Your support is needed and is appreciated as Amigaworld.net is primarily dependent upon the support of its users.

|
|
|
|
| Poster | Thread |  cdimauro cdimauro
|  |
Re: Amiga SIMD unit
Posted on 29-Oct-2020 6:11:32
| | [ #201 ] |
| |
 |
Elite Member
 |
Joined: 29-Oct-2012
Posts: 3650
From: Germany | | |
|
| @Hammer Quote:
Hammer wrote:
@cdimauro Quote:
The only point that I wanted to stress is that there's no real AVX-128 mode, which was an artificial invention (optimization path) of GCC for AVX. As well as there's no x86-32 mode, which is an artificial invention (ABI) from Intel for x86-64. |
For 32-bit X86, Intel has IA-32.
X86-32 is vendor less reference to 32-bit X86. The alternative reference to the 32bit X86 code path is the old "i386".
Certain iterations of the IA-32 ISA are sometimes labeled i486, i586, and i686, referring to the instruction supersets offered by the 80486, the P5, and the P6 microarchitectures respectively. |
Sorry, but you're still not right. x86-32 isn't another way to call IA-32/x86: it's an ABI developed by Intel for x86-64 (so, it requires this ISA and runs in 64-bit mode) which limits x86-64's GP registers to 32-bit.
Quote:
Which is NOT an "AVX-128" execution mode. Even AVX-512 allows to use 128, 256, or 512 bits for its vector registers, but there's no AVX-128 or AVX-256 when you use this ISA in that way.
And just clarify it definitely: there's no processor which just supports what you call "AVX-128". Processors just support AVX, and it means that they expose 256-bit register. If you use them or not, it's not relevant from this PoV.
Quote:
Quote:
OK, so you're primarily interested on good gaming performances. That's why you're changing so often your system.
I'm not a gamer, and I don't need to change a system often. I'm more interested to top single-thread performances, but I also don't like to change often a system.
The only exception was the Core i7-4790K, which I've changed after a couple of yeas to a Core i7-6700K only because I had an offer from Intel's internal shop (for employees) which I cannot refuse... |
I don't recall the Amiga desktop computing platform being an embedded platform. |
Me neither. 
Quote:
I just eBay'ed my old items to fund newer items, hence near-zero cost outlays i.e. its opportunistic upgrade.
My income tax usually funds my PC hardware purchases which are applicable to employees working in the relevant IT industry.
Raytracing hardware has benefits for Blender3D besides games. |
Indeed.
Quote:
Quote:
Let's see how efficient it will be.
Anyway, nVidia is using a crappy 8nm process from Samsung, so it has also huge margins of improvement once it'll switch to a much better process, like TSMC's 7nm+ or 5nm (but not soon: the orders are already fulfilled). |
According to AMD's gaming benchmark claims
https://www.techpowerup.com/273934/amd-announces-the-radeon-rx-6000-series-performance-that-restores-competitiveness
RX 6900 XT (300 watts) ~= RTX 3090
RX 6800 XT (300 watts) ~= RTX 3080 (320 watts)
RX 6800 (250 watts) beats RTX 2080 Ti
AMD's Zen team was involved with PC's "RDNA 2 Big NAVI" design, hence very fast 128 MB Infinity Cache was based on Zen's L3 cache.
In general, XBO's 32 MB eSRAM can support 1600x900 framebuffers without delta color compression (DCC).
128 MB Infinity Cache can support 4K framebuffer with DCC. |
All good on paper, but "strangely" AMD missed to publish results using RTX or something (REALLY) equivalent to nVidia's DLSS.
It' the usual AMD launch with some selected benchmark, which means that the product is not really at the same level of the competition.
Quote:
Quote:
I understand your needs as a customer, but if you buy a product then you're also promoting it, approving the decisions of the vendor which will affect the market and future products.
Nothing different from buying AmigaOS4 and supporting Hyperion's decisions, which have split the post-Commodore market, generated wars, and different platforms which is still hurting this nano-niche. |
AmigaOS4 has "the name"(TM), LOL.
From my readings, A1222's price range is similar to Vampire V4. |
Which is... 600£? That's what a user just asked for it's V4 on the forum. |
| | Status: Offline |
| | Hammer
 | |
Re: Amiga SIMD unit
Posted on 29-Oct-2020 13:09:04
| | [ #202 ] |
| |
 |
Elite Member
|
Joined: 9-Mar-2003
Posts: 5315
From: Australia | | |
|
| @cdimauro
Quote:
Sorry, but you're still not right. x86-32 isn't another way to call IA-32/x86: it's an ABI developed by Intel for x86-64 (so, it requires this ISA and runs in 64-bit mode) which limits x86-64's GP registers to 32-bit.
|
That's not correct.
From
https://software.intel.com/content/www/us/en/develop/articles/ia-32-intelr-64-ia-64-architecture-mean.html
IA-32 Architecture refers to systems based on 32-bit processors generally compatible with the Intel Pentium® II processor, (for example, Intel® Pentium® 4 processor or Intel® Xeon® processor), or processors from other manufacturers supporting the same instruction set, running a 32-bit operating system
...
Intel® 64 Architecture refers to systems based on IA-32 architecture processors which have 64-bit architectural extensions, for example, Intel® Core 2 processor family)
----
Intel IA-32 has been retcon i386/i486/i586//i686 into a single 32-bit X86 CPU group.
Intel 64 refers to AMD64 (aka X86-64, X64) compatible instruction set.
Microsoft labels AMD64 as CPU vendor-neutral X64.
Quote:
Which is NOT an "AVX-128" execution mode.
|
That's your argument and my argument wasn't about execution mode.
For performance reasons , GCC curved AVX-128 out of AVX-256, hence AVX-128 is a subset of AVX-256.
AVX-256 ISA and AVX-256 hardware are useless for the majority of XBO/PS4 game ports on the PC, but AVX-2 256-bit is available on baseline XSS/X and PS5. Targeting the lowest common dominator is real.
I'm reading the PS5 CPU optimization guide that warns AVX2-256 can cause the CPU to throttle. Sony's Mark Cerny has warned about this issue during his PS5 reveal presentation, hence the programmer has to weigh up the pros and cons when using AVX-256 and AVX2-256.
AVX-256 and AVX-512 clock speed offset is a consideration on Intel CPUs.
Modern games are sensitive to latency.
Quote:
Even AVX-512 allows to use 128, 256, or 512 bits for its vector registers, but there's no AVX-128 or AVX-256 when you use this ISA in that way.
|
I'm already aware of AVX-512 has support for variable-length SIMD. AVX-512F is a superset of older AVX v1 and AVX v2.
Quote:
And just clarify it definitely: there's no processor which just supports what you call "AVX-128". Processors just support AVX, and it means that they expose 256-bit register. If you use them or not, it's not relevant from this PoV.
|
AVX-128 is relevant from baseline performance POV.
It's pointless to argue AVX-256 support when it gimps CPU performance i.e. AVX-256 stays in the pipeline longer than AVX-128 on Jaguar CPUs i.e. AVX-256 increases instruction retirement latency on Jaguar CPUs.
Jaguar CPUs also have gimped X87. The programmer has to minimize instruction usage that can cause performance pitfalls.
That's the price for making the Jaguar CPU cheap.
Modern games are sensitive to latency.
Quote:
All good on paper, but "strangely" AMD missed to publish results using RTX or something (REALLY) equivalent to nVidia's DLSS.
|
Refer to footnote RRX-571 at https://www.amd.com/en/technologies/rdna-2
Measured by AMD engineering labs 8/17/2020 on an AMD RDNA 2 based graphics card, using the Procedural Geometry sample application from Microsofts DXR SDK, the AMD RDNA 2 based graphics card gets up to 13.8x speedup (471 FPS) using HW based raytracing vs using the Software DXR fallback layer (34 FPS) at the same clocks. Performance may vary. RX-571
Unspecified AMD RDNA 2 based graphics card scored 471 FPS from Procedural Geometry sample application from Microsofts DXR SDK. It's faster than RTX 2080 Ti.
Turing RTX 2080 Ti has its own problem with mesh shading relative to XSX. https://www.youtube.com/watch?v=0sJ_g-aWriQ
Quote:
It' the usual AMD launch with some selected benchmark, which means that the product is not really at the same level of the competition.
|
Gears of War 5 (Unreal Engine 4) is not an AMD-friendly game when compared to Battlefield V or Forza Horizon 4. Gears of War 5 has a built-in benchmark mode.
Battlefield V and Starwars Squadrons have similar results.
My main reason why I bought GTX 980 Ti is Unreal Engine 4's performance and many games are based on Unreal Engine 4.
Shadow of The Tomb Raider is an NVIDIA Gameworks title.
Wolfenstein Young Blood is an NVIDIA Gameworks title. https://www.nvidia.com/en-au/geforce/campaigns/control-wolfenstein-youngblood-bundle/
Call of Duty Modern Warfare is an NVIDIA Gameworks title. https://www.nvidia.com/en-us/geforce/campaigns/call-of-duty-modern-warfare-bundle/
Atm, I would still buy future RTX 3080 Ti, and thanks to AMD for making RTX Ampere cards cheaper. Besides Unreal Engine 4, Blender3D with RT hardware support is important for my needs.
My point, NAVI 21 ASIC is at GA102 level ASIC.
Last edited by Hammer on 29-Oct-2020 at 01:38 PM.
Last edited by Hammer on 29-Oct-2020 at 01:32 PM.
Last edited by Hammer on 29-Oct-2020 at 01:29 PM.
Last edited by Hammer on 29-Oct-2020 at 01:27 PM.
Last edited by Hammer on 29-Oct-2020 at 01:22 PM.
Last edited by Hammer on 29-Oct-2020 at 01:19 PM.
Last edited by Hammer on 29-Oct-2020 at 01:16 PM.
_________________
Ryzen 9 7900X, DDR5-6000 64 GB RAM, GeForce RTX 4080 16 GB
Amiga 1200 (Rev 1D1, KS 3.2, PiStorm32lite/RPi 4B 4GB/Emu68)
Amiga 500 (Rev 6A, KS 3.2, PiStorm/RPi 3a/Emu68) |
| | Status: Offline |
| | matthey
| |
Re: Amiga SIMD unit
Posted on 30-Oct-2020 0:40:07
| | [ #203 ] |
| |
|
Elite Member
|
Joined: 14-Mar-2007
Posts: 2031
From: Kansas | | |
|
| Quote:
cdimauro wrote:
I think that there should be no doubt now that it's convenient and with little impact, at least looking at the numbers. 
|
We mostly looked at register file area which is a small percentage for a high performance core but significant for small cores. It is more difficult to find numbers for power consumption which is likely a low percentage for a high performance core but is mentioned as being important for small cores. Timing may be an issue for very large register files especially if SIMD registers continue to grow in width.
