGU pipelines and can also only perform one load and one store per cycle. The 68060 uses 4 data cache banks and can only perform a load and a store in the same cycle when the accesses are to different banks. This is cheaper than a dual ported data cache but a dual ported data cache allows 2 loads or a load and a store per cycle which the Qualcomm Kryo design allows in the pic below along with the Cortex-A72 which does not.
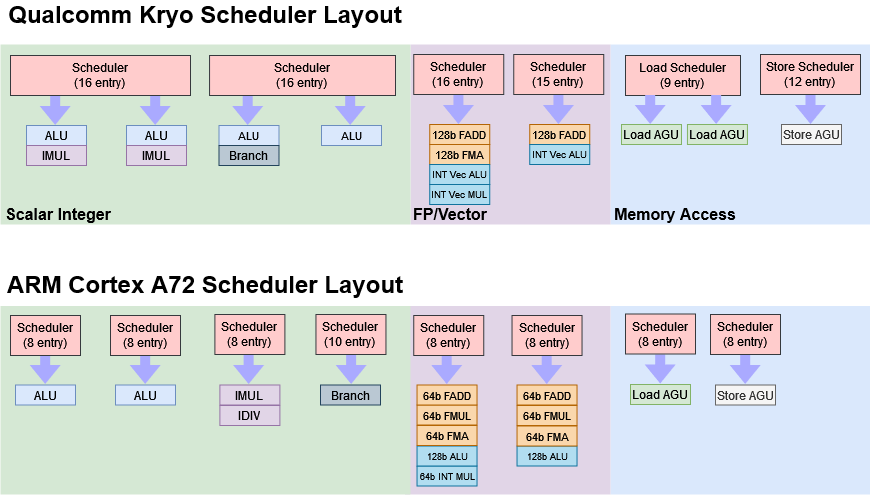
If a dual ported data cache was added to the in-order 68060, it could perform 2x "add.l mem,Rn" per cycle which would double the performance for the unrolled loop right? Normally yes but for this code no. The destination register is d1 for both which is a destination register resource conflict between the superscalar execution pipelines. A load/store design never has a destination resource conflict on a load because the destination register is always overwritten. However, OoO RISC designs usually have deeper pipelines like 15-stages for the Cortex-A72 compared to 8-stages for the Cortex-A53 and 68060 which can result in increased load-to-use delays.
https://sandsoftwaresound.net/arm-cortex-a72-execution-and-load-store/ Quote:
The L1D cache load-to-use latency is 4 cycles when the load hits in the L1D cache. The Level 2 (L2) cache load-to-use latency is 9 cycles when the load hits in the L2 cache.
|
The OoO Cortex-A72 L1 load-to-use latency is actually a cycle longer than the painful in-order Cortex-A53 load-to-use latency but at least the OoO design can rearrange instructions to keep busy. A 2nd load per cycle would increase performance as the loads would get executed sooner so the results would be available sooner. The prefetched benchmark code reduces the load-to-latency the most but the add instructions could only be executed one at a time even with two integer units because of the destination register resource conflict. The Emu68 Cortex-A72 results did see a small performance improvement with the prefetch of 3.8% for the 2x unroll and 3.9% for 4x unroll benchmarks which could be OoO failing to remove all of the load-to-use latency for shorter loops. I did not know how well the OoO Cortex-A72 would be able to remove load-to-use latency but I do expect the Cortex-A53 to easily have the best performance with the prefetch loops, if anyone bothers benchmarking it.
michalsc Quote:
It may look differently on newer ARM cpus, such as the one in my new board for experiments. There you have two independent load/store units and much more other units working in parallel.
|
There is no doubt that newer ARM cores are getting more powerful but they are not the small and low power ARM cores of old.
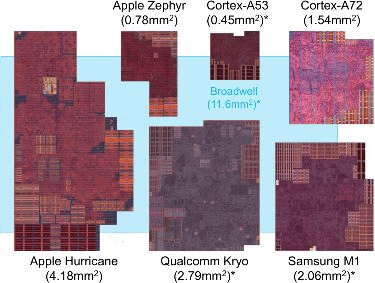
If all these cores are using the same process then...
A Cortex-A72 core is 3.4 times larger than a Cortex-A53 core.
A Kryo core is 6.2 times larger than a Cortex-A53 core.
A Hurricane core is 9.3 times larger than a Cortex-A53 core.
The Cortex-A53 is not a tiny core either.
Year | CPU | transistors
1975 6502 3,500
1979 68000 68,000
1984 68020 190,000
1985 ARM1 25,000
1985 80386 275,000
1986 ARM2 30,000
1987 68030 273,000
1990 68040 1,170,000
1993 Pentium 3,100,000 superscalar in-order 2-way
1994 68060 2,530,000 superscalar in-order 2-way
1994 ARM7 250,000
1995 PentiumPro 5,500,000 OoO uop
2002 ARM11 7,500,000
2008 Nehalem 731,000,000 (1st gen Core i7 with 4 cores) 64 bit OoO uop
2011 Cortex-A7 10,000,000 superscalar in-order 2-way
2012 Cortex-A53 12,500,000 64-bit superscalar in-order 2-way
2012 Cortex-A57 75,000,000 64-bit OoO 3-way big.LITTLE companion of Cortex-A53
Rough ARM transistor counts come from the following link.
https://www.sciencedirect.com/topics/computer-science/stage-pipeline
I thought we were using ARM cores to lower the price of Amiga hardware. Cycle for cycle, it looks like the 68060 design is easily better than the in-order Cortex-A53 design and even holds up well against the much larger, more complex and power hungry Cortex-A72. Emu68 JIT is executing native ARM code from L1 caches like the 68060 is executing native 68k code from L1 in these benchmarks and even with favorable instruction scheduling for the ARM code, a 2 GHz ARM core is far from 40 times better performance than a 68060@50MHz. It seems to be the 68060 that holds up to difficult code where the ARM cores falter. Emu68 is doing its job admirably but ARM cores are overrated despite substantial improvements in performance. We just need newer 68k silicon and 68k silicon is no more expensive than ARM silicon.