Quote:
The problem is due to the usage of GP registers on SIMD instructions. For example:
PADD.W (A0, D0.L*2),D1,D2
Sharing the data registers with the SIMD unit not only can cause dependency issues, but it complicates the implementation, since you need to add more register ports to allow better parallel access to them.
|
Register renaming eliminates most of the preventable dependency issues. The Apollo core has no problem with this instruction.
Quote:
If we have two different domains (data, SIMD), the cost is reduced, because you can finely tune both independently (since the registers have different sizes).
With a single domain you cannot have ay option: you have to consider the maximum register size for the implementation.
|
Integer registers are unlikely to grow wider than 64 bits but I don't see this as a problem for lightweight SIMD support in the integer units. If more integer SIMD support is needed then add a separate SIMD unit. There is more movement between registers with separate register files and there can be a multi-cycle cost when using a different pipeline with separate units.
Quote:
Modern SIMDs have those conversions: just follow the path...
|
Modern x86-64 SIMD units are fat for the desktop and gaming.
Quote:
Because those registers are independent from the GP ones. The only problem happens when you want to use the regular FPU.
|
Most SIMD operations maintain the same combined data width no matter which registers they are in which makes result forwarding either. The FPU problem was just a poor implementation of MMX for x86.
Quote:
Understood. So, do you want to address only the low-end embedded market?
|
I believe it is important for a 64 bit 68k to be able to go smaller than AArch64 which its superior code density and PC relative addressing should allow if it is not too fat from competitive upscaled features. I have no desire to go as small and handicapped as the original ColdFire target or try to compete with the fattest features in the desktop market.
Last edited by matthey on 30-Oct-2020 at 12:43 AM.
|
| | Status: Online! |
| | Hammer
| |
Re: Amiga SIMD unit
Posted on 31-Oct-2020 3:31:42
| | [ #204 ] |
| |
|
Elite Member
|
Joined: 9-Mar-2003
Posts: 5315
From: Australia | | |
|
| @matthey
Impact of micro-architecture design
https://videocardz.com/newz/sisoftware-release-early-ryzen-7-5800x-and-ryzen-5-5600x-reviews
SiSoftware conclusions on Ryzen 7 5800X:
Executive Summary: Zen3 is ~25-40% faster than Zen2 across all kinds of algorithms. No choice but give it 10/10 overall!
Despite no major architectural changes (except larger 8-core CCX layout and thus unified L3 cache) over Zen2 Zen3 manages to be quite a bit faster across legacy and heavily vectorised SIMD algorithms, naturally also soundly beating the competition even with AVX512 and more cores (e.g. 10-core SKL-X) . Even streaming algorithms (memory-bound) improve over 20%. We certainly did not expect performance to be this good.
----------------
PS; SiSoftware benchmark was one of Intel's favorite benchmarks. Last edited by Hammer on 31-Oct-2020 at 03:33 AM.
_________________
Ryzen 9 7900X, DDR5-6000 64 GB RAM, GeForce RTX 4080 16 GB
Amiga 1200 (Rev 1D1, KS 3.2, PiStorm32lite/RPi 4B 4GB/Emu68)
Amiga 500 (Rev 6A, KS 3.2, PiStorm/RPi 3a/Emu68) |
| | Status: Offline |
| | Hammer
| |
Re: Amiga SIMD unit
Posted on 31-Oct-2020 3:54:46
| | [ #205 ] |
| |
|
Elite Member
|
Joined: 9-Mar-2003
Posts: 5315
From: Australia | | |
|
| @matthey
Quote:
| Modern x86-64 SIMD units are fat for the desktop and gaming. |
Fat SIMD is useful for CPU side BVH raytracing which directs GPU's shading pixels.
PS5 and Xbox Series X can use CPU side BVH raytracing along with GPU's BVH raytracing hardware.
----
https://www.tomshardware.com/news/star-citizen-now-requires-avx-support-killing-off-intel-pentium-platforms
As of early October 2020, Star Citizen (gaming PC) requires AVX.
Starting with the new Alpha 3.11 patch, Star Citizen officially requires AVX instruction support if you want to play the game. This means all CPUs predating Sandy Bridge and AMD's Bulldozer architecture are no longer supported. Even worse, all of Intel's modern Celeron and Pentium CPUs (including the latest generation) can't run the game as they do not support AVX instructions, either
...
The scope and scale of Star Citizen are utterly gigantic, and the game is incredibly CPU-intensive in it's busiest areas. Adding AVX instructions to the engine is probably a good move by CIG to help increase CPU performance
---
For now, there's no word from CIG on creating an SSE compatibility layer for AVX instructions on older CPUs, but the chances of that are probably nill. There's little incentive for CIG to implement a compatibility layer as the game requires high-performance systems in the first place to run the game at playable frame rates (and all of today's CPUs that qualify support AVX instructions). Plus, the player base that runs the game on 10-year-old hardware is very small and will get smaller as time goes on.
Like the game consoles in the year 2020, the baseline PC CPU performance level is also changing.
_________________
Ryzen 9 7900X, DDR5-6000 64 GB RAM, GeForce RTX 4080 16 GB
Amiga 1200 (Rev 1D1, KS 3.2, PiStorm32lite/RPi 4B 4GB/Emu68)
Amiga 500 (Rev 6A, KS 3.2, PiStorm/RPi 3a/Emu68) |
| | Status: Offline |
| | cdimauro
| |
Re: Amiga SIMD unit
Posted on 31-Oct-2020 6:34:54
| | [ #206 ] |
| |
|
Elite Member
|
Joined: 29-Oct-2012
Posts: 3650
From: Germany | | |
|
| @Hammer Quote:
Hammer wrote:
@cdimauro Quote:
Sorry, but you're still not right. x86-32 isn't another way to call IA-32/x86: it's an ABI developed by Intel for x86-64 (so, it requires this ISA and runs in 64-bit mode) which limits x86-64's GP registers to 32-bit. |
That's not correct.
From
https://software.intel.com/content/www/us/en/develop/articles/ia-32-intelr-64-ia-64-architecture-mean.html
IA-32 Architecture refers to systems based on 32-bit processors generally compatible with the Intel Pentium® II processor, (for example, Intel® Pentium® 4 processor or Intel® Xeon® processor), or processors from other manufacturers supporting the same instruction set, running a 32-bit operating system
...
Intel® 64 Architecture refers to systems based on IA-32 architecture processors which have 64-bit architectural extensions, for example, Intel® Core 2 processor family)
----
Intel IA-32 has been retcon i386/i486/i586//i686 into a single 32-bit X86 CPU group.
Intel 64 refers to AMD64 (aka X86-64, X64) compatible instruction set.
Microsoft labels AMD64 as CPU vendor-neutral X64. |
As you can see in the above link that you provided, there was no x86-32 reported.
However I had a lapsus before: what I was wrongly calling x86-32 should have been x32 instead: https://en.wikipedia.org/wiki/X32_ABI
This was the ABI which I was talking about before, and it was just an artificial invention of Intel which reused x64 in a castrated way to gain some performances with 32-bit code (on a 64-bit environment / execution mode).
Quote:
Quote:
| Which is NOT an "AVX-128" execution mode. |
That's your argument and my argument wasn't about execution mode.
For performance reasons , GCC curved AVX-128 out of AVX-256, hence AVX-128 is a subset of AVX-256.
AVX-256 ISA and AVX-256 hardware are useless for the majority of XBO/PS4 game ports on the PC, but AVX-2 256-bit is available on baseline XSS/X and PS5. Targeting the lowest common dominator is real.
I'm reading the PS5 CPU optimization guide that warns AVX2-256 can cause the CPU to throttle. Sony's Mark Cerny has warned about this issue during his PS5 reveal presentation, hence the programmer has to weigh up the pros and cons when using AVX-256 and AVX2-256.
AVX-256 and AVX-512 clock speed offset is a consideration on Intel CPUs. |
The point is that there's no AVX-128 neither AVX-256 ISAs on the IA-32/x86-64 specifications. You can download Intel's architecture manual, go to "CHAPTER 14 - PROGRAMMING WITH AVX, FMA AND AVX2", and check on your own.
AVX-128 and AVX-256 are just artificial inventions (like x32: see above) to say: "I'm only using 128-bit or 256-bit of the vector registers (whatever is their real maximum size)".
But AVX is, per se, a 256-bit SIMD extension. From the architecture manual:
"Intel® Advanced Vector Extensions (Intel® AVX) introduces 256-bit vector processing capability
[...]
Intel AVX introduces the following architectural enhancements:
Support for 256-bit wide vectors with the YMM vector register set.
256-bit floating-point instruction set enhancement with up to 2X performance gain relative to 128-bit
Streaming SIMD extensions.
Enhancement of legacy 128-bit SIMD instruction extensions to support three-operand syntax and to simplify
compiler vectorization of high-level language expressions.
VEX prefix-encoded instruction syntax support for generalized three-operand syntax to improve instruction
programming flexibility and efficient encoding of new instruction extensions.
Most VEX-encoded 128-bit and 256-bit AVX instructions (with both load and computational operation
semantics) are not restricted to 16-byte or 32-byte memory alignment.
Support flexible deployment of 256-bit AVX code, 128-bit AVX code, legacy 128-bit code and scalar code.
With the exception of SIMD instructions operating on MMX registers, almost all legacy 128-bit SIMD instructions
have AVX equivalents that support three operand syntax. 256-bit AVX instructions employ three-operand syntax
and some with 4-operand syntax.
[...]
Intel AVX introduces support for 256-bit wide SIMD registers (YMM0-YMM7 in operating modes that are 32-bit or
less, YMM0-YMM15 in 64-bit mode). The lower 128-bits of the YMM registers are aliased to the respective 128-bit
XMM registers.
Legacy SSE instructions (i.e. SIMD instructions operating on XMM state but not using the VEX prefix, also referred
to non-VEX encoded SIMD instructions) will not access the upper bits beyond bit 128 of the YMM registers. AVX
instructions with a VEX prefix and vector length of 128-bits zeroes the upper bits (above bit 128) of the YMM
register."
Note the last part: even when using 128-bit vector lengths, you're still using the full 256-bit registers size (upper bits are cleared).
Quote:
| Modern games are sensitive to latency. |
As I said before, I have nothing against it.
Quote:
Quote:
| Even AVX-512 allows to use 128, 256, or 512 bits for its vector registers, but there's no AVX-128 or AVX-256 when you use this ISA in that way. |
I'm already aware of AVX-512 has support for variable-length SIMD. AVX-512F is a superset of older AVX v1 and AVX v2. |
AVX-512 isn't a variable-length SIMD: the registers sizes are always 512-bit, but the instructions can select 128, 256, or 512 of them. So, only a portion of the 512-register can be used when selecting 128 or 256-bit, and the upper bits will always be zeroed (see above).
Quote:
Quote:
| And just clarify it definitely: there's no processor which just supports what you call "AVX-128". Processors just support AVX, and it means that they expose 256-bit register. If you use them or not, it's not relevant from this PoV. |
AVX-128 is relevant from baseline performance POV.
It's pointless to argue AVX-256 support when it gimps CPU performance i.e. AVX-256 stays in the pipeline longer than AVX-128 on Jaguar CPUs i.e. AVX-256 increases instruction retirement latency on Jaguar CPUs. |
Nothing to say on a micro-architecture / optimization level, but the point is that there's no AVX-128 neither an AVX-256 ISA.
You, as a developer or compiler, are deciding to use 128 or 256-bits. That's fine, but don't call it "AVX-128" or "AVX-256", since there's nothing like that: no execution mode neither an ISA with those names.
Using AVX-128 or AVX-256 just causes confusion, because are "local labels" that someone decided to use on its own despite the real name & ISA.
Quote:
Jaguar CPUs also have gimped X87. The programmer has to minimize instruction usage that can cause performance pitfalls.
That's the price for making the Jaguar CPU cheap.
Modern games are sensitive to latency. |
And, again, I've said nothing about that.
Quote:
Quote:
| All good on paper, but "strangely" AMD missed to publish results using RTX or something (REALLY) equivalent to nVidia's DLSS. |
Refer to footnote RRX-571 at https://www.amd.com/en/technologies/rdna-2
Measured by AMD engineering labs 8/17/2020 on an AMD RDNA 2 based graphics card, using the Procedural Geometry sample application from Microsofts DXR SDK, the AMD RDNA 2 based graphics card gets up to 13.8x speedup (471 FPS) using HW based raytracing vs using the Software DXR fallback layer (34 FPS) at the same clocks. Performance may vary. RX-571
Unspecified AMD RDNA 2 based graphics card scored 471 FPS from Procedural Geometry sample application from Microsofts DXR SDK. It's faster than RTX 2080 Ti.
Turing RTX 2080 Ti has its own problem with mesh shading relative to XSX. https://www.youtube.com/watch?v=0sJ_g-aWriQ
Quote:
| [quote]It' the usual AMD launch with some selected benchmark, which means that the product is not really at the same level of the competition. |
Gears of War 5 (Unreal Engine 4) is not an AMD-friendly game when compared to Battlefield V or Forza Horizon 4. Gears of War 5 has a built-in benchmark mode.
Battlefield V and Starwars Squadrons have similar results.
My main reason why I bought GTX 980 Ti is Unreal Engine 4's performance and many games are based on Unreal Engine 4.
Shadow of The Tomb Raider is an NVIDIA Gameworks title.
Wolfenstein Young Blood is an NVIDIA Gameworks title. https://www.nvidia.com/en-au/geforce/campaigns/control-wolfenstein-youngblood-bundle/
Call of Duty Modern Warfare is an NVIDIA Gameworks title. https://www.nvidia.com/en-us/geforce/campaigns/call-of-duty-modern-warfare-bundle/
Atm, I would still buy future RTX 3080 Ti, and thanks to AMD for making RTX Ampere cards cheaper. Besides Unreal Engine 4, Blender3D with RT hardware support is important for my needs.
My point, NAVI 21 ASIC is at GA102 level ASIC. |
And my point was about RTX and DLSS-like performance, which aren't good. In fact:
https://wccftech.com/amd-radeon-rx-6000-rdna-2-big-navi-graphics-cards-ray-tracing-performance-detailed/
https://videocardz.com/newz/amd-ray-accelerator-appear-to-be-slower-than-nvidia-rt-core-in-this-dxr-ray-tracing-benchmark
Someone made the maths using the same results that you reported from AMD's site, and found some interesting data about RTX (at least), which doesn't look good.
AMD used synthetic benchmarks, and I really don't like them: I prefer real-world applications / games.
But "strangely" AMD didn't published any result with games which are using RTX. And the synthetic benchmarks can be the reason why.
Same for the DLSS: there was no benchmark with games using DLSS for nVidia, and the new technology from AMD which is supposed to do the same. The last DLSS version gives excellent results and helps A LOT on the performances. But no comparison from AMD: guess why...
@Hammer Quote:
Hammer wrote:
@matthey
Impact of micro-architecture design
https://videocardz.com/newz/sisoftware-release-early-ryzen-7-5800x-and-ryzen-5-5600x-reviews
SiSoftware conclusions on Ryzen 7 5800X:
Executive Summary: Zen3 is ~25-40% faster than Zen2 across all kinds of algorithms. No choice but give it 10/10 overall!
Despite no major architectural changes (except larger 8-core CCX layout and thus unified L3 cache) over Zen2 Zen3 manages to be quite a bit faster across legacy and heavily vectorised SIMD algorithms, naturally also soundly beating the competition even with AVX512 and more cores (e.g. 10-core SKL-X) . Even streaming algorithms (memory-bound) improve over 20%. We certainly did not expect performance to be this good.
----------------
PS; SiSoftware benchmark was one of Intel's favorite benchmarks. |
I don't see those claims looking at the aggregated scores. On the contrary, Skylake-X has a clear edge against Zen3: look ad the top-right chart. |
| | Status: Offline |
| | cdimauro
| |
Re: Amiga SIMD unit
Posted on 31-Oct-2020 7:09:04
| | [ #207 ] |
| |
|
Elite Member
|
Joined: 29-Oct-2012
Posts: 3650
From: Germany | | |
|
| @matthey Quote:
matthey wrote:
Quote:
cdimauro wrote:
I think that there should be no doubt now that it's convenient and with little impact, at least looking at the numbers. |
We mostly looked at register file area which is a small percentage for a high performance core but significant for small cores. It is more difficult to find numbers for power consumption which is likely a low percentage for a high performance core but is mentioned as being important for small cores. |
OK, but the register file is taking a very small portion of the core even on small cores like the Atom ones: only 2% "removing" the SMT. And we're talking about a processor which has 16 x 64-bit GP registers + 16 x 128-bit SIMD registers and 8 x 80-bit FPU registers.
Do you want go below 2% of the core size with your processor? For saving what?
Quote:
| Timing may be an issue for very large register files especially if SIMD registers continue to grow in width. |
That's granted: all CPU vendors proposed "fat" SIMD ISAs and/or microarchitectures.
"This is the way..." (cit.)
Quote:
Quote:
The problem is due to the usage of GP registers on SIMD instructions. For example:
PADD.W (A0, D0.L*2),D1,D2
Sharing the data registers with the SIMD unit not only can cause dependency issues, but it complicates the implementation, since you need to add more register ports to allow better parallel access to them. |
Register renaming eliminates most of the preventable dependency issues. |
And also increases the register file size... 
Quote:
| The Apollo core has no problem with this instruction. |
Because it's very likely that they increased the number of ports in the register file to accomodate it.
And the core offers 16 x 64-bit address registers + 32 x 64-bit data/FPU/SIMD registers (the register file is the same), multiplied by two since they have implemented an Hyperthreading-like technology (two hardware threads running in parallel).
Do you consider the Apollo core "too fat" for your goal? It's already doing well at the performance level (putting aside the weird ISA decisions).
Quote:
Quote:
If we have two different domains (data, SIMD), the cost is reduced, because you can finely tune both independently (since the registers have different sizes).
With a single domain you cannot have ay option: you have to consider the maximum register size for the implementation. |
Integer registers are unlikely to grow wider than 64 bits but I don't see this as a problem for lightweight SIMD support in the integer units. If more integer SIMD support is needed then add a separate SIMD unit. |
But the point is that if you want to increase the SIMD register sizes then you're forced to do the same with the data registers, if you use a common register file for both.
A 128-bit SIMD unit is very common, and considered a "minimum" requirement nowadays (with 256-bit sizes quickly becoming the mainstream: see AVX and the link provided by Hammer. Which makes sense, because Sony's and Microsoft's console are using AVX from long time now).
Do you like to have 128-bit data registers, and wasting their space when used only as data registers?
Quote:
| There is more movement between registers with separate register files and there can be a multi-cycle cost when using a different pipeline with separate units. |
That's normal, but usually it's around 2-3 more cycle (increased latency) in those case.
Still way better than PowerPCs, which had to store the result in memory and load it again.
Quote:
Quote:
| Modern SIMDs have those conversions: just follow the path... |
Modern x86-64 SIMD units are fat for the desktop and gaming. |
Performing very well, nonetheless.
And, as I said before, it's mostly due to the legacy burden. An ISA with a clean design can do the same things without being so fat.
Just to give an example, on my ISA the ADD single SIMD instruction maps all equivalent ADDs from all IA-32/x86-64 SIMDs:
VADDPD, VADDPS, VADDSD, VADDSS, VPADDB, VPADDW, VPADDD, VPADDQ, ADDPD, ADDPS, ADDSD, ADDSS, PADDB, PADDW, PADDD, PADDQ
That's because the ISA is fully orthogonal.
Quote:
Quote:
Because those registers are independent from the GP ones. The only problem happens when you want to use the regular FPU.
|
Most SIMD operations maintain the same combined data width no matter which registers they are in which makes result forwarding either. The FPU problem was just a poor implementation of MMX for x86. |
Yes, that's only because they reused the same FPU's register file.
It was much better with the SSE, which had its own set of registers. 
Quote:
Quote:
| Understood. So, do you want to address only the low-end embedded market? |
I believe it is important for a 64 bit 68k to be able to go smaller than AArch64 which its superior code density and PC relative addressing should allow if it is not too fat from competitive upscaled features. I have no desire to go as small and handicapped as the original ColdFire target or try to compete with the fattest features in the desktop market. |
Fair enough. But from what I see the risk is to have a too much castrated and/or embedded-oriented ISA. So, not a more general purpose one.
And once you take some decisions, implement them, and go to the market, then you'll bound to them. They become your legacy burden, and they can cripple future improvements. |
| | Status: Offline |
| | Hammer
| |
Re: Amiga SIMD unit
Posted on 31-Oct-2020 14:42:39
| | [ #208 ] |
| |
|
Elite Member
|
Joined: 9-Mar-2003
Posts: 5315
From: Australia | | |
|
| @cdimauro
Quote:
As you can see in the above link that you provided, there was no x86-32 reported.
However I had a lapsus before: what I was wrongly calling x86-32 should have been x32 instead: https://en.wikipedia.org/wiki/X32_ABI
This was the ABI which I was talking about before, and it was just an artificial invention of Intel which reused x64 in a castrated way to gain some performances with 32-bit code (on a 64-bit environment / execution mode).
|
FYI, IA-32 label was first defined during IA-64's Itanium.
My X86-32 label is for vendor neutrality to be consistent with X86-64.
If Intel doesn't accept AMD64, then I wouldn't accept IA-32.
Also, Microsoft defines 32bit X86 as x86 e.g. Windows 10 x86. Like MS, I wouldn't be part of Intel's hypocrisy.
Quote:
The point is that there's no AVX-128 neither AVX-256 ISAs on the IA-32/x86-64 specifications. You can download Intel's architecture manual, go to "CHAPTER 14 - PROGRAMMING WITH AVX, FMA AND AVX2", and check on your own.