Karlos Quote:
The original premise here was that the load to use stalls would be monumentally bad for performance here, but it doesn't seem like my x64 benchmarks, adjusted for clocks, are drastically better.
|
My claim was that load-to-use stalls are very bad for JIT 68k to ARM translation unscheduled code using in-order cores like the Cortex-A53 and that they could still affect OoO RISC cores. The OoO ARM cores are well below x86-64 core performance and we do not have Cortex-A53 results yet. The x86-64 cores even have a handicap as they have to do an endian swap that Emu68 operating in big endian mode does not.
code_68k:
add.l mem,Rn
code_x86-64:
movbe Rm,mem
add Rn,Rm
code_RISC:
load Rm,mem
add Rn,Rm
Maybe it would be as bad as RISC if x86-64 cores had load-to-use stalls. Both the ARM64 and AMD64 code uses twice as many instructions, twice as many registers and is more than twice the code size. New silicon, huge caches and dual ported data caches make pigs fly though. Yea, x86(-64) cores pretty much universally have dual ported data caches since the 80386?
Google: What is the first x86 CPU with a dual ported data cache?
AI Overview Quote:
The first x86 CPU with a dual-ported data cache was the Intel 80386 (i386) processor; specifically, the "DX" variant which had a full 32-bit data bus, enabling simultaneous access to the cache from multiple sources.
|
Not quite that early considering the 80386 did not even have a cache. AI lies!
Karlos Quote:
So is it the case that Emu68 in the CM4 isn't as badly impacted or is it the case that emulation in UAE just isn't that much better in this example, or can no meaningful conclusions be drawn because the implementations are so different?
|
Too many variables to draw conclusions.
Last edited by matthey on 21-Feb-2025 at 01:56 AM.
Last edited by matthey on 21-Feb-2025 at 01:55 AM.
|
| | Status: Offline |
| | Karlos
| |
Re: Integrating Warp3D into my 3D engine
Posted on 21-Feb-2025 9:56:56
| | [ #139 ] |
| |
|
Elite Member
|
Joined: 24-Aug-2003
Posts: 4960
From: As-sassin-aaate! As-sassin-aaate! Ooh! We forgot the ammunition! | | |
|
| @matthey
Let's bring this back into context. We chose this example based on your recommendation for a good worst case example. I don't think there's any technical objection to the claim that this code is pretty pathological for the emulation here. It's also clear that branching is a much better example of something pathological given it's basically free on the 060...
Despite this, the difference in performance between the two 8x unrolled sets of results michalsc has posted here is 1145ms (060/50) versus 88ms (CM4). That's 13x faster. Assuming a linear scale up, then then even a 100MHz 060 is going to be outclassed by a factor of 6.5.
We should do something similar for "average case" code, but to be honest, application benchmarks do this already.
Now, assume I'm an Amiga enthusiast with a functional A1200 I want to max out with the fastest 68K I can get and ideally some RTG action as well.
What's the cost / availability of the fastest extant 060, the accelerator for it to go in, a PCI board and a compatible graphics card?
How does that compare to the PiStorm/CM4 ?
Even if you just considered performance/cost for the base accelerator+CPU alone, how does that compare?
Yes, these are rhetorical questions. We both know that option A is all but off the table for most users.
I don't like being *that guy* but no new 68K silicon is coming. If you want 060 cycle performance, you get an 060 and maybe you can overclock it a touch beyond 100MHz reliably. That's it, and maybe you still have a kidney left after buying it. That's assuming you can even get one at all. Finding a fully working 100MHz capable 060 these days is like finding some hen's teeth in a pile of rocking horse poo. Last edited by Karlos on 21-Feb-2025 at 10:59 AM.
_________________
Doing stupid things for fun... |
| | Status: Offline |
| | Mr-Z
| |
Re: Integrating Warp3D into my 3D engine
Posted on 21-Feb-2025 11:11:44
| | [ #140 ] |
| |
 |
Regular Member
 |
Joined: 24-May-2005
Posts: 196
From: De Keistad, Netherlands | | |
|
| @Karlos
Amen to that, love my PiStorm32+CM4 it has brought a new lease of life to my A1200 and next level performance for it for an affordable price.
And the backwards compatibility is also very good, it runs it all and then some.
Now hopefully well get some more features/drivers going for it like that 3D driver,ethernet etc. to make it even more awesome.
Posted from my A1200+PiStorm with CM4  _________________
Amiga is additive coz it is fun to use |
| | Status: Offline |
| |
|
|
|
[ home ][ about us ][ privacy ]
[ forums ][ classifieds ]
[ links ][ news archive ]
[ link to us ][ user account ]
|