AVX-128 and AVX-256 are just artificial inventions (like x32: see above) to say: "I'm only using 128-bit or 256-bit of the vector registers (whatever is their real maximum size)".
But AVX is, per se, a 256-bit SIMD extension. From the architecture manual:
"Intel® Advanced Vector Extensions (Intel® AVX) introduces 256-bit vector processing capability
[...]
Intel AVX introduces the following architectural enhancements:
Support for 256-bit wide vectors with the YMM vector register set.
256-bit floating-point instruction set enhancement with up to 2X performance gain relative to 128-bit
Streaming SIMD extensions.
Enhancement of legacy 128-bit SIMD instruction extensions to support three-operand syntax and to simplify
compiler vectorization of high-level language expressions.
VEX prefix-encoded instruction syntax support for generalized three-operand syntax to improve instruction
programming flexibility and efficient encoding of new instruction extensions.
Most VEX-encoded 128-bit and 256-bit AVX instructions (with both load and computational operation
semantics) are not restricted to 16-byte or 32-byte memory alignment.
Support flexible deployment of 256-bit AVX code, 128-bit AVX code, legacy 128-bit code and scalar code.
With the exception of SIMD instructions operating on MMX registers, almost all legacy 128-bit SIMD instructions
have AVX equivalents that support three operand syntax. 256-bit AVX instructions employ three-operand syntax
and some with 4-operand syntax.
[...]
Intel AVX introduces support for 256-bit wide SIMD registers (YMM0-YMM7 in operating modes that are 32-bit or
less, YMM0-YMM15 in 64-bit mode). The lower 128-bits of the YMM registers are aliased to the respective 128-bit
XMM registers.
Legacy SSE instructions (i.e. SIMD instructions operating on XMM state but not using the VEX prefix, also referred
to non-VEX encoded SIMD instructions) will not access the upper bits beyond bit 128 of the YMM registers. AVX
instructions with a VEX prefix and vector length of 128-bits zeroes the upper bits (above bit 128) of the YMM
register."
Note the last part: even when using 128-bit vector lengths, you're still using the full 256-bit registers size (upper bits are cleared).
|
FYI, Intel has the full AVX-256 hardware support.
From https://software.intel.com/content/www/us/en/develop/articles/introduction-to-intel-advanced-vector-extensions.html

Diagram from Intel. Notice "AVX-128" LOL
Quote:
From https://videocardz.com/newz/alleged-amd-radeon-rx-6800-time-spy-and-tomb-raider-with-dxr-performance-leaks-out
Shadow of the Tomb Raider (with Ray Tracing enabled)
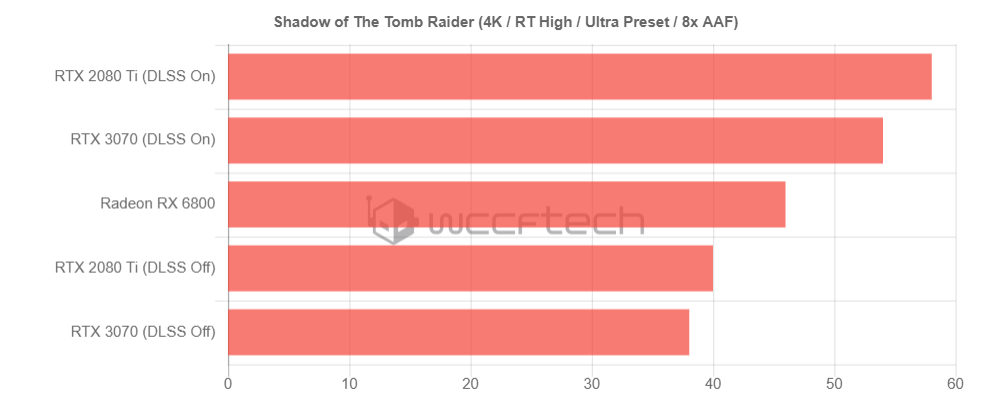
Without DLSS, RX 6800 (brute force) beaten both RTX 2080 Ti and RTX 3070.
https://videocardz.com/newz/amd-is-working-on-ai-powered-supersampling-nvidia-dlss-alternative
For AI super sampling, AMD is working on a DLSS alternative.
DLSS is similar to temporal pixel reconstruction with AI database and AI decision process.
For Intel GPUS, 5X over 96 IEU's 2 TFLOPS results which are like Vega's raster results vs TFLOPS ratio wouldn't catch RDNA 2.Last edited by Hammer on 31-Oct-2020 at 02:50 PM.
Last edited by Hammer on 31-Oct-2020 at 02:44 PM.
_________________
Ryzen 9 7900X, DDR5-6000 64 GB RAM, GeForce RTX 4080 16 GB
Amiga 1200 (Rev 1D1, KS 3.2, PiStorm32lite/RPi 4B 4GB/Emu68)
Amiga 500 (Rev 6A, KS 3.2, PiStorm/RPi 3a/Emu68) |
| | Status: Offline |
| | Hammer
| |
Re: Amiga SIMD unit
Posted on 31-Oct-2020 14:56:04
| | [ #209 ] |
| |
|
Elite Member
|
Joined: 9-Mar-2003
Posts: 5315
From: Australia | | |
|
| @cdimauro
Quote:
| I don't see those claims looking at the aggregated scores. On the contrary, Skylake-X has a clear edge against Zen3: look ad the top-right chart. |
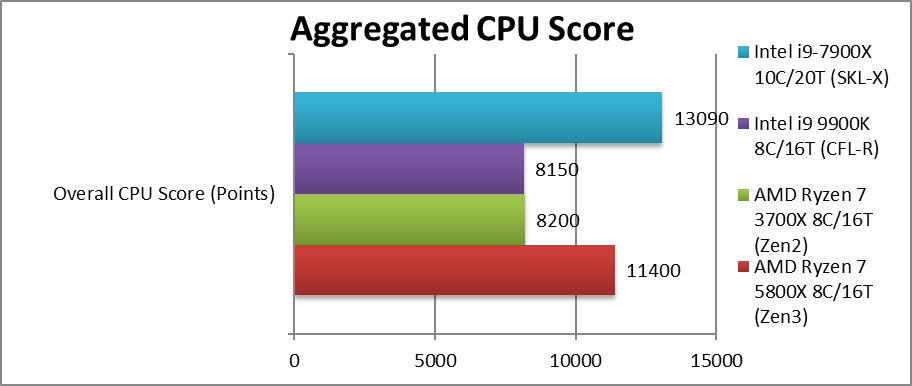
Skylake i9-7900X has 10 cores
Ryzen 7 5800X has 8 cores.
AM4 socket scales to 16 cores btw.
_________________
Ryzen 9 7900X, DDR5-6000 64 GB RAM, GeForce RTX 4080 16 GB
Amiga 1200 (Rev 1D1, KS 3.2, PiStorm32lite/RPi 4B 4GB/Emu68)
Amiga 500 (Rev 6A, KS 3.2, PiStorm/RPi 3a/Emu68) |
| | Status: Offline |
| | cdimauro
| |
Re: Amiga SIMD unit
Posted on 31-Oct-2020 22:38:28
| | [ #210 ] |
| |
|
Elite Member
|
Joined: 29-Oct-2012
Posts: 3650
From: Germany | | |
|
| @Hammer Quote:
Hammer wrote:
@cdimauro Quote:
As you can see in the above link that you provided, there was no x86-32 reported.
However I had a lapsus before: what I was wrongly calling x86-32 should have been x32 instead: https://en.wikipedia.org/wiki/X32_ABI
This was the ABI which I was talking about before, and it was just an artificial invention of Intel which reused x64 in a castrated way to gain some performances with 32-bit code (on a 64-bit environment / execution mode). |
FYI, IA-32 label was first defined during IA-64's Itanium. |
Indeed.
Quote:
| My X86-32 label is for vendor neutrality to be consistent with X86-64. |
But it's not used. x86 and x64 are the most commonly used terms for IA-32 and x86-64.
Quote:
| If Intel doesn't accept AMD64, then I wouldn't accept IA-32. |
I don't see any rational reasons for this position.
x86-64 was the original name of AMD's 64-bit extension to IA-32/x86.
After that, I don't know who and when, x86-64 was also called AMD64, to define AMD's x86-64 version of the ISA.
Similarly, Intel first used EM64T for its x86-64 version of the ISA, and finally used Intel64 in the recent years.
So, both AMD64 and EM64T/Intel64 are legit names for the respective ISAs (which, BTW, were different when the first x86-64 implementations from both vendors arrived to the market).
Quote:
| Also, Microsoft defines 32bit X86 as x86 e.g. Windows 10 x86. Like MS, I wouldn't be part of Intel's hypocrisy. |
See above about the supposed "hypocrisy", which doesn't make sense for me.
For the rest if you download and execute Microsoft's MediaCreator tool for downloading the Windows ISO you'll see that x86 and x64 are used for selecting the 32 or 64-bit version of the o.s., and that's simply because they are the most commonly used terms. Whatever AMD and Intel decide to call them...
Quote:
Quote:
The point is that there's no AVX-128 neither AVX-256 ISAs on the IA-32/x86-64 specifications. You can download Intel's architecture manual, go to "CHAPTER 14 - PROGRAMMING WITH AVX, FMA AND AVX2", and check on your own.
AVX-128 and AVX-256 are just artificial inventions (like x32: see above) to say: "I'm only using 128-bit or 256-bit of the vector registers (whatever is their real maximum size)".
But AVX is, per se, a 256-bit SIMD extension. From the architecture manual:
"Intel® Advanced Vector Extensions (Intel® AVX) introduces 256-bit vector processing capability
[...]
Intel AVX introduces the following architectural enhancements:
Support for 256-bit wide vectors with the YMM vector register set.
256-bit floating-point instruction set enhancement with up to 2X performance gain relative to 128-bit
Streaming SIMD extensions.
Enhancement of legacy 128-bit SIMD instruction extensions to support three-operand syntax and to simplify
compiler vectorization of high-level language expressions.
VEX prefix-encoded instruction syntax support for generalized three-operand syntax to improve instruction
programming flexibility and efficient encoding of new instruction extensions.
Most VEX-encoded 128-bit and 256-bit AVX instructions (with both load and computational operation
semantics) are not restricted to 16-byte or 32-byte memory alignment.
Support flexible deployment of 256-bit AVX code, 128-bit AVX code, legacy 128-bit code and scalar code.
With the exception of SIMD instructions operating on MMX registers, almost all legacy 128-bit SIMD instructions
have AVX equivalents that support three operand syntax. 256-bit AVX instructions employ three-operand syntax
and some with 4-operand syntax.
[...]
Intel AVX introduces support for 256-bit wide SIMD registers (YMM0-YMM7 in operating modes that are 32-bit or
less, YMM0-YMM15 in 64-bit mode). The lower 128-bits of the YMM registers are aliased to the respective 128-bit
XMM registers.
Legacy SSE instructions (i.e. SIMD instructions operating on XMM state but not using the VEX prefix, also referred
to non-VEX encoded SIMD instructions) will not access the upper bits beyond bit 128 of the YMM registers. AVX
instructions with a VEX prefix and vector length of 128-bits zeroes the upper bits (above bit 128) of the YMM
register."
Note the last part: even when using 128-bit vector lengths, you're still using the full 256-bit registers size (upper bits are cleared). |
FYI, Intel has the full AVX-256 hardware support. |
FYI, any x86/x64 CPU vendor which supports AVX/-2 has the full AVX-256 hardware support. Included AMD's Jaguar.
Quote:
This was solely for selecting the data type, as you can see from the picture's description.
You'll find similar names in the performance monitoring registers, for the same reasons (to measure which data type was used by the instructions).
But you'll NOT find any AVX-128 or AVX-256 when talking about the ISA, as also your link clearly shows (the only occurrence of the AVX-128 term is in the data type selection).
Quote:
But nVidia has the DLSS which allows to put the RX6800 in the dust.
Quote:
https://videocardz.com/newz/amd-is-working-on-ai-powered-supersampling-nvidia-dlss-alternative
For AI super sampling, AMD is working on a DLSS alternative. |
With very poor results, which are lightyears away from nVidia's DLSS. If you take a look at the comparisons (you can find some on Guru3D, AFAIR) you'll see that the current AMD offer is simply ridiculous.
Quote:
| DLSS is similar to temporal pixel reconstruction with AI database and AI decision process. |
Yes.
Quote:
| For Intel GPUS, 5X over 96 IEU's 2 TFLOPS results which are like Vega's raster results vs TFLOPS ratio wouldn't catch RDNA 2. |
It could be a good starting point for Intel (), but let's see when the final product arrives.
@Hammer Quote:
Hammer wrote:
@cdimauro Quote:
| I don't see those claims looking at the aggregated scores. On the contrary, Skylake-X has a clear edge against Zen3: look ad the top-right chart. |
Skylake i9-7900X has 10 cores
Ryzen 7 5800X has 8 cores.
AM4 socket scales to 16 cores btw. |
Skylake i9-7900X has also 800Mhz less than the last Intel's products, since it's using the very first 14nm process.
BTW: https://wccftech.com/intel-8-core-16-thread-rocket-lake-cpu-benchmarks-leak-msi-z590-motherboard/
Rocket Lake... rocks. And the engineering sample has 900Mhz less than the last Intel's products. |
| | Status: Offline |
| | matthey
| |
Re: Amiga SIMD unit
Posted on 2-Nov-2020 0:40:26
| | [ #211 ] |
| |
|
Elite Member
|
Joined: 14-Mar-2007
Posts: 2031
From: Kansas | | |
|
| Quote:
cdimauro wrote:
OK, but the register file is taking a very small portion of the core even on small cores like the Atom ones: only 2% "removing" the SMT. And we're talking about a processor which has 16 x 64-bit GP registers + 16 x 128-bit SIMD registers and 8 x 80-bit FPU registers.
Do you want go below 2% of the core size with your processor? For saving what?
|
The Atom is *not* small. The "small" Silverthorne core has 47.2 million transistors for one in order core. It should have had at least 4 cores with that transistor budget. The 68060 used 2.5 million transistors.
47.2/2.5 = 18 - 68060 cores for the transistor budget of one "small" Silverthorne core
The 68060 needs some modern features like bigger caches, the equivalent of Safe Instruction Recognition (SIR) supporting OoO commits, SIMD/vector support, a link stack, etc. but I can't imagine using 47.2 million transistors for only one core.
Quote:
And also increases the register file size...
|
Cores with more registers usually have more rename registers. If register renaming doubles the cost and 2 way SMT doubles it again then this is 4 times the cost.
Quote:
Because it's very likely that they increased the number of ports in the register file to accomodate it.
|
I'm not so sure adding more register ports to the Apollo core for AMMX was necessary.
Quote:
And the core offers 16 x 64-bit address registers + 32 x 64-bit data/FPU/SIMD registers (the register file is the same), multiplied by two since they have implemented an Hyperthreading-like technology (two hardware threads running in parallel).
Do you consider the Apollo core "too fat" for your goal? It's already doing well at the performance level (putting aside the weird ISA decisions).
|
I think the Apollo core unnecessarily fattens up the cores with little gain. Performance is good for a low clocked in order core but I doubt much software is effectively using the extra banked registers. I think a compiler would have trouble using the additional banked registers and this would significantly increase the difficulty of compiler support.
Quote:
But the point is that if you want to increase the SIMD register sizes then you're forced to do the same with the data registers, if you use a common register file for both.
|
The data registers would not be increased beyond 64 bit width and lightweight SIMD support would be available for integer instructions. Wider SIMD integer support could be added to the fp SIMD unit too as it appears to be very cheap. It is possible to use register pairs as the 88110 CPU used 2 32 bit registers to do 64 bit SIMD (Apollo core could use 2 64 bit wide registers to do 128 bit SIMD operations). Mitch Alsup said not making the 88k 64 bit from the start was the biggest design mistake and this would have allowed 64 bit SIMD without using register pairs.
Quote:
A 128-bit SIMD unit is very common, and considered a "minimum" requirement nowadays (with 256-bit sizes quickly becoming the mainstream: see AVX and the link provided by Hammer. Which makes sense, because Sony's and Microsoft's console are using AVX from long time now).
Do you like to have 128-bit data registers, and wasting their space when used only as data registers?
|
Hammer's Intel documentation diagram also shows integer datatype support dropped for wider 256 bit AVX.
Quote:
And, as I said before, it's mostly due to the legacy burden. An ISA with a clean design can do the same things without being so fat.
Just to give an example, on my ISA the ADD single SIMD instruction maps all equivalent ADDs from all IA-32/x86-64 SIMDs:
VADDPD, VADDPS, VADDSD, VADDSS, VPADDB, VPADDW, VPADDD, VPADDQ, ADDPD, ADDPS, ADDSD, ADDSS, PADDB, PADDW, PADDD, PADDQ
That's because the ISA is fully orthogonal.
|
x86-64 has all the performance enhancements and all the baggage. It would be nice to transition to a cleaner design but I don't think I would base it on x86-64.
Quote:
Fair enough. But from what I see the risk is to have a too much castrated and/or embedded-oriented ISA. So, not a more general purpose one.
|
In my opinion, the bigger problem has been core designs which have been cheapened too much for embedded. Some of this is due to ISAs which were too robust and didn't allow small enough designs to be competitive in PPA and price.
|
| | Status: Online! |
| | cdimauro
| |
Re: Amiga SIMD unit
Posted on 2-Nov-2020 8:43:52
| | [ #212 ] |
| |
|
Elite Member
|
Joined: 29-Oct-2012
Posts: 3650
From: Germany | | |
|
| @matthey Quote:
matthey wrote:
Quote:
cdimauro wrote:
OK, but the register file is taking a very small portion of the core even on small cores like the Atom ones: only 2% "removing" the SMT. And we're talking about a processor which has 16 x 64-bit GP registers + 16 x 128-bit SIMD registers and 8 x 80-bit FPU registers.
Do you want go below 2% of the core size with your processor? For saving what? |
The Atom is *not* small. The "small" Silverthorne core has 47.2 million transistors for one in order core. It should have had at least 4 cores with that transistor budget. |
Well, the core itself is taking only 13.8 million transistors, and you have a lot of stuff there (64 bits, 128-bit SIMD unit, Hyperthreading, 32KB ICache, 24KB DCache, etc.).
Quote:
The 68060 used 2.5 million transistors.
47.2/2.5 = 18 - 68060 cores for the transistor budget of one "small" Silverthorne core
The 68060 needs some modern features like bigger caches, the equivalent of Safe Instruction Recognition (SIR) supporting OoO commits, SIMD/vector support, a link stack, etc. but I can't imagine using 47.2 million transistors for only one core. |
That's the point: it's a lot of modern stuff which is missing from the 68060.
68060 was also small because Motorola cut a lot of stuff from its ISA, already starting from the 68030. One last example: http://eab.abime.net/showpost.php?p=1438453&postcount=21
Quote:
Quote:
| And also increases the register file size... |
Cores with more registers usually have more rename registers. If register renaming doubles the cost and 2 way SMT doubles it again then this is 4 times the cost. |
But you have to decide: better performances -> more rename registers -> increased file register.
There's no free lunch.
Quote:
Quote:
| Because it's very likely that they increased the number of ports in the register file to accomodate it. |
I'm not so sure adding more register ports to the Apollo core for AMMX was necessary. |
How can you deal with multiple reads and writes per clock cycle? The only way is by having multiple ports.
Quote:
Quote:
And the core offers 16 x 64-bit address registers + 32 x 64-bit data/FPU/SIMD registers (the register file is the same), multiplied by two since they have implemented an Hyperthreading-like technology (two hardware threads running in parallel).
Do you consider the Apollo core "too fat" for your goal? It's already doing well at the performance level (putting aside the weird ISA decisions). |
I think the Apollo core unnecessarily fattens up the cores with little gain. Performance is good for a low clocked in order core but I doubt much software is effectively using the extra banked registers. I think a compiler would have trouble using the additional banked registers and this would significantly increase the difficulty of compiler support. |
Same opinion. And I'd have rather used the transistors/LU for implementing an OoO design, if the goal was about best performances. An OoO 68K would be of much, much more general use (e.g.: all software could have benefited).
Quote:
Quote:
But the point is that if you want to increase the SIMD register sizes then you're forced to do the same with the data registers, if you use a common register file for both. |
The data registers would not be increased beyond 64 bit width and lightweight SIMD support would be available for integer instructions. Wider SIMD integer support could be added to the fp SIMD unit too as it appears to be very cheap. |
Isn't it more natural to just extended the FPU registers if/when needed (e.g.: adding 128-bit support)?
Quote:
| It is possible to use register pairs as the 88110 CPU used 2 32 bit registers to do 64 bit SIMD (Apollo core could use 2 64 bit wide registers to do 128 bit SIMD operations). Mitch Alsup said not making the 88k 64 bit from the start was the biggest design mistake and this would have allowed 64 bit SIMD without using register pairs. |
Indeed. Using registers pairs looks like a patch.
Quote:
Quote:
A 128-bit SIMD unit is very common, and considered a "minimum" requirement nowadays (with 256-bit sizes quickly becoming the mainstream: see AVX and the link provided by Hammer. Which makes sense, because Sony's and Microsoft's console are using AVX from long time now).
Do you like to have 128-bit data registers, and wasting their space when used only as data registers? |
Hammer's Intel documentation diagram also shows integer datatype support dropped for wider 256 bit AVX. |
That's only because AVX was the first 256-bit ISA design. With AVX2 Intel filled the gap and extended (almost) all SSE/AVX instructions to 256-bit:
https://software.intel.com/content/www/us/en/develop/blogs/haswell-new-instruction-descriptions-now-available.html
AVX2 - Integer data types expanded to 256-bit SIMD
Intel did the same with AVX-512, extending the data types to the new 512-bit registers.
Quote:
Quote:
And, as I said before, it's mostly due to the legacy burden. An ISA with a clean design can do the same things without being so fat.
Just to give an example, on my ISA the ADD single SIMD instruction maps all equivalent ADDs from all IA-32/x86-64 SIMDs:
VADDPD, VADDPS, VADDSD, VADDSS, VPADDB, VPADDW, VPADDD, VPADDQ, ADDPD, ADDPS, ADDSD, ADDSS, PADDB, PADDW, PADDD, PADDQ
That's because the ISA is fully orthogonal. |
x86-64 has all the performance enhancements and all the baggage. It would be nice to transition to a cleaner design but I don't think I would base it on x86-64. |
Why not x86-64? I think that the main problem here is that we see (yes, me too ) as a bad ISA per se, but a cleaner design derived/inspired from it doesn't necessarily mean that it should look bad/weird.
With my ISA I can do something like that:
ADD.W! [GS:(RBX + RDX * 4 + 1234).L]$, B31.Z
Adding a zero-extend byte from register #31 (B31.Z. B -> take only the low byte of the register R31. .Z -> zero extended to destination size, which is 16-bit) to the word (.W -> 16-bit) located in memory at the address defined by (RBX + RDX * 4 + 1234), cutting the calculated 64-bit address to 32-bit (.L), using the Thread Local Storage (GS:) to reference the memory pool for the specific thread, without loading the data on cache ($ -> Non-Temporal hint), and without affecting the flags (! suppresses the registers flags update).
If you don't like x86's register names you can use either (R3 + R2 * 4 + 1234) or (Q3 + Q2 * 4 + 1234) (I use Q for 64-bit integer data types). Preferred is the R register name, because it automatically means L -> 32-bit in 32-bit mode execution and Q -> 64-bit in 64-bit mode execution.
And if you like the pre/post-indexed addressing modes, you can use all of them (yes, all 4 combinations allowed) as well. For example:
ADD.L +[R0],[R1]-
or, using bigger offsets for the pre-post increments:
ADD.L +1234567890[R0],[R1]-987654321
I still have to decide for a better, more human-readable, syntax in this case, but I think that you've got the point, anyway.
And, of course, no prefixes at all, while still keeping all functionalities (the above GS: isn't a real prefix, but just a flag in the instruction. Which, of course, is fatter than the usual ADD, because of the requested extra features).
Isn't it "sexy"? Or do you still have concerns (which ones, in case)?
Quote:
Quote:
| Fair enough. But from what I see the risk is to have a too much castrated and/or embedded-oriented ISA. So, not a more general purpose one. |
In my opinion, the bigger problem has been core designs which have been cheapened too much for embedded. Some of this is due to ISAs which were too robust and didn't allow small enough designs to be competitive in PPA and price. |
Well, the thing IMO is that too small cores have too many restrictions.
And, looking at the today's processing processes, we have cores with a lot of transistors packed in very small areas. The above Silverthorne die was measuring 3.1 mm x 7.8 mm in a very old 45nm process, and was already packing a lot of stuff.
Do we want to go for cores in below 1mm^2 area? What's the goal? |
| | Status: Offline |
| | cdimauro
| |
Re: Amiga SIMD unit
Posted on 8-Nov-2020 6:21:18
| | [ #213 ] |
| |
|
Elite Member
|
Joined: 29-Oct-2012
Posts: 3650
From: Germany | | |
|
| @matthey: due to the our discussions I've almost completely redesigning my ISA, and changed something like 80-90% of the opcodes structure, with the goal to have a much cleaner architecture, reducing as much as possible x86/x64's legacies. A more "native" design, in short.
For this reason I've completely dropped the hardware support for the so called "high" registers. This will be entirely emulated by software, adding from one to three additional instructions.
I've also totally dropped the possibility to "cut" the generated address (the .L used in the memory field, in the above most complex example) from 64 to 32 and from 32 to 16-bit, which used a prefix on x86/x64.
I expect a small drop in the code density for the missing high registers support, since they are still used in the code. No drop in code density is expected for the address cut feature (I never saw it).
I've differently reused the 2-3 more free bits from the reduced SIMD registers (from 64 to 32). Instead of adding more space for opcodes or features, I've used them for having a simpler opcode structure (almost completely reworked), which is now easier to decode (less instructions formats used), and should also give some (small, I think) increase in the code density.
Unfortunately I've little space for quaternary SIMD instructions using an 8-bit immediate (e.g.: opcode V1, V2, V3/Mem, imm8), but it's enough for mapping the current instructions and there are a few instructions which can be added.
I've plenty of space (but much less than what I had previously) for all other SIMD opcodes, so no problem here for the future.
Similarly I've also reworked a lot the "GP" instructions, removing some legacy, better grouping & reducing the instructions formats, and freed some bits here as well, which allowed to add a much more useful MOV V1,V2 instruction (10 bits are used only for this: a big piece of the 16-bit "cake").
I've completely used-up the 16-bit opcode space, which is good (I can sleep the night without thinking on how to use it) and bad (no free slots available) as well. So, only 32+ opcode structures are available from now on.
I expect some good increase in the code density due to those changes, especially from the MOV.Size Mem,Mem instruction, which is much more compact for a common scenario (MOV.Size [Base1 + short offset],[Base2 + short offset]).
Unfortunately the new ISA is a little bit less orthogonal/symmetric. This is why I've another version to work on (after that I finish the massive amount of changes of the new one) to remove some other legacy stuff and make some space to make the architecture more orthogonal and "native".
On this version I'll drop the more general [Base + Index * Scaling Factor + Offset] addressing mode, leaving only [Base + Index * Data Size + Offset]. So, the scaling factor will be taken only from the instruction's data size.
The problem is that currently I've not enough space for encoding any of the 32 GP registers for both Base and Index. It'll be possible by reusing the 2 bits from the SF.
I've to say that I've a big space for the addressing modes (I've around 20 of them), but the EA/NewModRM has its limits as well, and this is The One.
I expect a consistent drop from the code density due to this decision, but it should be balanced from the code density gain coming from the new ISA (the one which I'm working on). Maybe some more gain will come from some other addressing modes rework (the next ISA will be mostly focused of addressing modes).
However the final goal is still preserved: 100% assembly compatibility with x86/x64.
End of the report. Now I "only" have to change my Python script to implement all those changes and generate the new statistics, to see real-world numbers.
In the last two days I've created a couple of python scripts for the driver (which disassembles in parallel all binaries, collecting and storing the statistics) and the statistics tool (which generates an Excel sheet with nice tables to check the average instructions length and the number of executed instructions). Now checking the impact of the changes is a piece of cake: just run the script, and it'll automatically open Excel with the report at the end. |
| | Status: Offline |
| | Hammer
| |
Re: Amiga SIMD unit
Posted on 31-Jan-2021 2:32:23
| | [ #214 ] |
| |
|
Elite Member
|
Joined: 9-Mar-2003
Posts: 5315
From: Australia | | |
|
| @cdimauro
Quote:
But it's not used. x86 and x64 are the most commonly used terms for IA-32 and x86-64.
|
My X86-32 (for i386/i486/i586/i686) usage reflects 16bit X86 instruction set is not working within the x86-64 mode.
X86 usage is true for 32-bit X86 Windows since it supports both 16-bit and 32-bit X86 instruction set.
I don't use IA-32 since it's vendor-specific and it's trademarked by Intel Corp i.e. my political reasons.
Quote:
cdimauro wrote:
FYI, any x86/x64 CPU vendor which supports AVX/-2 has the full AVX-256 hardware support. Included AMD's Jaguar.
|
Jaguar has a performance penalty for 256-bit payload AVX code and does NOT natively support the AVX 256 bit wide hardware.
https://www.3dcenter.org/dateien/abbildungen/AMD-Jaguar-Presentation-Slide09.jpg
AMD officially claims Jaguar has "128-bit native hardware". You're not AMD.
Since the Jaguar core only has 128-bit vector unit, the 256-bit payload AVX instruction set is basically useless.
AVX 256 bit serves as a forward compatibility front end for Jaguar.
Quote:
This was solely for selecting the data type, as you can see from the picture's description.
You'll find similar names in the performance monitoring registers, for the same reasons (to measure which data type was used by the instructions).
But you'll NOT find any AVX-128 or AVX-256 when talking about the ISA, as also your link clearly shows (the only occurrence of the AVX-128 term is in the data type selection).
|
Wrong, AVX-128 compiler switch is available on GCC.
"-mprefer-avx128
This option instructs GCC to use 128-bit AVX instructions instead of 256-bit AVX instructions in the auto-vectorizer."
Jaguar dominated game development between year 2013 to 2019 i.e. Xbox One and PS4
Data width and its performance are related to corresponding native hardware support.
Last edited by Hammer on 31-Jan-2021 at 03:05 AM.
Last edited by Hammer on 31-Jan-2021 at 03:04 AM.
Last edited by Hammer on 31-Jan-2021 at 02:40 AM.
Last edited by Hammer on 31-Jan-2021 at 02:37 AM.
_________________
Ryzen 9 7900X, DDR5-6000 64 GB RAM, GeForce RTX 4080 16 GB
Amiga 1200 (Rev 1D1, KS 3.2, PiStorm32lite/RPi 4B 4GB/Emu68)
Amiga 500 (Rev 6A, KS 3.2, PiStorm/RPi 3a/Emu68) |
| | Status: Offline |
| | cdimauro
| |
Re: Amiga SIMD unit
Posted on 31-Jan-2021 7:08:50
| | [ #215 ] |
| |
|
Elite Member
|
Joined: 29-Oct-2012
Posts: 3650
From: Germany | | |
|
| @Hammer Quote:
Hammer wrote:
@cdimauro Quote:
But it's not used. x86 and x64 are the most commonly used terms for IA-32 and x86-64. |
My X86-32 (for i386/i486/i586/i686) usage reflects 16bit X86 instruction set is not working within the x86-64 mode.
X86 usage is true for 32-bit X86 Windows since it supports both 16-bit and 32-bit X86 instruction set. |
x86, x86-64, IA-32, AMD64, etc., are just names / labels for the ISA, and not the execution modes.
The execution modes are called: real mode (8086 ISA), virtual 8086 mode (8086 ISA, executed in a 32-bit protected mode o.s.), 16-bit protected mode (80286 ISA), 32-bit protected mode (80386+ ISA), Long Mode (x86-64 ISA).
A processor in 32-bit protected mode can still execute 16-bit protected mode code (via 16-bit segments/gates), and real mode code (via 8086 virtual machine mode).
A processor in Long Mode can still execute 32-bit protected mode code, but not 16-bit code (protected, real, virtual).
Quote:
| I don't use IA-32 since it's vendor-specific and it's trademarked by Intel Corp i.e. my political reasons. |
Same for me regarding AMD64.
As I already stated, I prefer x86 and x64, because they are the wide terms used nowadays, and they are also vendor-neutral. So, it's a win-win.
Quote:
Quote:
cdimauro wrote:
FYI, any x86/x64 CPU vendor which supports AVX/-2 has the full AVX-256 hardware support. Included AMD's Jaguar.
|
Jaguar has a performance penalty for 256-bit payload AVX code and does NOT natively support the AVX 256 bit wide hardware.
https://www.3dcenter.org/dateien/abbildungen/AMD-Jaguar-Presentation-Slide09.jpg
AMD officially claims Jaguar has "128-bit native hardware". You're not AMD. |
That's only the hardware implementation, as I've already said. Jaguar is implementing the AVX/-2 ISA internally using 128-bit execution units instead of 256-bit ones, to save costs. Nevertheless, it can execute ANY AVX/-2 instruction, because what matters is the ISA, at the very end.
Intel introduced the SSE SIMD extension with the Pentium-III, and did the same: the SSE ISA was/is 128-bit, but the P3 internal implementation was 64-bit.
Quote:
Since the Jaguar core only has 128-bit vector unit, the 256-bit payload AVX instruction set is basically useless.
AVX 256 bit serves as a forward compatibility front end for Jaguar. |
Then I assume that you should have exactly the same opinion about AMD's Ryzen processors, which 'til Zen3 internally implemented the AVX/-2 SIMD as 128-bit instead of 256-bit.
Those processors had a performance penalty compared to Intel's ones, for that reason.
But nobody complained against AMD saying that its "256-bit payload AVX instruction set is basically useless" neither that "AVX 256 bit serves as a forward compatibility front end for" Ryzen.
Zen3 has, NOW, a 256-bit AVX/-2 implementation, but people hasn't waited for it, and bought the previous Ryzen processors as well...
Quote:
Quote:
This was solely for selecting the data type, as you can see from the picture's description.
You'll find similar names in the performance monitoring registers, for the same reasons (to measure which data type was used by the instructions).
But you'll NOT find any AVX-128 or AVX-256 when talking about the ISA, as also your link clearly shows (the only occurrence of the AVX-128 term is in the data type selection). |
Wrong, AVX-128 compiler switch is available on GCC.
"-mprefer-avx128
This option instructs GCC to use 128-bit AVX instructions instead of 256-bit AVX instructions in the auto-vectorizer." |
Again, repeating the same things will not make them true.
You continue to report a single compiler switch as a "proof" that a 128-bit AVX ISA existed, which is clearly and plainly wrong, since what it matters here is the ISA definition, which is reported in the vendors' Architecture Manuals.
Quote:
Jaguar dominated game development between year 2013 to 2019 i.e. Xbox One and PS4
Data width and its performance are related to corresponding native hardware support. |
Nothing to say about that, but it's a DIFFERENT thing, eh!
I always talked about the ISA. So, NOT about compiler switches neither about internal ISA implementations (which are called micro-architectures). |
| | Status: Offline |
| | cdimauro
| |
Re: Amiga SIMD unit
Posted on 31-Jan-2021 7:39:49
| | [ #216 ] |
| |
|
Elite Member
|
Joined: 29-Oct-2012
Posts: 3650
From: Germany | | |
|
| Now a few words about my ISA, which I've completed (the last version: the 8th) at the very end of the last year.
I've completely removed the "high" registers from the ISA, adding only a couple of quick and simple instructions to move the "high" part of a register to a fixed register, and viceversa. This just to make it simple and cost-effective to still support them, albeit entirely in software (e.g.: if an x86/x64 instruction is using one or two "high" registers, proper special move instructions will be added before and after the native NEX64T instruction).
I've also completely removed the support to the "address flag / prefix" (used to "cut" 64-bit addresses to 32-bit, or 32-bit addresses to 16-bit). This will be emulated adding an extra instruction.
And I've completely removed the support to the selectable scaling factor in the [Base + Index * Scale + Offset] addressing mode. Now the native ISA supports only [Base + Index * Size + Offset], where Size = the size of the data being loaded or stored.
I've added a couple of instructions to emulate the old [Base + Index * Scale + Offset] or [Index * Scale + Offset] (this was also possible on x86/x64) addressing modes, by computing [Base + Index * Scale] or [Index * Scale] to a fixed register. So, this instruction will be added before the native one, and the native one will then use the calculated value using the fixed register as the base register.
All those changes reduced the code density, and increased the number of executed instructions. Which was expected. Fortunately it wasn't a big loss: 32 and 64-bit code density is still better than x86 and x64, and as well the total number of executed instructions.
But the important thing is the this legacy stuff is removed (albeit I had to add 3 instructions to make it easy the port of x86/x64 code), and the ISA now iss much, much simpler and better.
All of this allowed me to tweak & rethink again the ISA, because it freed some bits in some strategical places, and I discovered other ways to better use them in a much more efficient way.
I've also removed some "quick" instructions as well, and now the ISA has several other 16-bit opcodes which are free, and that can be used in the future.
So, it was a great think & rework, which required a huge effort, but it deserved looking at the results.
This month I've decided to look around for the next step: adding support to my ISA to an existing compiler.
I've found an interesting series of posts about a novel embedded ISA, 832, which was developed by an amigan, which reported on EAB the link to his blog.
The most interesting blog post is this one: http://retroramblings.net/?p=1414
And it's interesting because it makes some measures about the code density, comparing several architectures. It's a nice read, which I recommend, albeit it's still limited (only one application was used for the code density measures. But NOT a trival application: code generated is several tens of KBs!).
After that I've started looking at VBCC, which was really a nice candidate: one of the simplest multi-platform C compilers. In fact, the 68K backend (which is the best and supported one) is only 174KB, for around 5.5K lines of code. Which is NOTHING, compared to LLVM or even GCC!
Unfortunately VBCC does a very poor job at optimizing the code. I just checked with simple Fibonacci and factorial examples, and the generated assembly code is really really bad, even using the best options to optimize for speed.
So, I decided to don't consider it anymore, and look at other directions.
LLVM is clearly the best/better candidate (I've took a look at generated code for several architectures that it supports), but definitely there's an enormous work to be done... |
| | Status: Offline |
| | Hammer
| |
Re: Amiga SIMD unit
Posted on 31-Jan-2021 12:10:13
| | [ #217 ] |
| |
|
Elite Member
|
Joined: 9-Mar-2003
Posts: 5315
From: Australia | | |
|
| @cdimauro
https://fossies.org/linux/fftw/simd-support/avx-128-fma.c
From the Linux camp, this C program checks for AVX-128 FMA hardware.
Intel's marketing push for AVX-128 against legacy 128bit SSE instructions from year 2012
https://www.naic.edu/~phil/software/intel/319433-014.pdf
Quoting from Intel's Intel® Architecture Instruction Set Extensions Programming Reference (doc number: 319433-014, AUGUST 2012)
2.8.2 Using AVX 128-bit Instructions Instead of Legacy SSE instructions
Applications using AVX and FMA should migrate legacy 128-bit SIMD instructions to their 128-bit AVX equivalents.
AVX supplies the full complement of 128-bit SIMD instructions except for AES and PCLMULQDQ.
For desktop PCs and servers, I didn't buy Zen 1 (four-way 128-bit vector units) since it's a backward step from Intel Haswell's native 256 bit AVX 2 hardware, but the year 2013 to 2019 was dominated by AMD Jaguar based game consoles with AVX-128 hardware.
Zen 1 (March 2017) was quickly replaced by Zen 2 (August 2019) and game consoles based on Zen 2 have hardware 256-bit vector units and these game consoles are released in the year 2020.
The year 1999's Pentium III's 128 bit SSE with 64-bit vector hardware prepared the X86 software industry for the native 128 bit SSE hardware equipped Core 2's released in 2006.
AMD K8 already has 128-bit SSE FADD hardware support from late 2003, but has 64bit SSE FMUL hardware. K10 has 128-bit SSE FADD and 128 bit SSE FMUL native hardware support and it was supposed to be released in 2006 or 2007 time period but the TLB bug delayed its release until 2008.
AMD K10 still has three X86 instruction issue per cycle limitation which is inferior to Intel Core 2's four X86 instruction issue per cycle. In terms of IPC, Bulldozer is a step backwards from K10.
Motorola's 7400 (August 1999) Altivec has native 128-bit vector hardware from the start, but couldn't increase clock speed and memory bandwidth to match AMD's K7 Athlon which has the X86 performance leadership. AMD K8 competed against IBM PowerPC 970. AMD K8 has the X86 performance leadership until Intel Core 2 (2006).
Hardware 128-bit vector math was important when game consoles such as Xbox 360 PPE X3 (2005) and PS3 CELL (November 2006) was released. The year 2006 also the launch year for GeForce 8800 CUDA GpGPU.
My argument's context is the gaming industry which is the major driver for mass-produced vector math processors.
-------------
For Zen 1's 128bit vector math advantage and disadvantage when compared to Intel Haswell.
Let us compare the execution units of AMD's Ryzen (Zen 1) with Intel Haswell processors.
AMD has four 128-bit units for floating-point and vector operations. Two of these can do addition and two can do multiplication. Intel has two 256-bit units, both of which can do addition as well as multiplication. This means that floating-point code with scalars or vectors of up to 128 bits will execute on the AMD processor at a maximum rate of four instructions per clock (two additions and two multiplications), while the Intel processor can do only two. With 256-bit vectors, AMD and Intel can both do two instructions per clock. Intel beats AMD on 256-bit fused multiply-and-add instructions, where AMD can do one while Intel can do two per clock.
https://www.agner.org/optimize/blog/read.php?i=838
Ryzen optimization and AVX-128 vs AVX 256 usage discussion thread.
-------------
For Jaguar
https://www.realworldtech.com/jaguar/4/
To save power, the Jaguar physical register file adopts several related techniques to aggressively free registers for use. The first technique is known as the zero-bit, which indicates in the rename table that a register only contains zeroes (e.g., for the upper half of a 256-bit YMM register, or a register that was cleared using XOR) and does not need a physical register. This approach was extended to reclaim 8 temporary FP microcode registers when the microcode is not active
---
On Jaguar, AVX 128 conserves physical registers and part of reducing energy consumption tactics.
My argument is to think about hardware implementation, not just the visible instruction set.
Last edited by Hammer on 31-Jan-2021 at 01:19 PM.
Last edited by Hammer on 31-Jan-2021 at 01:13 PM.
Last edited by Hammer on 31-Jan-2021 at 01:11 PM.
Last edited by Hammer on 31-Jan-2021 at 12:46 PM.
Last edited by Hammer on 31-Jan-2021 at 12:40 PM.
Last edited by Hammer on 31-Jan-2021 at 12:36 PM.
Last edited by Hammer on 31-Jan-2021 at 12:32 PM.
Last edited by Hammer on 31-Jan-2021 at 12:11 PM.
Last edited by Hammer on 31-Jan-2021 at 12:10 PM.
_________________
Ryzen 9 7900X, DDR5-6000 64 GB RAM, GeForce RTX 4080 16 GB
Amiga 1200 (Rev 1D1, KS 3.2, PiStorm32lite/RPi 4B 4GB/Emu68)
Amiga 500 (Rev 6A, KS 3.2, PiStorm/RPi 3a/Emu68) |
| | Status: Offline |
| | cdimauro
| |
Re: Amiga SIMD unit
Posted on 31-Jan-2021 14:07:58
| | [ #218 ] |
| |
|
Elite Member
|
Joined: 29-Oct-2012
Posts: 3650
From: Germany | | |
|
| @Hammer Quote:
The Linux camp is clearly wrong, since this patch is just checking if the processor is an AMD one, and if it supports the FMA4 instructions:
/* OK, this is an AMD CPU. Check if we support FMA4 */
BTW, if FMA4 is supported,then it's always for both 128 and 256-bit instructions.
Quote:
Intel's marketing push for AVX-128 against legacy 128bit SSE instructions from year 2012
https://www.naic.edu/~phil/software/intel/319433-014.pdf
Quoting from Intel's Intel® Architecture Instruction Set Extensions Programming Reference (doc number: 319433-014, AUGUST 2012)
2.8.2 Using AVX 128-bit Instructions Instead of Legacy SSE instructions
Applications using AVX and FMA should migrate legacy 128-bit SIMD instructions to their 128-bit AVX equivalents.
AVX supplies the full complement of 128-bit SIMD instructions except for AES and PCLMULQDQ.
|
This isn't Intel's marketing, but clearly a guideline to developers for helping them converting their code from the SSE to the AVX, starting by using 128-bit AVX instructions.
In fact, it's talking about 128-bit (AVX) instructions, and not about a non-existent AVX-128.
Frome the beginning of the same document:
INTEL® ADVANCED VECTOR EXTENSIONS ARCHITECTURE OVERVIEW
Intel AVX has many similarities to the SSE and double-precision floating-point portions of SSE2. However, Intel
AVX introduces the following architectural enhancements:
Support for 256-bit wide vectors and SIMD register set.
[...]
Intel AVX introduces support for 256-bit wide SIMD registers
[...]
Efficient encoding of instruction syntax operating on 128-bit and 256-bit register sets.
and here we're talking about AVX, so NOT even AVX2.
This clearly shows that AVX introduced support to BOTH 128 and 256 bit instructions, on a 256-bit vector registers file.
You can continue to spend time searching around, but it'll always be a waste of time, because you cannot change the reality: AVX is a 256-bit SIMD extension.
Quote:
| For desktop PCs and servers, I didn't buy Zen 1 (four-way 128-bit vector units) since it's a backward step from Intel Haswell's native 256 bit AVX 2 hardware, |
Fine and legit: your choice. But then AMD made a mistake releasing processors with a 128-bit implementation: do you agree?
Quote:
| but the year 2013 to 2019 was dominated by AMD Jaguar based game consoles with AVX-128 hardware. |
As already proved (several times), there's no AVX-128: this ISA doesn't exist.
You can only say that Jaguar has a 128-bit implementation.
Quote:
| Zen 1 (March 2017) was quickly replaced by Zen 2 (August 2019) and game consoles based on Zen 2 have hardware 256-bit vector units and these game consoles are released in the year 2020. |
Correct, and you're right: it was Zen2 that had a 256-bit implementation.
AMD made a mess with the Zen vs Ryzen names, which only caused confusion (now we have Ryzen 5000 which is... Zen3!).
Quote:
| [...]My argument's context is the gaming industry which is the major driver for mass-produced vector math processors. |
On the consumer side, yes. But it was important to servers / workstations / HPC as well, which were also important markets for Intel.
Quote:
-------------
For Zen 1's 128bit vector math advantage and disadvantage when compared to Intel Haswell.
Let us compare the execution units of AMD's Ryzen (Zen 1) with Intel Haswell processors.
AMD has four 128-bit units for floating-point and vector operations. Two of these can do addition and two can do multiplication. Intel has two 256-bit units, both of which can do addition as well as multiplication. This means that floating-point code with scalars or vectors of up to 128 bits will execute on the AMD processor at a maximum rate of four instructions per clock (two additions and two multiplications), while the Intel processor can do only two. With 256-bit vectors, AMD and Intel can both do two instructions per clock. Intel beats AMD on 256-bit fused multiply-and-add instructions, where AMD can do one while Intel can do two per clock. |
Correction: Intel has 3 256-bit SIMD units.
Quote:
https://www.agner.org/optimize/blog/read.php?i=838
Ryzen optimization and AVX-128 vs AVX 256 usage discussion thread. |
From your link:
256-bit vector instructions (AVX instructions)
Because AVX is a 256-bit SIMD ISA.
Quote:
-------------
For Jaguar
https://www.realworldtech.com/jaguar/4/
To save power, the Jaguar physical register file adopts several related techniques to aggressively free registers for use. The first technique is known as the zero-bit, which indicates in the rename table that a register only contains zeroes (e.g., for the upper half of a 256-bit YMM register, or a register that was cleared using XOR) and does not need a physical register. This approach was extended to reclaim 8 temporary FP microcode registers when the microcode is not active
---
On Jaguar, AVX 128 conserves physical registers and part of reducing energy consumption tactics.
My argument is to think about hardware implementation, not just the visible instruction set. |
I think about it, and that's why I always correctly speak about ISA and micro-architecture, which are two different things, albeit strictly related (of course).
AVX is a 256-bit ISA. And that's THE fact.
But you can have 128 or 256-bit micro-architectures (the ISA's implementation). And that's ANOTHER fact.
But a 128-bit AVX or an AVX-128 doesn't exist: this is a completely invented thing, which is against what's clearly reported on the vendor's Architecture manual.
And this is my argument. |
| | Status: Offline |
| | Hammer
| |
Re: Amiga SIMD unit
Posted on 17-Oct-2022 15:04:34
| | [ #219 ] |
| |
|
Elite Member
|
Joined: 9-Mar-2003
Posts: 5315
From: Australia | | |
|
| @cdimauro
Quote:
| Correction: Intel has 3 256-bit SIMD units. |
Correction, Intel Haswell has three 256-bit integer vector units.
https://en.wikichip.org/wiki/intel/microarchitectures/haswell_(client)
Intel Haswell has two FPU ports
Port 0 has FP FMA , FP MUL, FP DIV
Port 1 has FP ADD, FP FMA, FP MUL
https://en.wikichip.org/wiki/amd/microarchitectures/zen
Again, AMD Zen 1 has four 128-bit units for floating-point vector operations i.e. FADD, FADD, FMA/FMUL, and FMA/FMUL. Floating-point vector units can execute vector integers.
My argument is floating point vector units.Last edited by Hammer on 17-Oct-2022 at 03:43 PM.
Last edited by Hammer on 17-Oct-2022 at 03:07 PM.
_________________
Ryzen 9 7900X, DDR5-6000 64 GB RAM, GeForce RTX 4080 16 GB
Amiga 1200 (Rev 1D1, KS 3.2, PiStorm32lite/RPi 4B 4GB/Emu68)
Amiga 500 (Rev 6A, KS 3.2, PiStorm/RPi 3a/Emu68) |
| | Status: Offline |
| | Hammer
| |
Re: Amiga SIMD unit
Posted on 17-Oct-2022 15:19:18
| | [ #220 ] |
| |
|
Elite Member
|
Joined: 9-Mar-2003
Posts: 5315
From: Australia | | |
|
| @cdimauro
Quote:
In fact, it's talking about 128-bit (AVX) instructions, and not about a non-existent AVX-128.
Frome the beginning of the same document:
INTEL® ADVANCED VECTOR EXTENSIONS ARCHITECTURE OVERVIEW
Intel AVX has many similarities to the SSE and double-precision floating-point portions of SSE2. However, Intel
AVX introduces the following architectural enhancements:
Support for 256-bit wide vectors and SIMD register set.
[...]
Intel AVX introduces support for 256-bit wide SIMD registers
[...]
Efficient encoding of instruction syntax operating on 128-bit and 256-bit register sets.
and here we're talking about AVX, so NOT even AVX2.
This clearly shows that AVX introduced support to BOTH 128 and 256 bit instructions, on a 256-bit vector registers file.
You can continue to spend time searching around, but it'll always be a waste of time, because you cannot change the reality: AVX is a 256-bit SIMD extension.
|
FACT: AVX-128 exists as a hardware implementation e.g. AMD Jaguar and it's the lowest common denominator for Xbox One and PS4 game consoles.
Jaguar's AVX-256 instruction set support is for forward compatibility with Zen 2-based game consoles with actual hardware AVX-256 implementation. Zen 2 has hardware AVX2-256 implementation.
For Intel Gracemont E-cores
https://en.wikipedia.org/wiki/Gracemont_(microarchitecture)#/media/File:GracemontRevised.png
Like AMD Jaguar, Intel Gracemont's AVX hardware implementation is 128-bit wide.
Intel Gracemont's AVX2-256 instruction set support is with 128-bit AVX hardware implementation.
https://twitter.com/iancutress/status/1327358373373898752?lang=en
Cinebench R23 only uses the AVX-128 subset from AVX-512.
AVX-128 hardware implementation and AVX-128 subset usage are real.
Cinebench R23 doesn't properly benchmark AVX-256/AVX2-256 and AVX-512 usage at their full width.
Ian Cutress's 3D Particle Movement v2.1 properly uses AVX-512 at its full width. https://www.anandtech.com/show/17585/amd-zen-4-ryzen-9-7950x-and-ryzen-5-7600x-review-retaking-the-high-end/13
Last edited by Hammer on 17-Oct-2022 at 03:42 PM.
Last edited by Hammer on 17-Oct-2022 at 03:41 PM.
Last edited by Hammer on 17-Oct-2022 at 03:39 PM.
Last edited by Hammer on 17-Oct-2022 at 03:37 PM.
Last edited by Hammer on 17-Oct-2022 at 03:22 PM.
_________________
Ryzen 9 7900X, DDR5-6000 64 GB RAM, GeForce RTX 4080 16 GB
Amiga 1200 (Rev 1D1, KS 3.2, PiStorm32lite/RPi 4B 4GB/Emu68)
Amiga 500 (Rev 6A, KS 3.2, PiStorm/RPi 3a/Emu68) |
| | Status: Offline |
| |
|
|
|
[ home ][ about us ][ privacy ]
[ forums ][ classifieds ]
[ links ][ news archive ]
[ link to us ][ user account ]
|
